乱“码”渐欲迷人眼——识破UTF-8与gb2312的障眼法
最近,小伙伴们应该听闻了万科如电视剧一般的“八卦”,每天搞的这个大新闻啊,excited。不过,媒体界向来听风就是雨,其实说来说去,万科无非就是股权的问题呐!很抱歉,小编不是媒体专业人士,但是作为一名Stata学习者想和大家说,“闷声学Stata”才是坠吼的,学好Stata也可以挖“猛料”。所以,今天小编要和大家分享一下在获取万科(000002,SZ)的高管数据中所遇到的问题——如何在数据导入过程中处理UTF-8与gb2312的编码。
Stata13版本
一、同花顺(UTF-8)
1. 进入同花顺主页,通过股票代码“000002”搜索万科A的相关信息,然后找到关于万科A的高管数据。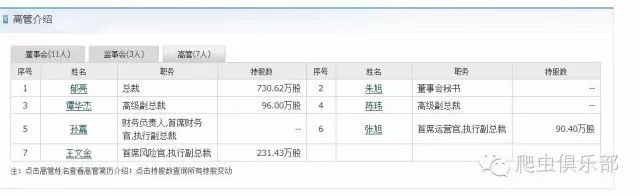
其网页链接如下:
http://stockpage.10jqka.com.cn/000002/company/#manager
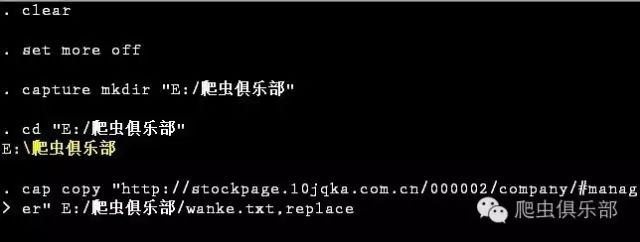
2.在Stata13中,通过copy命令,达到获取网页源代码的目的,并将其存储为”.txt”文件格式:
clear
set more off
capture mkdir "E:/爬虫俱乐部"
cd "E:/爬虫俱乐部"
cap copy ///
http://stockpage.10jqka.com.cn/000002/company/#manager///
E:/爬虫俱乐部/wanke.txt,replace
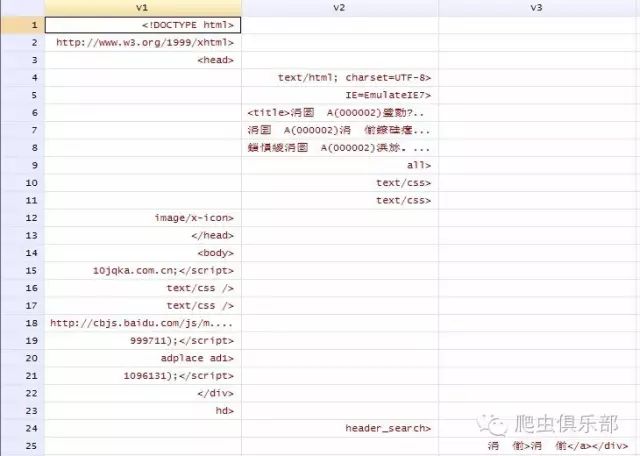
3. 通过insheet、importdelimit、infix三种方式分别导入数据:
a) 方式一: insheet usingwanke.txt,clear
句法规则:Insheet[varlist]using filename [, options]
需要注意的是:
1) 数据间以制表符(Tab分隔)或者以逗号分隔,但不能读取同时使用这两种分隔方法的数据;
