据说这样数据替换比较快,你试一下,然后……
面对一堆的数据我们处理起来往往焦头烂额,如果不get点新技能,数据处理又会耗费大量时间。贴心的小编今天来给大家介绍几个好用的数据替换命令,你试试看,然后你就会知道小编有多么贴心啦。
一.recode命令
我们在处理数据的过程中,会遇到许多数值型变量。倘若我们需要此类变量进行替换的话,我们可以采用recode命令来处理。
recode varlist (rule) [(rule) ...] [, generate(newvar)]
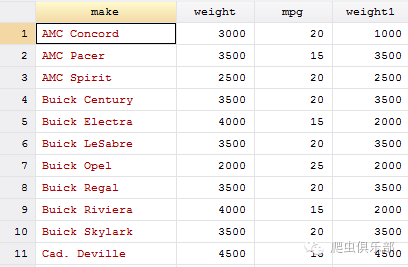
举个例子,我们在如下的数据中,想将数值型变量weight中的3000替换成1000,4000替换成2000,则:
sysuse autornd,clear
recode weight(3000 = 1000) (4000 = 2000), gen(weight1)
而recode命令只能针对于数值型变量进行处理。但是当我们遇到许多字符型变量的时候,我们应该怎么处理呢?这个时候,我们可以采用subinstr()函数。
二、subinstr()函数
1. subinstr(s1,s2,s3,n):将字符串中s1中前n次出现s2时的s2替换成字符串s3。如果n为“.”,则将字符串s1包含的s2字符串全部替换成s3。
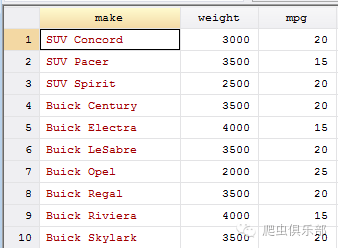
根据上面的数据,我们将字符型变量make中的”AMC”来替代成”SUV”:
replace make=subinstr(make,"AMC","SUV",1)
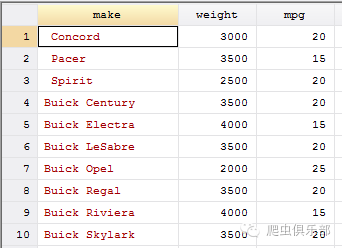
2.而我们想对字符型变量make中的字符”SUV”进行删除,我们则可以通过字符””来对”SUV”进行替换,来达到删除的效果:
replace make=subinstr(make,"SUV","",1)
但是对于多个字符型变量进行替代的时候,我们需要对写多行代码对各个变量进行替代,从而过程比较繁琐,那么我们可以介绍一种新的命令——fdta,可以用一个fdta命令对所有变量来达到替换的效果。
三、fdta命令
首先这个命令需要进行下载:ssc install fdta,现在我们再来看看具体的使用方法。
1.句法规则:fdta variables , from(str1) [to(str2)]
fdta对字符型变量中的字符串进行替代,它具有两个选项,from(str1)是找到变量中需要被替代的str1字符,而to(str2)选项则是用str2来替代from(str1)中str1字符。而且我们可以对from()与to()选项进行简写,from()可以被写成f(),而to()可以被写为t()。
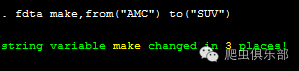
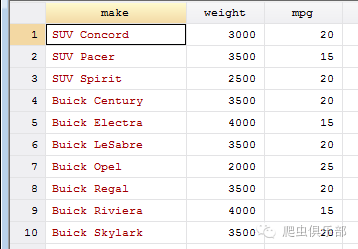
2.我们同样可以根据需要将make变量中的”AMC”替代成”SUV”,结果如下:
fdta make,from("AMC") to("SUV")
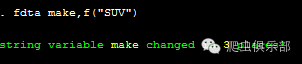
3.而对于fdta中的from()和to()两个选项,我们不能对from()进行省略,但是我们可以对to()选项进行省略,其结果与to(“”)结果相一致,其目的在于将make中的”SUV”进行删除:
fdta make,f("SUV")
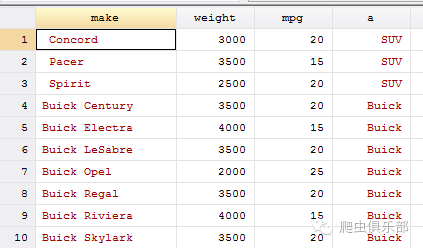
fdta make,f("SUV") t("")
4.那么在多个变量的情况下,我们则可以用fdta进行一次性处理,相比于subinstr()过程更加简洁:
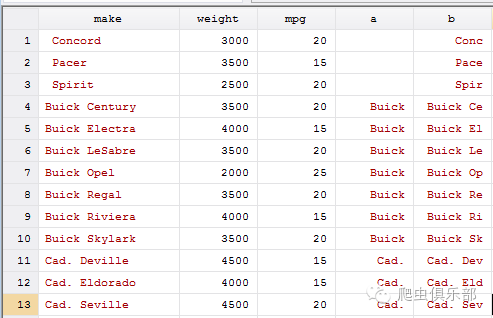
sysuse autornd,clear
gen a=word(make,1)
gen b=substr(make,1,8)
fdta _all,from("AMC") to("SUV")
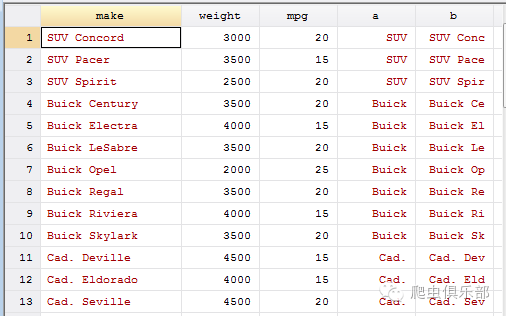
fdta _all,f("AMC")
今天的数据替换命令简单又实用,你去试一试,是不是给你减少了许多工作量,节约了许多时间?欢迎大家关注我们的公众号,我们会继续给大家提供实用的stata命令,你会发现小编最贴心啦~
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @徐苾雯)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按二维码关注公众号

微信扫一扫
关注该公众号