Stata你把我的信息放在哪里了
就像被张士超藏起来的钥匙遍寻不着,你想要的信息总是散落在天涯海角,考验着你的眼力与耐心。这时候,你需要Stata君来助你一臂之力,让信息快到碗里来。下面,我们以获取期刊目录为例,向大家展示Stata君的具体操作。
为了获得期刊目录,小编从网上下载了有关期刊目录的txt文档,文档通过stata的insheet导入命令时,发现变量V1只有期刊名称是小编需要的,其余有很多不需要的内容。
此时小编就要拥有大师兄孙悟空的火眼金睛将需要的期刊名称辨别出来再制作小编想要的期刊目录,接下来小编将使用stata将其一一清除。
clear
set more off
cd "D:期刊目录"
insheet using "CSSCI期刊目录.txt",nonames

drop if v1==”期刊名称”
运行之后,却发现第一行期刊名称并没有被drop掉。


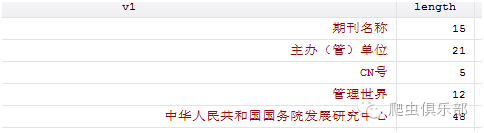
这是因为insheet命令读取的txt文件包含utf-8编码且带BOM头和一些字符串处理问题。所以小编使用drop if v1==”期刊名称”命令不能将第一行“期刊名称”剔除掉,因为第一行除了“期刊名称”外还包含了不可见字符(BOM)在内。我们可以通过看”期刊名称”的字符串长度来观察区别首先生成一个新变量来观察字符长度。
gen length=strlen(v1)
为了方便读者,小编新生成一组变量v2包含”期刊名称”和”主办(管)单位”对其字符串再处理两组字符串长度进行对照。
gen v2=""
replace v2="期刊名称" if_n==1
replace v2="主办(管)单位" if _n==2
gen length1=strlen(v2)

根究length 和length1进行比较可以发现两组”期刊名称”的字符串不一样,v1组字符串为15,v2组字符串则是12少三个,其余的字符串两组都一致,说明txt文档导入数据第一行出现不可见字符(BOM)与此同时小编对v1v2使用ustrreverse函数因为Stata14 新增的ustrreverse函数可以很出色的文字逆反而且不会出现新生变量出现乱码。
gen v3=ustrreverse(v1)
gen v4=ustrreverse(v2)
list v1 v3 v2 v4

ustrreverse命令结果
小编发现ustrreverse函数对v1”期刊名称”所得v3表现异常出现一格空白,而v4则没有出现该情况,这个函数同样可以展现TXT文档读入第一行出现不可见字符。
为了解决这种奇怪的现像,小编采用index命令来代替就可以巧妙的解决这种问题:
drop if index(v1, "期刊名称") |v1 == "主办(管)单位" | v1 == "CN号"
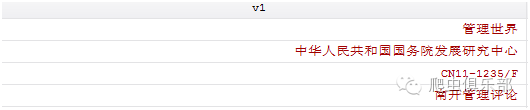
删除掉内容包括期刊目录、主办(管)单位、CN号的观测值。
V1还包含期刊录取名单形式为(“数字”种)的观测值,例如”中国文学学科拟录取来源期刊名单(16种)”。

drop if ustrregexm(v1,"(\d+种)")
通过正则表达式定位到存在(“数字”种)的观测值,删除掉。
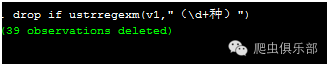
剩余的观测值只有期刊名称和其对应的主办单位以及CN号。 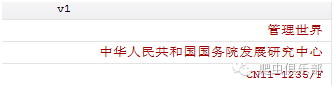
根据观测数据分布,其中期刊名称都是在以3余数为1的行数里面所以执行以下命令:
keep if mod(_n,3) == 1
compress

这样小编经历了九九八十一难终于取得”期刊目录”真经。
最后一个问题:会Stata的姑娘真的那么可爱吗?

没错,就是这么可爱。

如果有读者运到同样的困扰,希望小编的推文可以帮到您。
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @付彩月)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按关注微信号


微信扫一扫
关注该公众号