2) 每一个观测值只能占一行;
3) 第一行可以包含或不包括变量的名字。如果文件的第一行不是变量名,则需要加上选项nonames,Stata给变量命名为V1,V2等。Tab分隔的文本文件(.txt),逗号分隔的文本文件(.csv)

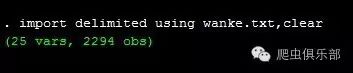
b) 方式二: import delimited
句法规则:importdelimited [using] filename [, import_delimited_options]
需要注意的是:importdelimit导入的是分隔的文本数据,每一个观测值只能占一行。
命令如下:
c) 方式三: infix
句法规则: infixusing dfilename [if] [in] [, using(filename2) clear]
需要注意的是:infix读入的是固定格式的数据。命令如下:
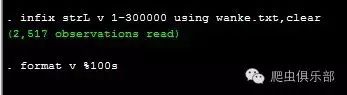
infix strL v 1-300000 using wanke.txt,clear
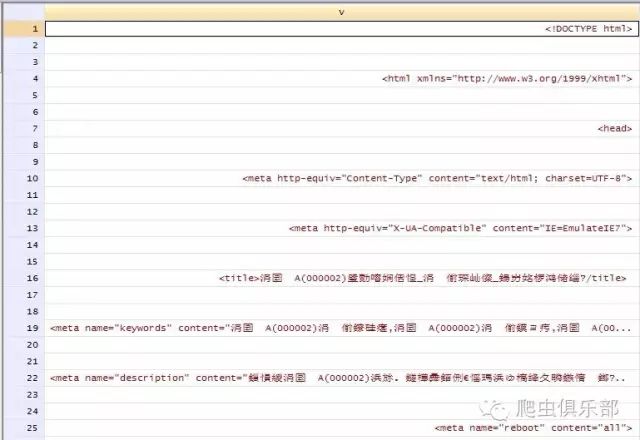
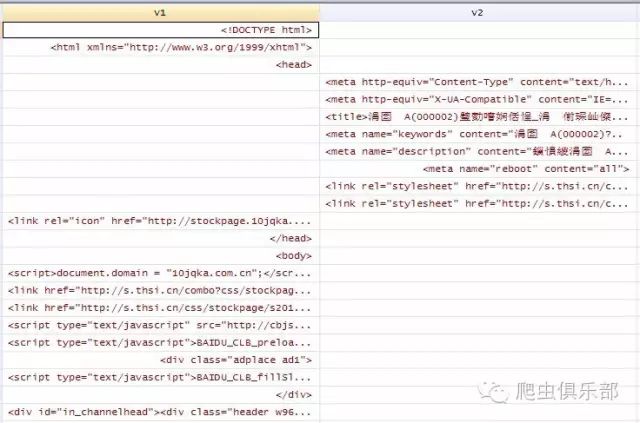
4. 打开copy下来的文件,通过ctrl+F搜索“charset=”,显示为UTF-8格式:
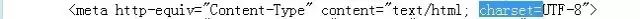
5. 由于”.txt”文件中为”UTF-8”格式,stata13无法对”UTF-8”格式进行识别,因此对于这种格式的文件,stata13如果需要对此转换,过程十分麻烦,所以我们将在后文使用Stata14版本进行操作。
二、新浪财经(gb2312)
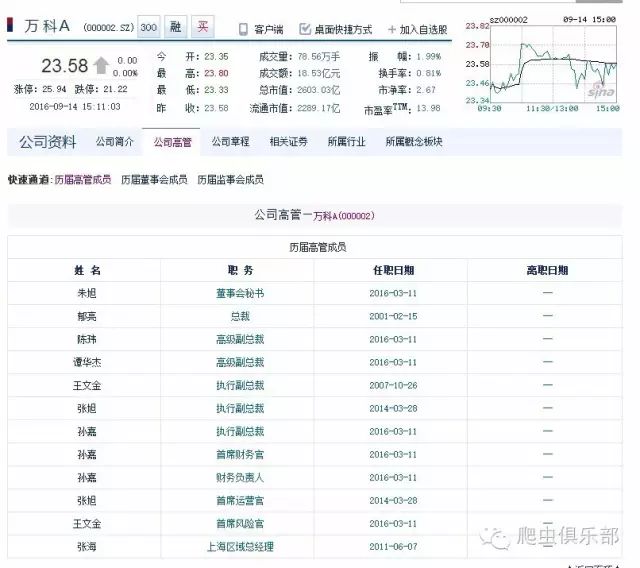
1.通过新浪财经网来搜索关于万科A的高管数据。其网页链接如下:
