用“套路”处理数据
在进行实证分析时,我们可能需要从数据库中下载数据,然后导入stata中处理成我们想要的形式,再进行实证分析。但是当我们下载的数据文件众多时,怎样才能将数据便捷地导入到stata中呢?悄悄告诉你,这是有套路的!
比如我们从国泰君安数据库下载了资产负债表,解压后是一个文件夹,里面包含多个文件,而且文件名称没什么规律。
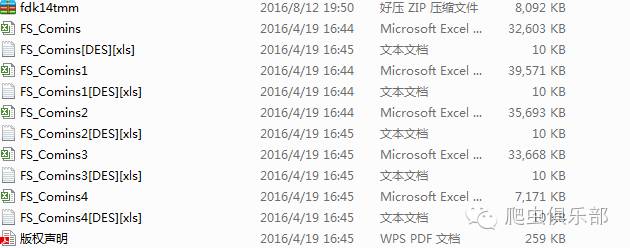
最开始用stata处理数据时,笔者只会一个一个的excel导入到stata中,每次都手动改一下文件名,虽然很麻烦,但是对于接触stata时间较短的朋友们来说,也算是个办法。

挨个导入并保存成dta格式之后,再用append命令把数据拼接在一起就可以啦。
但是,如果我们需要处理的数据量非常大时,这样的方法就变得费时费力了。当笔者正为这事苦恼的时候,师兄传授了笔者一招,瞬间感觉自己get到了“了不得”的技能。
要想习得这一招,首先要有基本功——两个命令。
1.“宏”,这里我们需要用到的是局部宏local命令,它的命令格式如下:
2.dir命令,这个命令是用来展示文件名,它的命令格式如下:
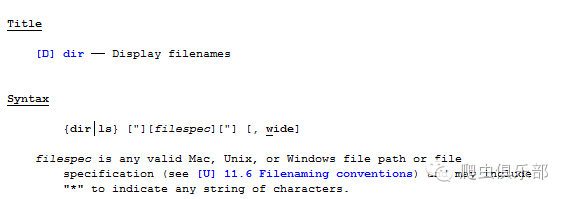
比如,如果我们想知道资产负债表这个文件夹里面有哪些excel表格,就可以借助于dir命令。
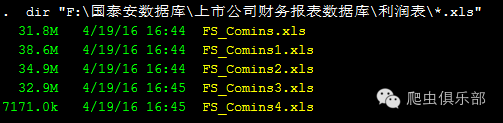
有了“基本功”之后,我们把这两个命令结合起来,先把文件夹里的excel表格展示出来,把它们赋给一个“宏”,后面直接调用就可以啦。

接着,可以运用循环,让stata直接调用前面的宏就可以批量导入数据、分别保存数据、拼接数据。代码如下:

接下来就是常规的数据处理了,保存需要的数据、生成需要的变量、把字符型变量变成数值型变量、排序,这样,我们需要的数据基本得到了。
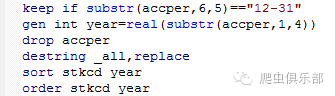
最后,是非常简单但却有点费事的一步——定义标签。原来的数据变量名不规律,所以为了以后使用数据时比较方便,需要定义标签。这里又要用到师兄教的独门秘诀了。由于数据里的变量数量太多,一个一个地去定义标签太慢,为了得到label语句,我们要借助一下excel表格。

打开一个原始数据后,把变量名和标签选中复制,然后打开一个新的excel,选择性粘贴,选择转置,然后借助公式就可以得到完整的label语句,把最右一列复制到stata 的do文件里直接运行就可以定义标签了。
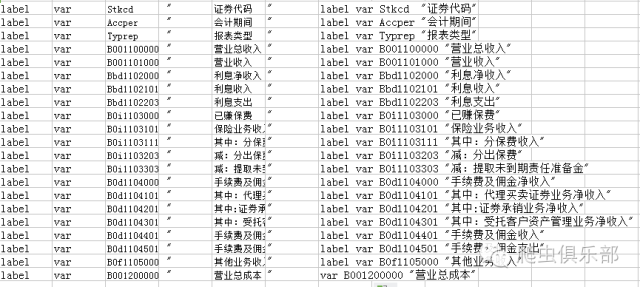
经过上述处理过程之后,最后别忘记保存一下数据。
学会这一招之后,有再多需要处理的数据也不用怕了,通通按这个“套路”来,每次只需要换一下文件夹的名称,导入数据分分钟搞定。所以,你还在犹豫什么,城市套路深,快来关注“爬虫俱乐部”,来学一些关于stata的小套路~
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @强宇曦 @徐苾雯)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答
 长按二维码关注公众号
长按二维码关注公众号


微信扫一扫
关注该公众号