虫文共享|我才不要YSL星辰,我要用word函数分列数据
最近小编的朋友圈被YSL限量版星辰唇膏刷屏,我们爬虫的圈子则不一样,刷屏的都是各种好用的stata命令,一看就和其他的妖艳贱货不一样啊有木有!今天我们又收到了来自于南开大学经济学院吴玉轩的投稿,一看就是我们的铁粉,手动比哈特~今天他和我们分享的是如何运用word函数将数据分列处理。
笔者在整理一份程序表格时遇到了这样一个问题:
笔者从Stata网站上获取了2000多条Stata最近更新的命令及程序解释,单词之间以空格分隔。如下图所示(列示前10个观测值,总共有2512个观测值),分别是程序的名称跟描述,笔者想将其分成两列,一列是程序的名称,另一列是程序的描述,方便以后的更新与查阅处理。笔者曾经试图使用excel的分列功能,依据空格分列,但是这样做存在的一个问题就是它会将程序的描述语句也会分成相应的列,这样很不利于阅读跟处理。So,问题归结起来就是,对于大量的文字记录,如何在第一个空格处分列而在其他空格处不分列?
于是乎,要祭出Stata的大杀器了。
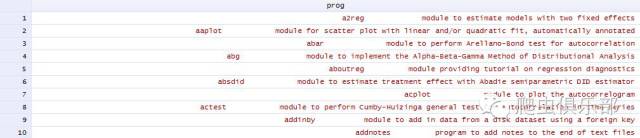
在Stata中真的需要用分列命令来实现该功能么?如果真这么做,Too young,too naive.其实只需要取出每个观测值的第一个单词(为啥不是提取字符,自己想一想),然后把第一个单词的位置替换成空值即可。一言不合,先上命令:

简要解释解释一下,利用word函数取出prog变量中的第一个单词,命名为pro;然后利用subinstr函数将prog变量中的第一个单词的位置替换为空值,生成变量pro_1,结果如图所示:

到这里就完事儿了么?讲真,当时我也想是这样,哈哈哈,too young...不妙,我们看到还有这样的观测值,在Stata里,>是用来续前行的,很明显,此处的两个观测值应该合并为一行,具体的,应该将下图中的92接到91后面。

这要怎么办呢?_n表示有办法!命令如下:
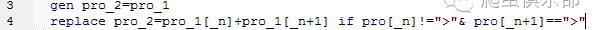
首先生成一个变量pro_2,然后当pro变量第n个不为>且第n+1个为>时将两个字符串相连,将92连到91后面(读者朋友可以自己思考一下,如果用n-1会怎样呢),结果如图所示,可以很明显看出,在第91条记录后面连接了第92条记录(i后面连接了mpro...),最后再将pro==>的记录删除即可。

所以,整个程序就是:
最后,可以输出到excel中根据需求进行个性DIY,方便以后的更新查阅及修改,当然这点仁者见仁,智者见智。值得注意的是,上述例子中在连接上下两个字符串时,在连接处会出现一个空格,造成有时一个单词会形成诸如“i mport”的现象,这是一点瑕疵吧,当然一般情况下对阅读的影响不大。
什么?还有人在和你说想要星辰唇膏?快让他们来关注我们的“爬虫俱乐部”公众号呀,有那么多简单实用的stata命令,还有心思想唇膏?昨天开始,我们的公众号已经开通了打赏功能~说得好就赏个铜板呗~有钱的捧个钱场,有人的捧个人场,最后的赞和赏,总有一个适合您,爬虫酱打滚求赏,在此谢谢大家的支持啦~
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @徐苾雯)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

长按二维码关注公众号
微信扫一扫
关注该公众号