【有问必答】神奇的字符

这篇推文同样来自于湖南大学的美女苏老师的问题。苏老师希望能将字符型变量surname为缺失的观测值全部删掉,但却出现了许多“钉子户”,总是无法剔除干净。笔者将数据用unicode命令转码后,导入Stata14,按照surname变量进行排序后,看到最后一条观测值的surname变量是缺失的。这就很奇怪了,因为Stata14对字符型变量按照unicode编码顺序进行排序,无论是缺失、半角空格、全角空格还是各种控制字符,排序后都应该是在汉字之前。事实也证明无论是替换掉空格还是用正则表达式替换掉控制字符,都起不到任何效果。
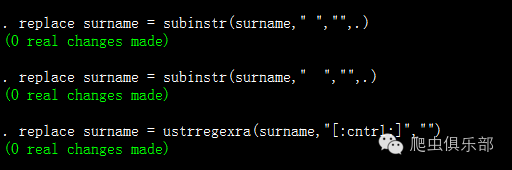
于是我们用list命令看了一下,有了新的发现。
list surname in -1
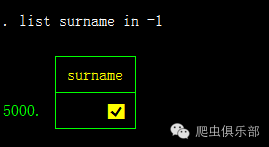
最后一条观测值居然是一个方框里面有对号的奇葩字符。我们直接复制下来当然可以删除掉,但是这样的字符是否只有这么一个?在样本量非常大的情况下,如果有好多个这样的字符呢?有没有什么办法去分析这个这个奇葩的字符呢?
在这里,我用了之前在原来的公众号上提取经纬度的推文中用到过的percentencode命令。这个命令来自于William Matsuoka的个人主页上,从上面找到了这个将字符转化为url中百分比编码的程序,并经过改造变成了这么一个命令。其实转化成的百分比编码,就是utf8的16进制编码。
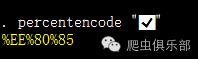
这就是说,这个奇葩字符对应的utf8的十六进制编码是EE 80 85,如果转化成unicode16进制编码,就是E005。而unicode的16进制编码中E000-F8FF范围的6400个字符属于自行使用区域(Private Use Zone)这么一个奇葩范围。将16进制的编码转化为10进制的编码,我们可以通过uchar函数来看看这些奇葩的字符究竟是什么。
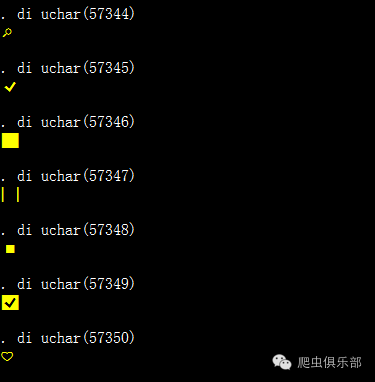
我们生成一个变量,下面都是这样的字符,可以看一下结果。
clear
set obs 10
gen v = ""
forvalues i = 1/10 {
replace v = "`=uchar(57343+`i')'" in `i'
}
edit
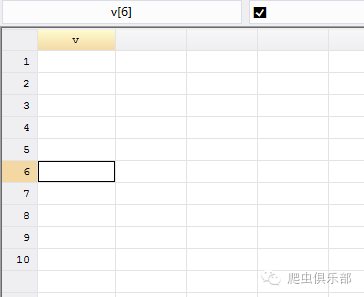
可以看到我们生成的字符在单元格内都无法显示,但是选中对应的单元格,上方还是可以看到字符。
对于前文中的数据,我们可以直接用uchar函数将这个观测值删除掉。
drop if surname == "`=uchar(57349)'"

我们要将这一类的字符剃干净可以做一个循环,这一类字符的unicode的10进制编码范围为57344-63743,为了防止遗漏,笔者建议还是将这些字符替换掉,之后再去空格,最终将缺失值删除掉,不然假如这个字符和空格同时出现在一个单元格,就会剔除不干净;而如果这个字符和我们要保留的汉字同时出现在一个单元格,用index()或strpos()函数就会把我们要保留的内容删除掉。
forvalues i = 57349/63743 {
replace surname = subinstr(surname,`"`=uchar(`i')'"',"",.)
}
小编看到那些奇葩的字符觉得那可能是unicode的 一种卖萌方式,通过推文的介绍我们便可以轻松将它们替换掉并删除缺失值,遇到相同问题的读者朋友不妨自己尝试操作一下。我们的团队也乐于帮助大家解决各种 问题,快来关注我们的公众号,希望通过我们的小推文让你爱上萌萌哒stata。今天已经是九月的最后一个工作日啦,小编乖乖坐等为祖国麻麻庆生,在此提前 祝大家国庆快乐,假期出行,注意安全~
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @徐苾雯)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。
长按二维码关注公众号

微信扫一扫
关注该公众号