小目标一个亿,先来找找你的“1”
亲爱的Stata小伙伴们,王健林“先定一个亿的小目标”的消息是不是刷爆了你的朋友圈?小编看了看自己的余额宝,决定先定一个能达到的小目标,比如先在stata的字符型变量中找到那个“1”。今天的推文我们就来讲一讲如何在包含数字的字符型变量中寻找你需要的数字。
不知道你们在数据处理的过程中,有木有发现这样的问题?比如,一个字符型变量num中包含有数字,我们想知道,另外一个数值型变量id是否也出现在num中?
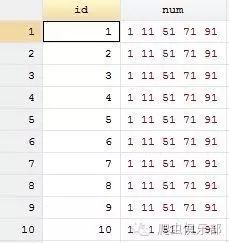
根据我们的思维,我们可以通过strpos()命令来进行查找,如果id中的数字出现于num中,strpos()可以直接定位到具体的位置。比如,当id=1时,1在num中则处于第6位(因为空格也算作一个字符)。当然,id作为数值型变量,我们得用string()来转换成字符型变量才可以运行:
clear
set obs 100
gen id = _n
gen num = "1 11 51 71 91"
gen match=1 if strpos(num, string(id))
list if match==1
但是根据如上的方法,你会发现,当id=1,id=11,id=51,id=71,id=91时,match值都为1,因为在1、11、51、71、91中都出现了数字1,但是我们想要得到的是,只当id=1时,match值为1。
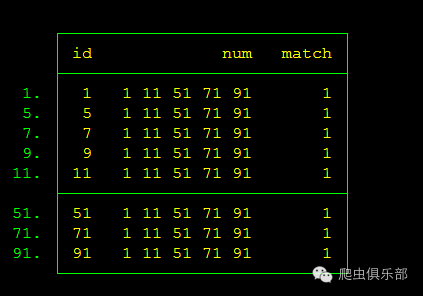
那么我们可以对程序进行修改:在循环语句中,word()函数对num中的数字进行提取,然后通过real()函数从字符型转换成数值型,并与id进行匹配判断:
clear
set obs 100
gen id = _n
gen num = "1 11 51 71 91"
gen match=0
quietly forval i = 1(1) `=wordcount(num)' {
replace match = 1 if real(word(num, `i')) == id
}
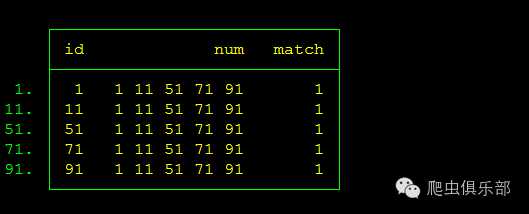
list if match==1
经过改头换面之后:
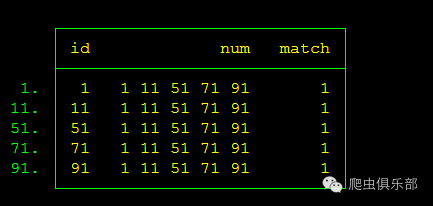
细心的小伙伴们可以发现,num变量中出现有空格,那么我们是不是可以通过split命令来对num进行处理呢?
clear
set obs 100
gen id = _n
gen num = "1 11 51 71 91"
gen match=0
split num, p(" ")
replace match = (string(id) == num1) + (string(id) == num2) + ///
(string(id) == num3) + (string(id) == num4) + ///
(string(id) == num5)
list id num match if match==1
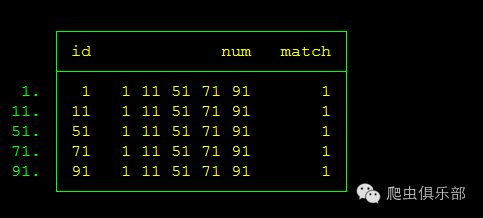
如果你觉得之前的split出来的变量数据过多的话,你也可以选择使用循环语句:
clear
set obs 100
gen id = _n
gen num = "1 11 51 71 91"
gen match = 0
split num, p(" ")
forvalues i = 1/`=r(nvars)' {
replace match = match + (string(id) == num`i')
}
list id num match if match==1
那么我们有没有其他的方法进行对程序进行优化呢?答案是有的,我们可以在程序1的基础上稍作修改:
clear
set obs 100
gen id = _n
gen num = "1 11 51 71 91"
gen match=0
replace match=1 if strpos(" "+num+" "," "+string(id)+" ")
list if match==1
那么得到的结果也如程序2的结果:
小贴士:不太熟悉相关的命令和函数功能的小伙伴可以看向这边
1、strpos(s1,s2):字符串s2在字符串s1中首次出现的位置
strpos("tooyoung","young") = 4
strpos("tooyoung","naive") = 0
2、string(n):将数值型变量n转换成字符型变量
real(s):将字符型变量s转换成数值型变量
3、word(s,n):返回字符串s中第n个字符
word(“excited”,2)=x
4、wordcount(s):字符串s中字符的数量(根据空格来区分)
wordcount(“hello hawaii”)=2
wordcount("苟利国家生死以,岂因祸福避趋之")=1
5、split:根据特定的分隔符,将字符串中的内容分隔出几个部分
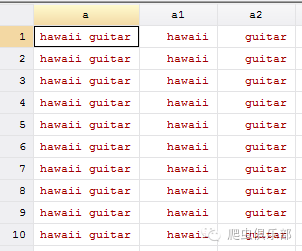
clear
set obs 10
gen a="hawaii guitar"
split a,parse(" ")
当然split中还有其他的option,比如generate,limt,destring,ignore,force等。还有想进一步深究的同学们,也可以继续尝试一下。小编用stata找到我的“1”啦,完成自己小目标的你们别忘了点赞和转发哟。
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按二维码关注公众号

微信扫一扫
关注该公众号