http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000002.phtml
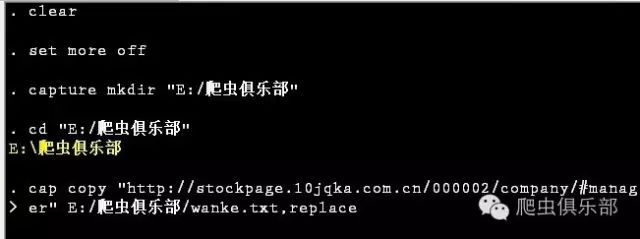
2. 在Stata13软件中通过copy获取网页的源代码,保存为”.txt”文件格式:
clear
set more off
cd "E:/爬虫俱乐部"
cap copy ///
"http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000002.phtml"///
E:/爬虫俱乐部/wanke2.txt,replace
3.导入数据:
a) 方式一: insheet:
insheet using wanke2.txt,clear

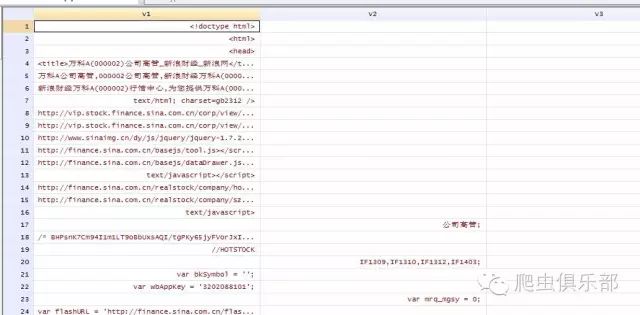
此时出现了多个变量,我们需要对此组合在一起,则我们进一步需要将其结果进行拼接到一起:
gen v=v1+v2+v3+v4+v5+v6+v7+v8+v9+v10+v12
keep v
b) 方式二: import delimited
import delimited using wanke2.txt, clear

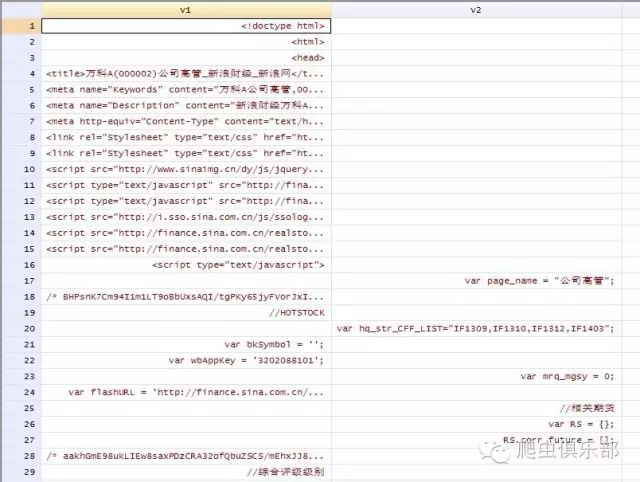
import delimited也出现如上多个变量的结果,我们也需要对其进行重新改善:
gen v=v1+v2+v3+v4+v5+v6+v7+v8+v9+v10+v12
keep v
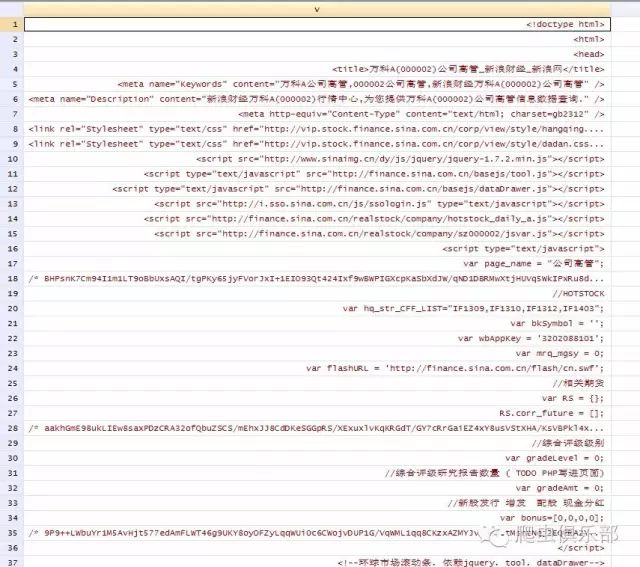
c) 方式三:infix
infix strL v 1-300000 using wanke2.txt,clear
format v %100s
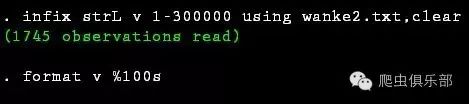
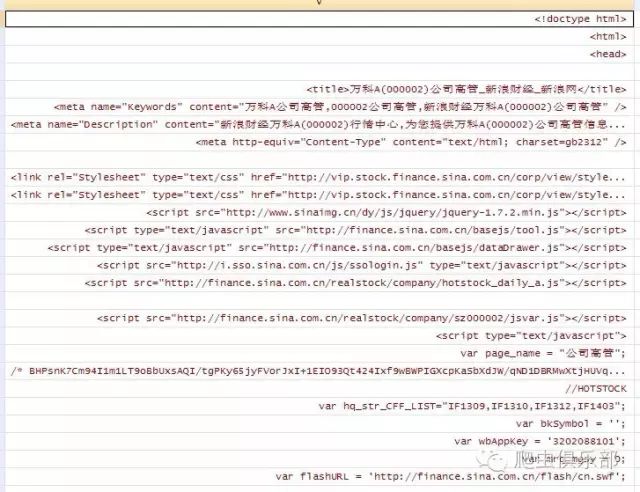
