别人都送月饼,我们送……

中秋佳节来临,小编先在此祝福大家圆圆满满,中秋快乐。当别人在中秋节都送月饼的时候,小编给大家送来的是stata的一些好用的基础命令,一看我们的礼物就和外面的妖艳贱货不一样是不是!快来看看都有些什么好用的命令。
(1)缺失值的查看、检验和替换
*安装命令
ssc install mdesc
*导入数据
use http://www.stata-press.com/data/r11/mheart5,clear
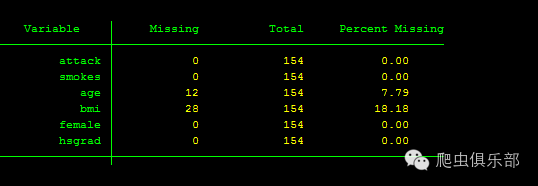
*查看缺失值
mdesc
*结果显示如下:
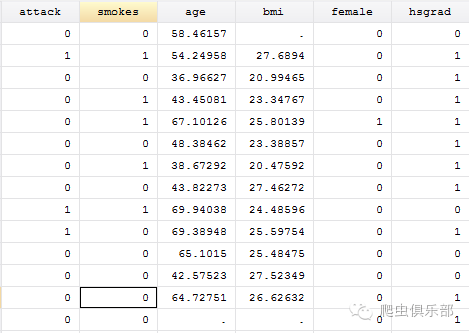
(2)变量均值获取:egen rowmean
egen函数作为generate的扩展,有着很强大的特性,拥有着众多的生成变量函数,能够满足不同的需求,具体的应用大家可以去看help文档,熟悉了会有很多应用,比如某些命令不支持在by或bysort,可以利用group来分组,然后用循环的形式来处理。本次简单介绍的是egen rowmean,用于取变量均值,该命令会依据列入其中的varlist生成横向均值。以下是命令演示:

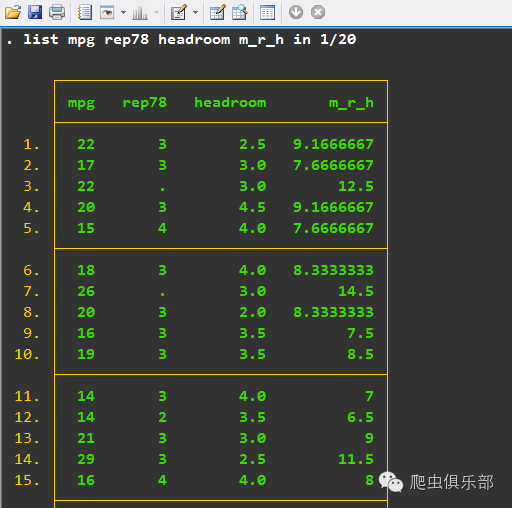
(3)变量分级(依据分位数分级):xtile and quantiles
大家在阅读文献的时候,经常会看到作者对变量进行分级处理,如decile(十分级)处理。其基本原理很简单,就是先将变量从小到大排列,然后选取所定的分位数为节点,将整体数据分组,从小到大依次取值。以三分级为例,先将数据从小到大排列,然后分别找到33%分位和67%分位数,然后将小于33%分位数的全部取值为1,33%至67%的取值为2,大于67%的取值为3。我们要进行变量分级处理的时候,可以使用官方xtile命令,以十分级为例(数据为伍德里奇《计量经济学导论》wage2):
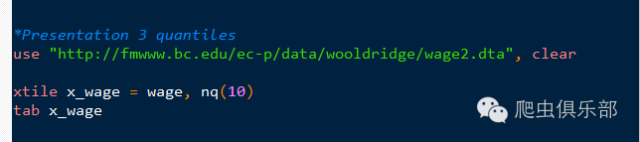
结果显示如下:
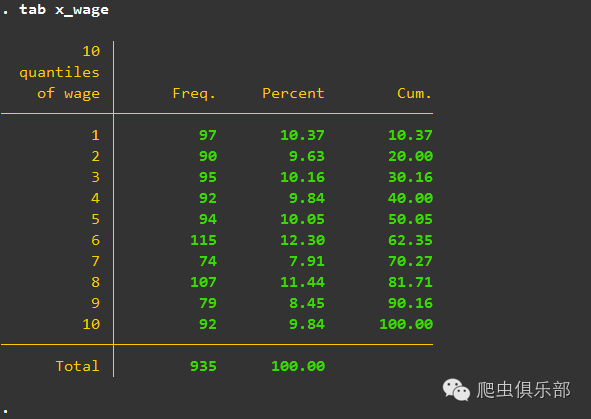
大家可能注意到里面似乎每组的数据量并不相等,这是因为xtile严格按照先确定分位数,然后分组的顺序来处理,这导致某些观测值相等的话会被分到同一组,使得每组数量可能并不相同。极端的例子,假如某个变量中有大量的0值,最终分级的结果可能是第1组的数量比重非常大,这显然不是我们所希望。因此,通常情况下,并不推荐使用官方命令xtile,而是使用第三方命令quantiles,它由Rafael Guerreiro Osorio编写,会将每组观测数自动处理好,延续上述的例子,以下是quantiles命令处理的结果:

结果显示为:
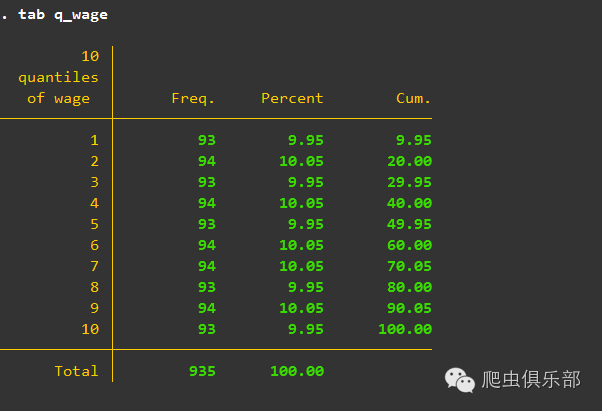
不知道大家有没有感受到小编给大家准备中秋礼物的诚意呀。关注我们的公众号,天天都能收到惊喜哟。好啦,小编要去吃月饼了,再次祝大家中秋节快乐!
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @徐苾雯)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按二维码关注公众号

微信扫一扫
关注该公众号