stata的收纳盒——zipfile&unzipfile,你值得拥有
诸君安,我是一只可爱的爬虫酱,今天带着一个鲜嫩的推手为大家介绍一下stata的压缩命令——zipfile&unzipfile。一屋不扫何以扫天下。所以,我们必须先给数据一个整洁的收纳环境,才能任凭数据称霸天下!今天就和大家分享stata的收纳盒!
zipfile和unzipfile是Stata对文件进行压缩和解压缩的一对姊妹命令。如果用户需要处理大量的数据文件,而且这些原始数据文件是压缩文件的话,可以用unzipfile命令,从而减少手工操作的繁琐过程。比如,我们使用国泰安数据库的文件,由于从系统下载的原始数据文件都是压缩文件,所以使用这一对姐妹命令可以让过程机械化和简洁化。下面,我们通过一段程序来介绍这一命令的用法。
1、准备工作——构造子目录
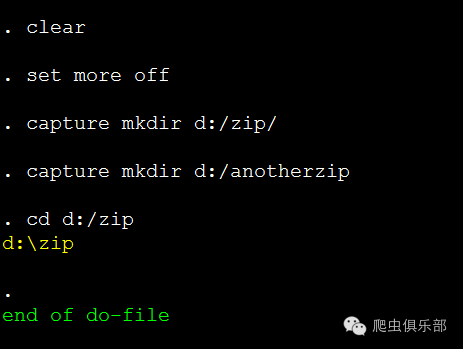
在正式调用之前,我们要为Stata准备一些用于压缩的文件。为此我们构造两个子目录d:/爬虫俱乐部/zip/和d:/爬虫俱乐部/anotherzip/,这一过程可以通过mkdir命令实现。构造子目录之后,我们用cd命令将d:/zip/设置为缺省子目录:
clear
set more off
capture mkdir d:/zip/
capture mkdir d:/anotherzip
cd d:/zip
2、准备工作——制造数据文件
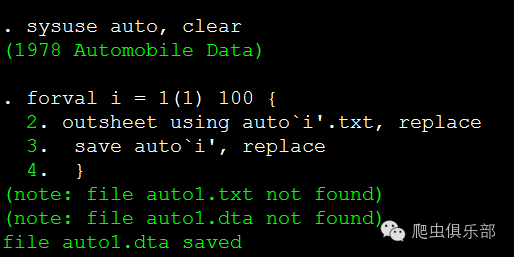
下面的过程将制造一些数据文件。我们将系统数据auto读入到内存中,然后通过一个100次的循环,给该数据构造了100个dta格式的副本和100个txt格式的副本,名字分别是auto1.dta~auto100.dta和auto1.txt~auto100.txt。
sysuse auto,clear
forval i = 1(1)100 {
outsheet using auto`i'.txt, replace
save auto`i', replace
}
此时,在我们的zip子目录下,就存在了我们所构造的200个数据文件。
3、文件压缩
调用zipfile命令进行压缩,该命令会从当前子目录下,挑选符合条件的文件进行压缩,并保存在saving()选项给出的压缩文件中。
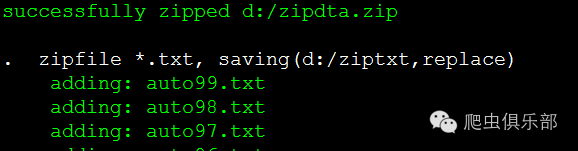
如下的第一条命令zipfile*.dta, saving(d:/zipdta,replace) 将当前目录下(d:/zip/)的dta文件(符合命名规则为*.dta的文件)进行压缩,压缩后的文件名是d:/zipdta.zip。请注意,这里我们将压缩后的文件保存在了d:/盘的根目录下,而不一定是当前的缺省子目录。
第二条命令我们仅仅压缩了那些txt文件。
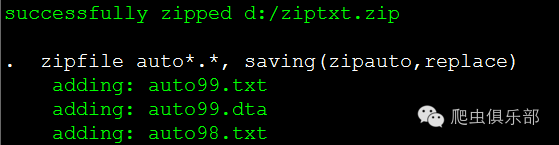
第三条第三条命令我们压缩了全部的文件名前四个字母是auto的文件,其实就是我们刚刚构造的200个文件,但是这时候,压缩文件没有设定路径,Stata将压缩文件zipauto.zip保存在当前子目录d:/zip/下。
zipfile *.dta, saving(d:/zipdta,replace) //设定了路径
zipfile *.txt, saving(d:/ziptxt,replace) //设定了路径
zipfile auto*.*, saving(zipauto,replace) //未设定路径