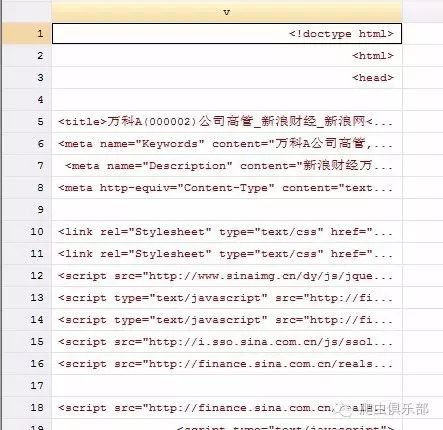
4. 打开copy下来的文件,通过ctrl+F搜索“charset=”,显示为格式“gb2312”

5.通过以上说明,stata13可以识别”gb2312”的编码文件。
Stata14版本
一、同花顺(UTF-8)
1. 进入同花顺主页,通过股票代码“000002”搜索万科A的相关信息,然后找到关于万科A的高管数据。
其网页链接如下:
http://stockpage.10jqka.com.cn/000002/company/#manager
2.在Stata14中,通过copy命令,达到获取网页源代码的目的,并将其存储为”.txt”文件格式:
clear
set more off
capture mkdir "E:/爬虫俱乐部"
cd "E:/爬虫俱乐部"
cap copy ///
“http://stockpage.10jqka.com.cn/000002/company/#manager”///
E:/爬虫俱乐部/wanke.txt,replace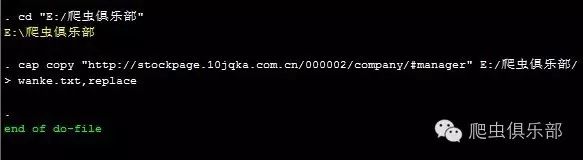
3. 打开copy下来的文件,通过ctrl+F搜索“charset=”,显示为UTF-8格式:
4. 通过insheet、importdelimit、infix三种方式进行数据导入:
a) 方式一:insheet
命令如下:
insheet using wanke.txt ,clear
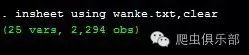
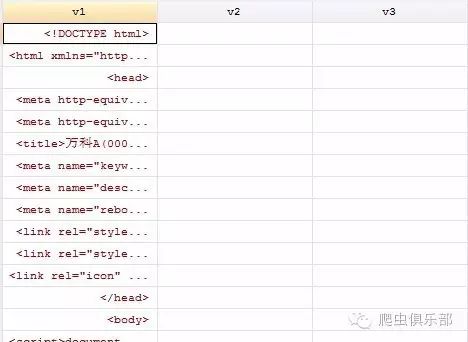
然后进行组合:
gen v=v1+v2+v3+v4+v5+v6+v7+v8+v9+v10+v11+v12+v13+v14+v15+v16+v20+v22+v23+v25
keep v
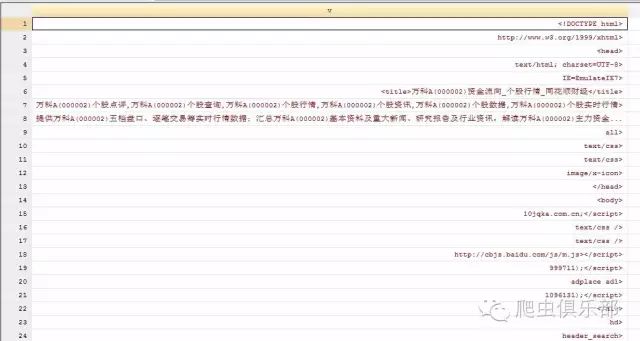
b) 方式二: import delimted
