厉害了,我stata哥
你 还在微博上搜“厉害了我的哥”是什么梗?今天小编让你看看厉害的是stata哥,教你用stata抓取百度新闻量。当前,网络爬虫技术在实证研究中的作用 越来越突出。众多学者在进行研究的时候,通常将搜索引擎(百度、google等)相关新闻数量与搜索结果数量作为研究指标之一,该指标能够反映大众舆论媒 体对事件的关注程度。而这些搜索引擎的相关新闻数量如何用stata来爬取?让小编带你领略其中的奥秘。
例如我们用百度搜索引擎搜索天宫二号的新闻。
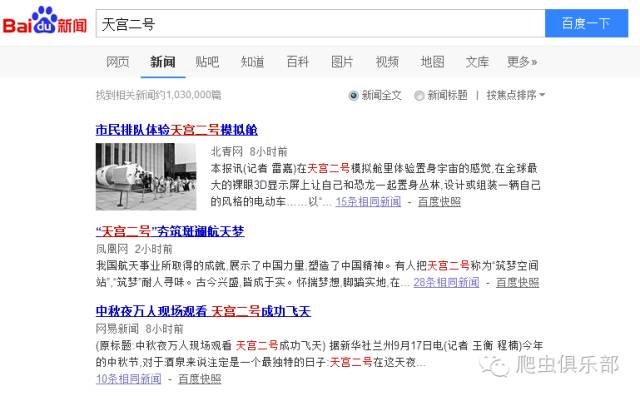
可以看到在新闻搜索结果中的第一行有这样一栏:找到相关新闻约1,030,000篇。现在我们就要将这些内容爬取下,先让我们看下网页源代码。

在网页源代码中我们能够看到我们需要抓取的内容:找到相关新闻约1,030,000篇。因此我们可以将其抓取,第一步是找到其网页地址。
http://news.baidu.com/ns?cl=2&rn=20&tn=news&word=天宫二号
通过网址链接我们可以看到长长的一大串似乎没任何规律,但仔细阅读我们可以发现,网址链接中的每个字符都是有其特殊含义的:
ns(News Search):新闻搜索;
cl(Class):搜索类型,cl=3为网页搜索,cl=2为图片搜索;
rn(Record Number):搜索结果显示条数,缺省设置rn=10,取值范围:10-100;
tn:提交搜索请求的来源站点,本例中的来源就是news;
word:查询的关键词;
?:分隔实际的网页链接和参数;
&:参数间的分隔符。

