moss命令、正则表达式与简单的文本分析
最近笔者在STATALIST上面看到别人问的一个问题——如何从一堆作者的名字中提取出姓氏。

虽然我们用“[A-Z][a-z]+”
的正则表达式可以匹配到姓氏,但是由于每一条的姓氏数量不同,当我们要把每一个姓氏都提取出来时,要么用一个较为复杂的正则表达式来匹配提取,要么用每次
将第一个提取出来后都用ustrregexrf()函数将第一个替换为空,反复提取。这两个都是比较麻烦的方法。有人在下面回复了一个命令,不仅可以快速
解决这个问题,而且还在文本分析中可以有更广泛的运用。这个命令就是moss。
moss命令是一个外部命令,在使用前需要安装。比如上面这个例子,我们来进行简化一下,用其中五条,来具体演示moss命令的用法。
首先我们生成author变量,输入五条内容:
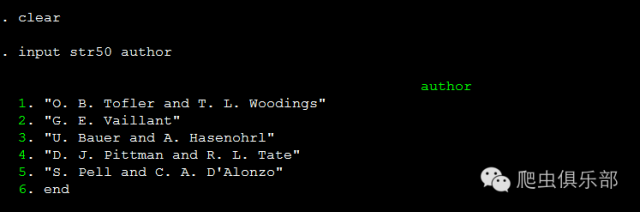
然后我们用moss命令和正则表达式来提取:
moss author, match("([A-Z][a-z]+)") regex

新生成的变量中,_count表示匹配到的子字符串的个数,_match1和_match2分别是我们匹配到提取出的子字符串,_pos1和_pos2分别是两个匹配到的子字符串的位置。我们可以通过prefix和suffix两个选项来修改生成的变量名,也可以通过max()选项来确定我们提取的数量。在这里需要注意的是,我们如果是用正则表达式来进行匹配和提取的话,正则表达式外面需要加上括号,并且加上regex这个选项。如果不用正则表达式的话,则只会生成匹配到的次数和每次匹配到的内容所在的位置这些变量,不会有匹配到的内容的变量生成。还是利用这个例子,我们直接用字符a来匹配,结果如下图所示:

我们在进行文本分析的时候经常会需要统计某个词出现的次数,用这个命令就可以完成。但在实际操作的过程中也会有一些需要注意的细节。举一个简单的例子,我们要查出“This is a cat”中单词“is”的数量,很显然只有一个。但是我们直接用“is”来匹配的话,就会出现问题。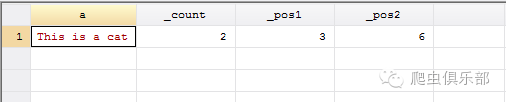
我们在这里一共匹配到了两个,原因是This中的is也被匹配到了。当文本内容非常多的时候,很容易受到各种干扰。我们当然可以在is前后都加上空格,防止This中的is被匹配到。
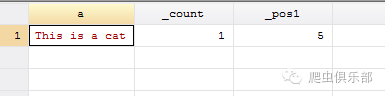
这样做确实只匹配到了一处,也就是is,但是我们看所在的位置时候,发现是从第5个字符开始,而不是is所在的第6个字符,原因就是我们在这里得到的其实是is前面空格所在的位置。如果我们也要防止这个问题,该怎么办呢?这里,我们就需要用正则表达式,而且必须用Stata14版本。Stata14中,新增了大量的unicode 字符串函数,对正则表达式的元字符也进行了大量的扩充,其对字符串处理的能力是Stata之前的所有版本所无法比拟的。在新添加的元字符中,有一个\b元 字符,它所匹配的就是单词的边界。比如“\bis\b”匹配到的就是is,用“\bcat”可以匹配到以cat开头的单词。用这个元字符,我们就可以解决 之前的问题。用到的命令为:
moss a, match("(\bis\b)") regex unicode
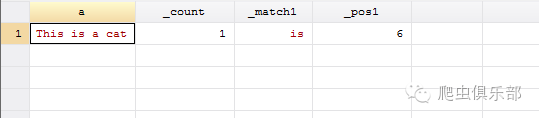
这里的unicode选项表示我们用Stata14中的字符串函数,使用了Stata14新增加的元字符,这个选项也只有在Stata14版本中才能使用。这样就完美解决了我们上述问题。
在我们以前的公众号上,有位师兄曾经写了一篇推文介绍了一些简单的文本分析方法,当时师兄用到的例子是从唐诗三百首中统计“故乡”出现的次数、出现故乡的诗的数量、出现故乡的诗是哪些。在推文中介绍的方法是使用subinstr()函数将所有的“故乡”替换成空,然后用之前的字符长度减去新的字符长度,除以“故乡”的字符长度,就可以得到故乡出现的次数。使用moss命令也可以完成这个任务,感兴趣的朋友可以自己尝试一下。
但是在做中文的文本分析时,最先要解决的问题就是分词。比如我们要找“果 然”这个词出现的次数,结果有句话是“我先吃水果然后再喝汽水”,这里的“果然”当然不是我们想要找的果然,这就对我们的结果产生了影响。只有把这句话像 英文一样把每个词都分开,变成“我 先 吃 水果 然后 再 喝 汽水”,才能避免这样的影响。因此,对中文的文本分析,要先注意做好分词,这样才能使我们的结果更准确。
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按二维码关注公众号

微信扫一扫
关注该公众号