import delimited using wanke.txt,clear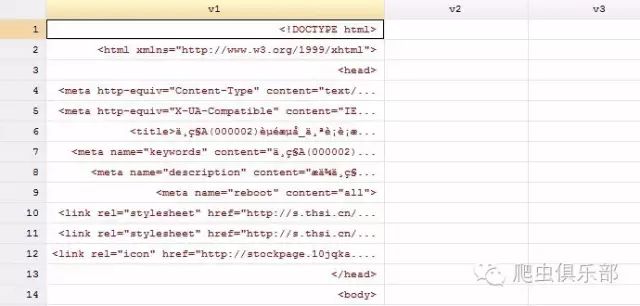
此时,我们看到这里会出现一群乱码。通过help import delimited,可以发现通过选项encoding转码,便能解决这个问题。命令如下:
import delimited using wanke.txt,encoding(UTF-8) clear
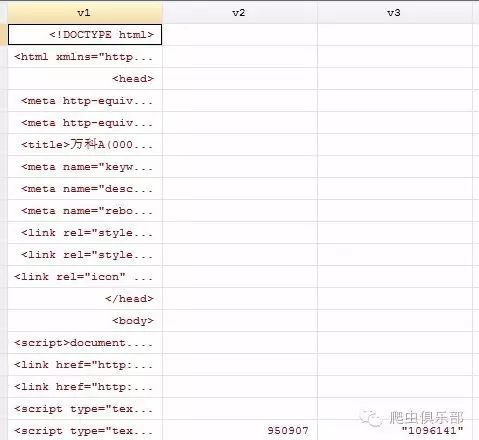
然后再进行组合:
gen v=v1+v2+v3+v4+v5+v6+v7+v8+v9+v10+v12
keep v
(c) 方式三: infix
Infix strL v 1-300000 using wanke.txt,clear
format v %100s
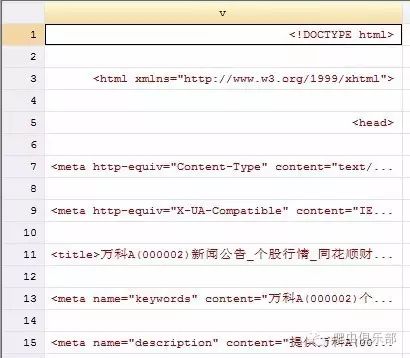
二、新浪财经(gb-2312)
1. 通过新浪财经网来搜索关于万科A的高管数据。其网页链接如下:
http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000002.phtml
2. 在Stata14中,通过copy获取网页的源代码,保存为”.txt”文件格式:
clear
set more off
cd "E:/爬虫俱乐部"
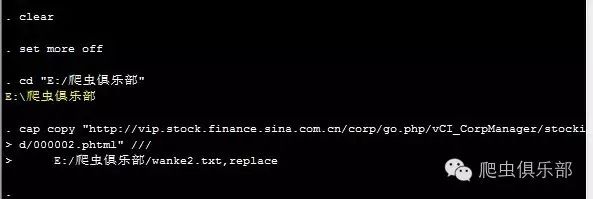
cap copy ///
"http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000002.phtml"///
E:/爬虫俱乐部/wanke2.txt,replace
3. 打开copy下来的文件,通过ctrl+F搜索“charset=”,显示为格式“gb2312”
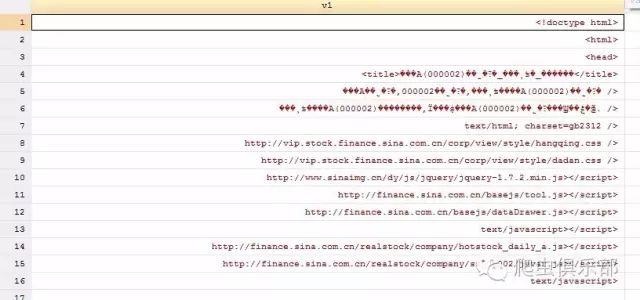