通过以上了解我们可以看到“word=”才是该网页链接的核心。于是我们将网页链接转换成:
“http://news.baidu.com/ns?word=天宫二号”
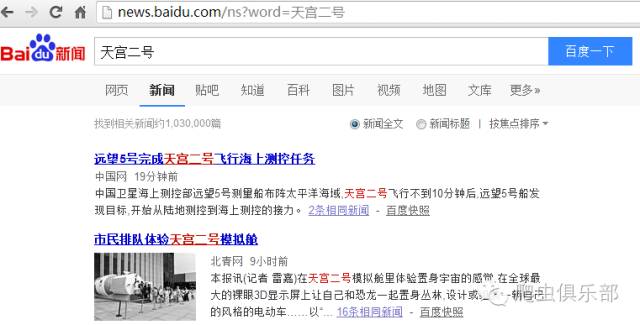
可以看到新闻搜索结果的下的第一栏为:找到相关新闻约1,030,000篇,这与我们最初的网页链接搜索结果一致,因此该方法可行。
之后我们再将“word=”后的内容替换。
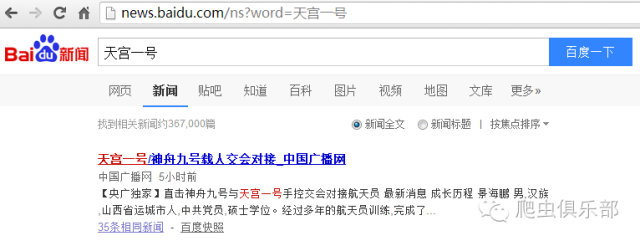
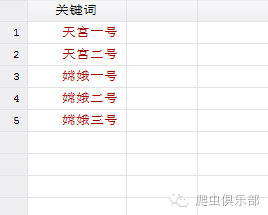
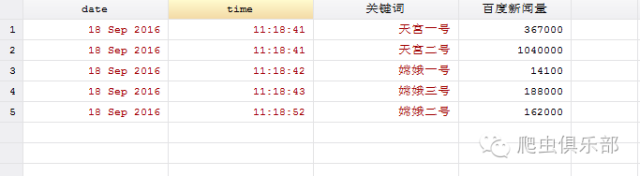
可以看出百度新闻搜索显示我们希望得到的搜索结果。这样,我们就从链接中找到了规律,满足了我们批量处理的要求。因此下一步我们就可以进行批量抓取百度新闻的相关新闻数。比如我们现在有如下五个关键词,要抓取相关搜索数量。
我们运用levelsof命令对关键词进行批量的处理,通过"找到相关新闻约"这段字符定位我们提取信息所在的行,再用正则表达式提取我们需要的信息。因为百度新闻量会更新,所以我们在抓取时设置两个变量分别为抓取的日期(date)和时间(time),最后将这些信息运用post命令处理,并且除去数字中间的逗号,将“百度新闻量”变量转化为数值型,就得到了以下结果:
do-file如下:
clear
set more off
use "d:\关键词.dta",clear
capture postclose baidu
postfile baidu str20 date str20 time str20 关键词 str20 百度新闻量 ///
using "d:\baidu.dta",replace
levelsof keyword,local(levels)
foreach c of local levels {
copy "http://news.baidu.com/ns?word=`c'" "d:\temp.txt",replace
infix strL v 1-200000 using "d:\temp.txt",clear
keep if index(v,"找到相关新闻约")
replace v = ustrregexs(1) if ustrregexm(v,"约(.+?)篇")
disp "`c'"
local date = c(current_date)
dis "`date'"
local time = c(current_time)
disp "`time'"
post baidu ("`date'") ("`time'") ("`c'") (v[1])
}
postclose baidu
use "d:\baidu.dta",clear
replace 百度新闻量 = ustrregexra(百度新闻量,",","")
destring 百度新闻量,replace
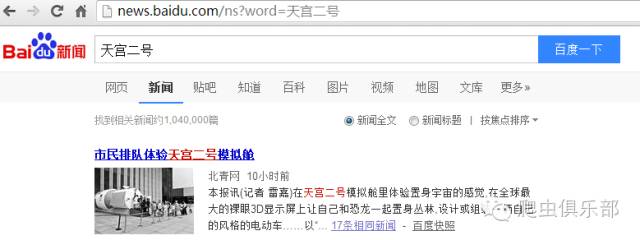
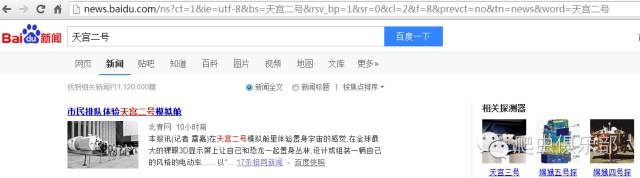
当前百度新闻搜索量的抓取还存在一些小的问题。当我们连续点击搜索键的时候,发现两次结果并非一样。第一次结果为“找到相关新闻约1,040,000篇”,第二次结果“找到相关新闻约1,120,000篇”,两个网页地址不相同,我们来分析第二个网页地址。
http://news.baidu.com/ns?ct=1&ie=utf-8&bs=天宫二号&rsv_bp=1&sr=0&cl=2&f=8&prevct=no
&tn=news&word=天宫二号
ct:语言限制。0-所有语言,1-简体中文网页,2-繁体中文网页;其它不确定或者无效或。默认值为0;
ie(Input Encoding):查询输入文字的编码,缺省设置ie=gb2312,即为简体中文;
bs(Before Search):上一次搜索的关键词,估计与相关搜索有关;
rsv_bp:判断是第几次搜索,0为第一次搜索,1为第二次或者多次搜索;
sr:结合bs使用。一般查询sr=0或者为空值,但sr=1时,查询将结合bs的值一起作为查询的关键字。默认值为0,除0、1外其它值无效。
因此第一种的搜索结果是在默认设置的情况下得出,第二种的搜索结果是加上条件限制的,因此二者的搜索结果数不同。
此外当我们从地址栏复制网页地址“http://news.baidu.com/ns?word=天宫二号”的时候,网页地址自动生成http://news.baidu.com/ns?word=%E5%A4%A9%E5%AE%AB%E4%BA%8C%E5%8F%B7。其中“%E5%A4%A9%E5%AE%AB%E4%BA%8C%E5%8F%B7”这部分看起来杂乱无章,但熟悉url编码的朋友能够看出这里其实是采用了百分比编码。这里面又有怎样的奥秘呢?继续关注我们的“爬虫俱乐部”公众号,在今后的推文我们再来着重介绍该部分的内容。
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @徐苾雯)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答

长按二维码关注公众号


微信扫一扫
关注该公众号