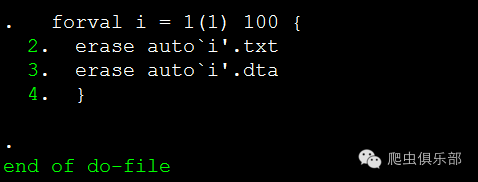
压缩完以后,d:/zip子目录下的数据文件就没有用了,我们可以用erase删除这些文件,这里我们再次启用了循环。
forval i = 1(1) 100 {
erase auto`i'.txt
erase auto`i'.dta
}
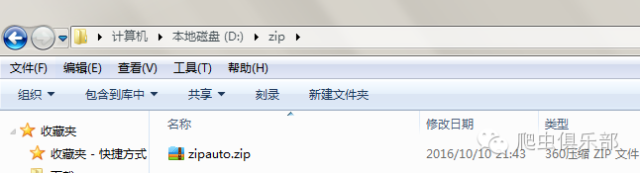
此时,在d:/盘的根目录下我们有两个压缩文件:

在d:/zip子目录下有一个压缩文件:
4、文件解压
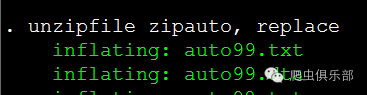
现在我们有了压缩文件zipauto.zip,该文件保存在当前缺省子目录下,可以调用unzipfile进行解压。注意,解压文件的时候,我们一定是将文件解压到当前子目录下。为了防止某一文件已经存在,我们用了replace选项。如下的命令将zipauto.zip解压到当前缺省子目录d:/zip/下。
unzipfile zipauto, replace
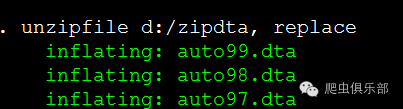
我们也可以将别的地方的压缩文件解压到当前的子目录下,比如下面的命令将d:/zipdta.zip解压缩到当前子目录d:/zip/下。
unzipfile d:/zipdta, replace
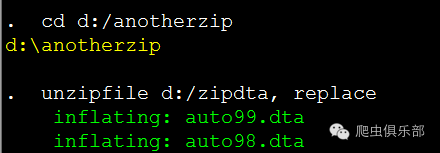
如果我们一定要将文件解压缩到一个特定的子目录,就一定先将该子目录设定为缺省子目录。比如如下的命令,首先将缺省子目录设定为d:/anotherzip/,然后将d:/zipdta.zip解压缩到该子目录。
cd d:/anotherzip
unzipfile d:/zipdta, replace
以上,zipfile&unzipfile就介绍到这里啦,是不是可以帮助到大家整理数据!几行的命令代替了繁琐的手动操作,爬虫酱幸福到飞起!诸君何不快来关注爬虫俱乐部,亿万人之中,我们只属于你!
clear
set more off
capture mkdir d:/zip/
capture mkdir d:/anotherzip
cd d:/zip
forval i = 1(1)100 {
sysuse auto, clear
outsheet using auto`i'.txt, replace
save auto`i', replace
}
zipfile *.dta, saving(d:/zipdta,replace)
zipfile *.txt, saving(d:/ziptxt,replace)
zipfile auto*.*, saving(zipauto,replace)
forval i = 1(1) 100 {
erase auto`i'.txt
erase auto`i'.dta
}
unzipfile zipauto, replace
unzipfile d:/zipdta, replace
cd d:/anotherzip
unzipfile d:/zipdta, replace
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑@付彩月)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。

长按二维码关注公众号呀

微信扫一扫
关注该公众号