4. 当继续使用insheet、importimported与infix三种命令来进行数据导入时,我们会发现如下的问题:
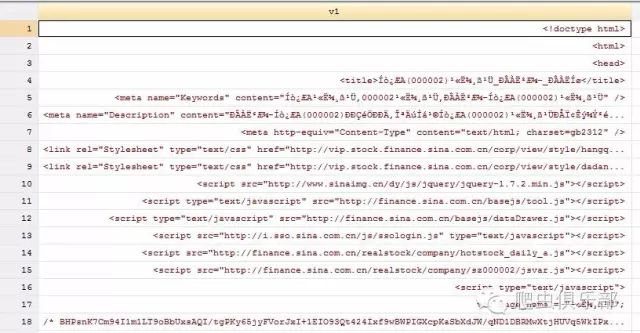
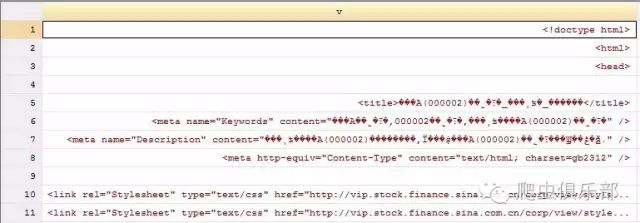
5. 此时,需要采用unicode进行转码(此处引用来自爬虫俱乐部的前身,数据处理援助中心《识得庐山真面目——unicode命令》一文)。在完成这个命令之前,必须清空数据,并且将文件保持在当前的工作路径。使用help encoding查看转换的编码,用unicode encoding set进行设置,在此我们设置为gb18030,然后进行转码,命令如下:
clear
set more off
cd "E:/爬虫俱乐部"
unicode encoding set gb18030
unicode translate wanke2.txt,transutf8
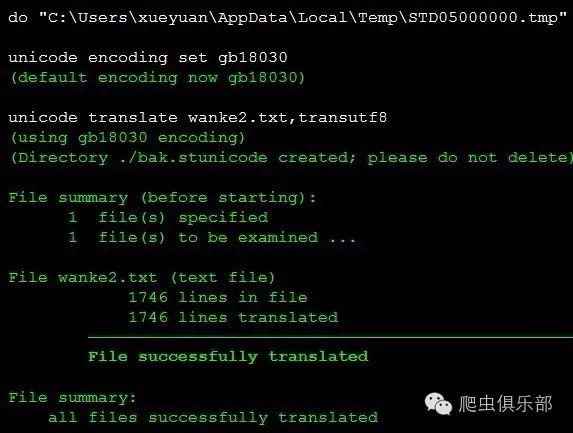
在进行unicode tranlate之后,会生成一个名为“bak.stunicode”的新文件夹,里面保存了文件在转码前的备份:
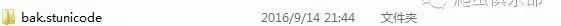
这样会使得在该路径下的”wanke2.txt”的文件不能再进行转码,倘若我们再对这个覆盖过后的文件"wanke2.txt"进行转码,需要先把这个文件夹删除,或者用unicode erasebackups这个命令,并加上badidea选项:
unicode erasebackups,badidea
这样,就又可以对”wanke2.txt”文件进行转码。然后,我们对转码过后的”wanke2.txt”文件进行导入。
a) 方式一:insheet using wanke2.txt,clear

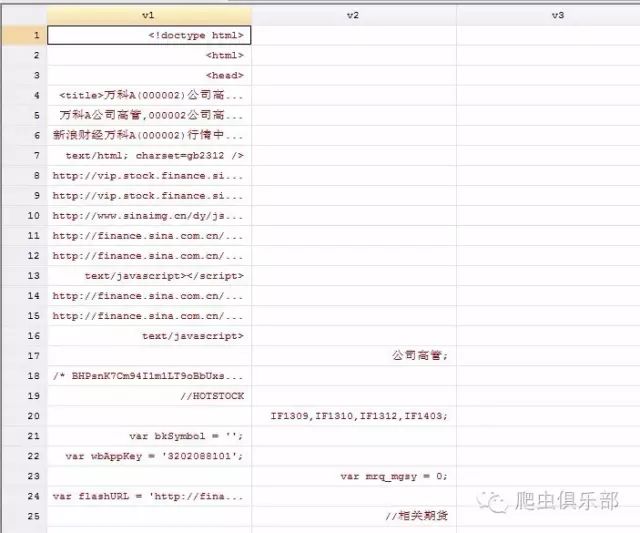
然后对于多个变量进行处理:
gen v=v1+v2+v3+v4+v5+v6+v7+v8+v9+v10+v12
