字符串函数、正则表达式与变量拆分
敲黑板,划重点啦~今天是第三十二个教师节,让我们先对所有在我们求学路上给予支持、帮助与鼓励的老师说声“教师节快乐,您辛苦了!”。
今天的推文我们来讲一讲字符串函数、正则表达式与变量拆分。我们在把数据导入stata中,有时会遇到本来应该作为几个分开的变量,在导入后都跑到了同一列的现象,这时候就需要把这个变量拆分成我们所需要的几个变量。我们都知道在stata中有一个拆分命令split,这个命令的格式为:
split strvar [if] [in] [, options]
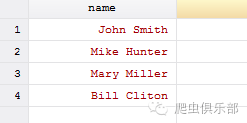
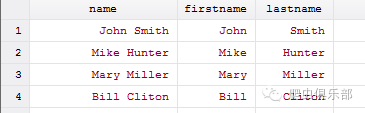
其中常用的options选项为parse(parse_strings),例如要把下图数据中的姓名拆分成firstname和lastname,则命令为:split name,p(“ ”),即以空格把name拆分,然后进行重命名,rename (name1 name2) (firstname lastname),即可得到我们想要的数据。
上述命令的使用前提是要有一个统一的分隔符号,例如逗号、空格、分号等特殊符号,那如果我们要拆分的数据中并没有统一的分隔符号时我们又该怎么办呢?在STATALIST上有人遇到下面这个问题:
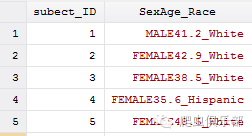
我们想把这个数据变成包含subject_ID、Sex、Age、Race四个变量的形式,所以需要把SexAge_Race这个变量拆分成Sex、Age、Race三个变量。Race这个变量很好拆分,可以用”_”作为拆分依据,但是Sex和Age两个变量之间是没有分隔符号的,那该如何拆分呢?我们将采用两种方法解决这个问题。
方法一:

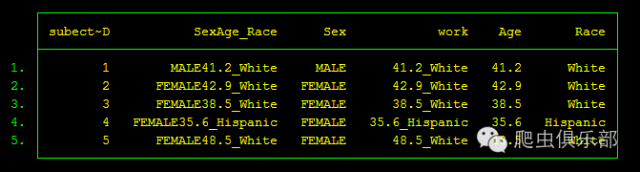
在这一方法中,我们使用了substr和subinstr这两个字符串的处理命令,substr使用格式为substr(s,n1,n2),表示把字符串s中从第n1个字符开始的n2个字符提取出来。所以第一行命令表示把SexAge_Race变量的前6个字符提取出来赋给变量Sex,这样FEMALE就被提取出来了,第二行命令表示把SexAge_Race变量的前4个字符提取出来,这样MALE就被赋给了Sex,所以Sex变量被成功提取出来。接着我们又使用了subinstr命令,这个命令的使用格式为subinstr(s1,s2,s3,n),表示把字符串s1中的n个子字符串“s2”用子字符串“s3”来替换,所以第三行命令表示把SexAge_RaceSex变量中Sex变量所表示的子字符串用""替代,即把全部FEMALE和MALE去掉,然后剩下的部分用split命令以”_”分开就可以了,最后重命名一下变量就得到了我们想要的数据。
方法二:
在方法二中,我们主要使用了ustrregexm和ustrregexs这两个字符串函数将正则表达式与字符串进行匹配以及字符串的提取与替换。
1、ustrregexm(s,re[,noc]):(u代表unicode,str代表string,即字符串,reg代表regular,ex代表expression,m代表match,即匹配)
“s”代表字符串,也可以是相应的变量,”re”代表正则表达式,如果字符串中有正则表达式匹配到的内容就赋值为1,否则赋值为0。noc这个部分可以填上一个数字,如果你定义了noc,并且是一个不为0的数字,那么在正则表达式和字符串匹配的时候是不区分大小写的。
2、ustrregexs(n):(s代表substring,即子字符串)
n为非负整数,代表ustrregexm(s,re)函数中第n个子表达式对应的子字符串。若n为0,则代表引号中所有表达式对应的子字符串。ustrregexs函数必须在ustrregexm函数运行之后才能运行,可用于提取子字符串。
除了这两个字符串函数,这里还涉及到正则表达式中的元字符,小编已经贴心地帮你们把正则表达式中的常用元字符整理出来啦:

所以,方法二的处理过程如下:
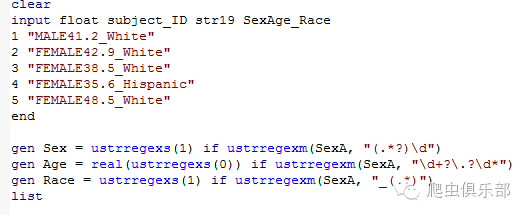
首先创建一个子表达式,其中”.”符号表示可以匹配任意字符,用*?表示懒惰匹配模式,\d匹配数字,也就是把最左端的数字前面所有的内容,提取出来并赋给变量Sex。同理,提取变量Age时,\d匹配数字,+表示把前面的字符或子表达式匹配几次或多次,同样使用懒惰模式,匹配到最近一个小数点,点后面的?表示匹配一次或零次,小数点可能不存在,所以后面的数字也是匹配任意次,提取出来之后用real函数把Age变成数值型变量。最后是Race变量,"_(.*)"表示匹配并提取_后面的所有内容。这样,我们就把数据变成我们想要的形式了。
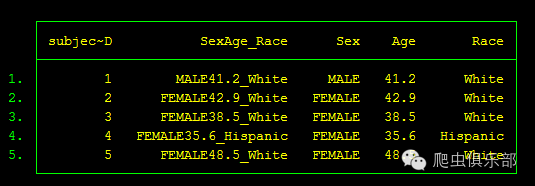
除此之外,还可以用一个正则表达式来进行提取:

我们这个正则表达式由三个子表达式构成,每个子表达式分别对应我们想要提取的三个变量,先用ustrregexm进行匹配后,再用ustrregexs分别把第一个,第二个,第三个变量提取出来,就得到我们要的三个变量。
在我们以前的公众号上,有位师兄写过几篇推文详细介绍字符串函数和正则表达式中的常用元字符,大家有兴趣可以去看一下。
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按二维码关注公众号

微信扫一扫
关注该公众号