秋风十里,不及Stata一个命令
有读者留言说用了许多的数据处理软件,还是觉得Stata最棒,恩,所以小编也会更努力地给大家分享好用的stata命令。
前几天一位Stata学习爱好者问到这样的一个问题:
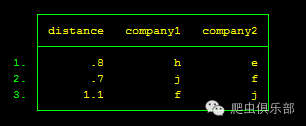
在这样一组数据中,distance指的是两家公司的距离,字符a-i分别指的是公司的名称。只要两家公司的distance=0时,我们就要将这company1与company2中出现的这两家公司名称的所在行进行删除,但并不只是删除distance=0的所在行。
来个栗子~我们可以看到第四行distance=0,分别对应的是g公司与c公司,那么我们就要将company1与company2中的g公司与c公司通通删除。
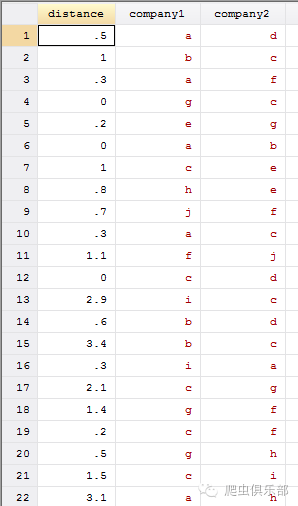
根据图示,我们需要的删除的所在行如下:
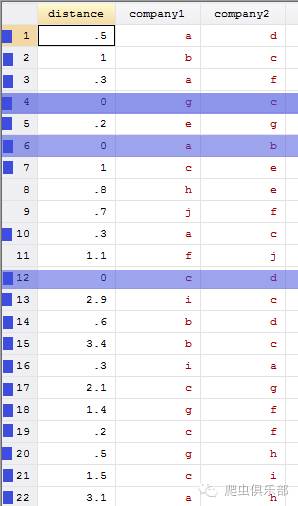
那我们该如何操作呢?
首先我们可以生成一个样本数据:

当然,我们不可能效仿上述的办法通过肉眼细看,手工来找出来这些公司。而且如果数据很多的情况下,手工删除工作量巨大,耗费精力,小编选择狗带。这时候我们开始心中默念“stata大法好”三遍。你以为这样数据就乖乖处理好了?图样图森破,接着往下看啊!
此时,我们可以做类似于一个抠字游戏,将distance=0的公司名称分别从company1与company2中抠出来,然后单独生成两个变量id1与id2记录下所抠出的字。命令如下:
gen id1=company1 if distance==0
gen id2=company2 if distance==0
list id1 id2
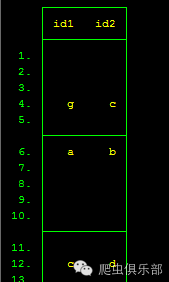
那么,我们是不是可以联想到高中数学中学过的元素与集合的知识,将抠出的公司名称看作为元素,分别封装于两个集合find1与find2中。这个时候,我们之前推送中提到过的levelsof命令便派上了用场。命令如下:
levelsof id1 ,local(find1)
dis `find1'
levelsof id2 ,local(find2)
dis `find2’
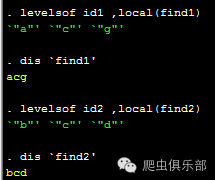
现在我们可以得到find1集合与find2集合中所出现的公司名字a、b、c、d、g,即find1 ∪ find2的结果。而我们则需要删除company1与company2中出现a、b、c、d、g公司的所在行。那么我们就要用到循环语句foreach来进行批量删除。
foreach find in `find1' `find2' {
drop if index(company1,"`find'")
drop if index(company2,”`find’”)
}
最后,我们可以整理一下数据,并得到我们需要的结果:
keep distance company1 company2
list distance company1 company2
当然,如果存在多家公司company1、company2、company3、company4等,我们也可以通过这样的思维方式,通过levelsof命令得到需要的元素,然后通过循环在find1∪find2∪find3∪find4∪…的集合中进行处理。
小技巧讲完了,数据剔除只需要计算机简单几步就可以解决,小编已搬好小板凳,准备边嗑瓜子边看计算机帮我处理数据了。什么?你也想边吃爆米花边玩转数据处理?那快来关注我们的公众号呀!
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @徐苾雯)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)如果大家遇到关于stata处理分析数据的问题,也可以给该邮箱写邮件,邮件名称为“提问”+“问题名称或者关键词”,我们会在后期的推文里给予解答。
长按二维码关注公众号哟

微信扫一扫
关注该公众号