keep v
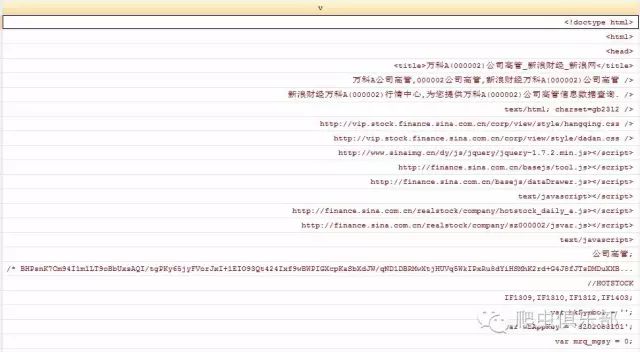
b) 方式二:import delimited using wanke2.txt,encoding(gb2312) clear

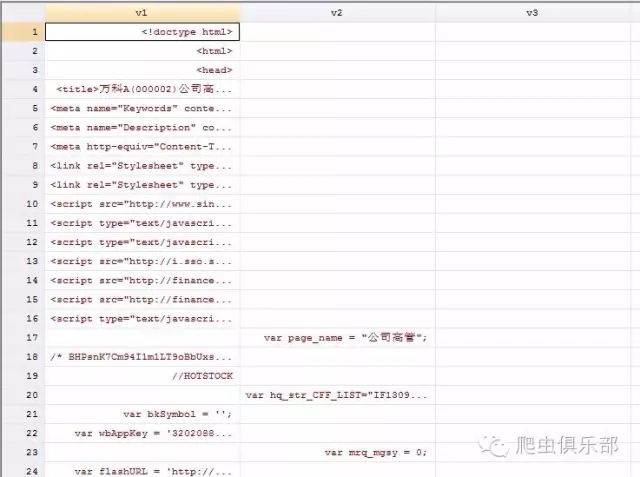
是对这多个变量进行处理:
gen v=v1+v2+v3+v4+v5+v6+v7+v8+v9+v10+v12
keep v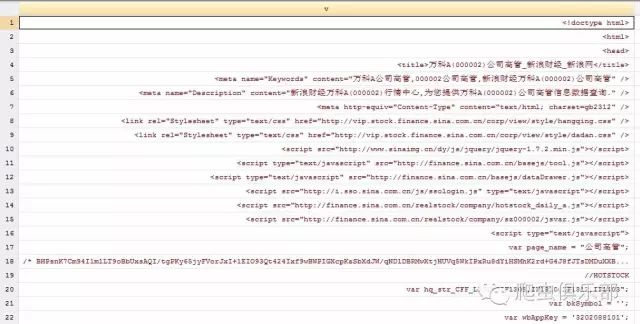
c) 方式三:infix strL v 1-300000 using wanke2.txt,clear
format v %100s

Tips:
1. 从infix与insheet、importdelimited导入结果我们发现:Insheet与import delimited导入的结果会出现多个变量,而infix导入的结果中只会出现一个变量,所以infix在数据处理过程中更加便利。因此,在对于”.txt”格式的文件进行导入时,我们会优先采用infix命令。
2. import delimited命令是有一定缺陷的。比如小编在对平安银行(000001)的高管数据的获取过程中发现,在1282个观测值中出现了乱码的问题。
clear
set more off
cd E:/
cap copy ///
"http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000001.phtml"///
E:/temp1.txt,replace
import delimitedtemp1.txt,encoding("gb2312")clear

但是在用unicode转码后,用insheet或者infix导入的过程中则没有出现这样的问题。
clear
set more off
cd E:/
unicode encoding set gb18030
unicode translate temp1.txt,transutf8
