【有问必答】用循环语句提高数据统计效率
在运用stata的你们不知道是否已经发现了它数据处理上的强大功能?反正小编用上stata之后,学习、工作效率up up~今天的推文是解答之前有朋友问到如何使用循环语句处理一份数据统计表。学会之后,再不用传统复杂的语句,保证你数据处理速度快的要上天。
我们以学生时间安排调查统计表为例,将学生一天的时间安排做一个重新排列。原始数据是学生在每个小时的区间内在1-10类活动中选一个主要的选项,没选的记为缺失值 . ,每个学生的数据是一个10×16矩阵。
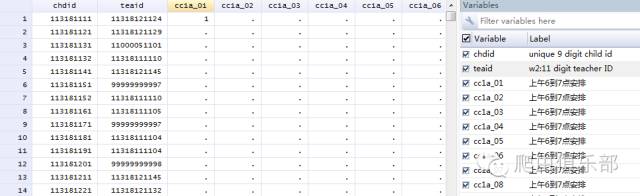
学生的数据在dta 文件格式如下图所示。每行为每个学生在每个小时选择活动的情况,其中chdid为学生的id,teaid为老师的id。如第一行第三列数值为1,表明id 为113181111的学生在上午6到7点安排上课;再比如,第二行第四列数值为 . ,表明id为113181121的学生在上午6到7点没有安排做家庭作业。
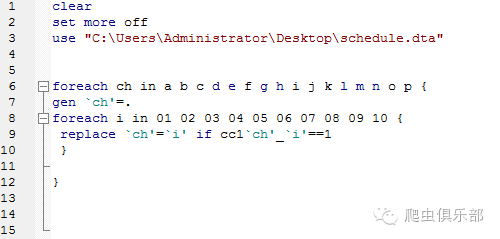
我们的想法是将其做成a-p的16个新变量,如果cc1a_08==1,那么新生成一个变量a=8;如果cc1a_05==1,替换a=5;如果cc1a_10==1,替换a=10,如cc1b_01==1,新生成第二个变量b=1,如果cc1b_05==2,替换b=2;如果cc1b_9==1,替换b=9……一直到cc1p_15……从而能够得出不同学生在不同时间的安排。
于是我们用嵌套循环的方式来实现我们的目的。程序如下图所示,其中a b c d e f g h i j k l m n o p 表示不同的时间段,01 02 03 04 05 06 07 08 09 10 表示不同的安排。首先对ch依次匹配a b c d e f g h i j k l m n o p,之后i 依次匹配01 02 03 04 05 06 07 08 09 10,条件为在该时间段是否安排了这个项目,即ccl`ch’_`i’是否等于1,如果安排,就输出该项目的编号,即i所对应的数值。
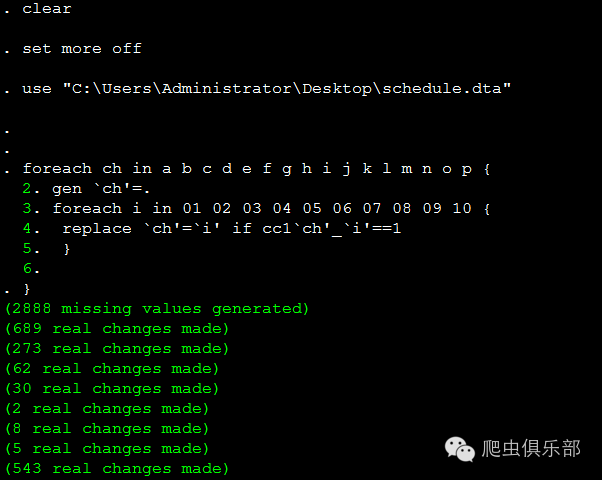
经过程序运行,最后得到的结果如下图所示。其中第一个学生在a(早晨6至7点)选择8(睡觉),第二个学生在b(早晨7至8点)选择1(上课)。每个学生不同时间段选择的项目一目了然。
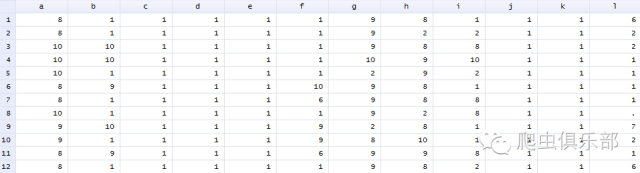
显然,循环语句的运用大大提高了我们数据处理的效率,一份复杂繁琐的统计表经过程序运行,结果清晰可见,为接下来的研究分析工作做好了充分准备。不知道提问的朋友看完本推文是否解决了你的疑问呢?Get到新技能的小伙伴也别忘了点赞和转发本文哟。
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按二维码关注公众号

微信扫一扫
关注该公众号