擂台赛|Stata14 VS Stata13之字符串函数PK
之前的推文我们讲过,Stata14可以识别Unicode编码,因此Stata14增强了其对于文本的处理能力,从而字符串的匹配、字符串的提取与替换的功能得到提升。接下来让我们详细地介绍Stata13与Stata14运用正则表达式处理字符串的方法。
Stata13以及之前的版本中,Stata主要用的regexm、regexs和regexr三个字符串函数,来实现正则表达式与ASCII 字符串的匹配以及字符串的提取与替换。而Stata14增加了ustrregexm、ustrregexf、ustrregexra、 ustrregexs几个字符串函数。在这些函数中,reg代表regular,ex代表expression,regular expression就是正则表达式的英文。在后四个函数中出现的ustr代表unicode string而其他几个字母的含义会在对应的函数中介绍。
1.regexm(s,re)函数:“m”代表match,这个函数主要用于字符串与正则表达式的匹配。“s”代表字符串,也可以是相应的变量,“re”代表正则表达式,如果字符串中有正则表达式匹配到的内容就赋值为1,否则赋值为0。我们可以看如下的例子:
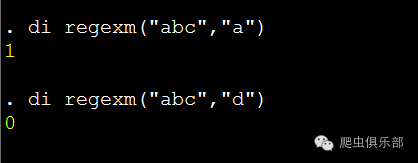
字符串“abc”中可以匹配到“a”,但是不能匹配到“d”,因此显示的数字分别为1和0。这就是字符串函数regexm(s,re)将字符串与正则表达式匹配的功能。
2.regexs(n)函数:“s”代表substring,也就是子字符串。“n”为 非负整数,代表regexm(s,re)函数中第n个子表达式对应的子字符串。若n为0,则代表引号中所有表达式对应的子字符串。regexs函数必须在 regexm函数运行之后才能运行,这两个函数实现了通过正则表达式对文本中所需信息的提取。我们来看下边一个例子,我们希望提取城市的名称,因此将变量 中第一个“市”之前的内容提取。
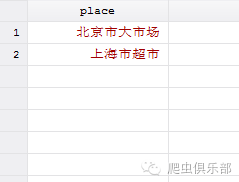
gen city = regexs(1) if regexm(v,"(.+市)(.+市)")
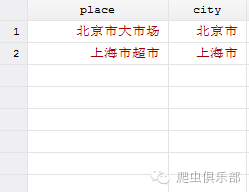
于是regexs(n)函数就派上了用场,regexs函数在regexm函数运行之后可以运行,其中regexm函数之后的元字符,如 . + 等,我们接下来的推文还会详细介绍。
3、regexr(s1,re,s2)函数:“r”代表replace,说明这个函数主要用于字符串的替换。s1和s2均为字符串,“re”代表正则表达式,该函数是将字符串s1中正则表达式re对应的部分替换为字符串s2,我们看接下来的例子:

1. ustrregexm(s,re[,noc]):这个函数的用法类似于regexm(s,re),区别在于可以在noc这个部分填上一个数字,如果你定义了noc,并且将其定义一个不为0的数字,那么在正则表达式和字符串匹配的时候是不区分大小写的。我们看下接下来的例子:

我们可以看到,当我们不定义noc时,在默认状态下匹配是区分大小写的;当我们把noc定义为0时,匹配也是区分大小写的,其他数字均不区分大小写。
2、ustrregexs(n)函数:这个函数的用法和regexs(n)函数相同,这个函数需要和ustrregexm(s,re[,noc])函数配合使用,实现了对文本的提取工作。在这里就不赘述啦。
3、ustrregexrf(s1,re,s2[,noc])与ustrregexra(s1,re,s2[,noc]):这两个函数的用法类似于regexr(si,re,s2),是将字符串s1中与正则表达式re匹配的部分替换为字符串s2,[noc]的用法与ustrregexm相同,表示是否区分大小写。这里的两个函数中,“f”代表first,是指将字符串s1中与正则表达式re相匹配的所有子字符串中的第一个子字符串替换为字符串s2;“a”代表all,是指将字符串s1中与正则表达式re相匹配的所有子字符串替换为字符串s2。这也是Stata14增加了一个对所有字符串匹配以及对第一个字符串匹配替换的功能。


在这两个例子中,当我们不定义noc 时,在默认状态下是区分大小写的。当我们把noc定义为0时,匹配也是区分大小写的。这与函数ustrregexm(s,re[,noc])相同。在 ustrregexrf(s1,re,s2[,noc])函数的例子中,我们只将字符串“ABCabc”中与正则表达式相匹配的第一个子字符串替换成 “X”;而在ustrregexra(s1,re,s2[,noc])中,我们将字符串“ABCabc”中与正则表达式相匹配的所有子字符串都替换成了 “X”。
接下来我们来讲下regex系列的函数与ustrregex系列的函数在处理中文文本能力方面的区别。我们首先生成了一个字符型变量,输入的内容为河南省郑州市,广西壮族自治区南宁市。我们要将“郑州市”“南宁市”三个字提取出来。

gen city = regexs(1) if regexm(place,"[省区](.+)$")
gen city1 = ustrregexs(1) if ustrregexm(place,"[省区](.+)$")
我们可以看到,用regex 函数提取出来的文本前面有菱形的乱码,是我们在使用[]元字符时出现了这个问题。而用ustrregex函数提取出来了“郑州市”“南宁市”。这主要是因 为regex的函数是将正则表达式与ASCII编码的文本进行匹配。而到Stata14可以识别unicode,因此ustrregex的函数处理中文文 本的能力才会提升。同时Stata14版本运用ustrregexra函数对字符串中所有能与正则表达式匹配的部分进行匹配替换,这是Stata13及以 前的版本所不具备的功能。
今天我们介绍了Stata正则表达式所用到的七个字符串函数。之后还会有关于Stata正则表达式的基础内容中关于元字符的推文,以及继续介绍正则表达式在文本分析和文本处理尤其是中文文本中的应用。看完今天的擂台赛,stata14先胜一局,小编把花花送给stata14啦,如果你还想看stata更多的小秘密,请继续关注我们的公众号,小编在这里等你。
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @徐苾雯)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按二维码关注公众号


微信扫一扫
关注该公众号