insheet using temp1.txt,clear

这说明import delimited在导入数据的过程中是有缺陷的。
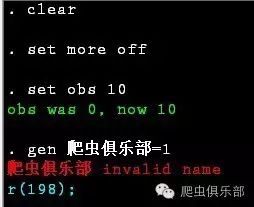
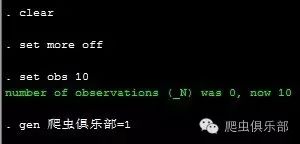
3.实际上,在Stata13中,系统能够识别gb-2312格式,我们不需要对其进行转码处理。对于UTF-8格式,Stata13则无法较好地解决,但Stata14能轻而易举地处理乱码的问题。如果各位觉得unicode转换稍显麻烦,有一种懒人办法就是:我们在获取源代码的数据后,首先查看文本文件,查找一下”charset=”,当charset=gb2312时,我们选择软件Stata13,当charset=UTF-8时,我们则选择Stata14。不过,对于小编这种已经被乱码折磨得感觉身体被掏空的人来说,Stata14在字符识别与处理以及正则表达式的功能上,相较于Stata13有了“质”的飞跃,比如,对于如下的同一组简单的代码,在Stata13中会出现错误,而在Stata14中则不会:
clear
set more off
set obs 10
gen 爬虫俱乐部=1
stata13的结果如下:
Stata14的结果如下:
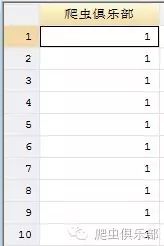
所以, Stata的使用,不仅要靠自我灵活运用,也要考虑到升级的进程。小编在这里斗胆推荐小伙伴们使用Stata14,当然你们自己的想法也是很重要滴。今天小编是不是又帮到了大家呢?哈哈,“爬虫俱乐部”专注解决Stata各种疑难杂症,关注后可延年益寿哒!小伙伴们快到碗里来!
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @徐苾雯 @薛原)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按二维码关注公众号

微信扫一扫
关注该公众号