谈恋爱不如stata
哈喽,诸君安,我是爬虫俱乐部编辑梅洁瓷傲公举。人说,人生苦短,要喝醉烈的酒,恋最美的人。然而人海茫茫,最美的人苦寻不着,你找啊找啊,等啊等啊,绕啊绕啊,浪啊浪啊的,耽误了这么长的一段时间啊,至今仍是一只傲娇的单身贵族(狗)。人生苦短啊!谈恋爱不如stata,没有soulmate的日子里,就让stata来爱你。好了,就让我们与stata相知相伴。
最近在statalist上看到有人提了一个问题,问题是酱婶儿的:
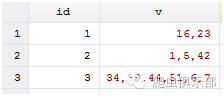
有这样一组数据,变量v里面包含了很多用逗号间隔的数字,如果想统计一下每个数字是否包含在这个变量里,并用一个0,1变量表示出来,比如:v_1=1表示变量v中出现了1,v_16=0表示变量v中没有16。
因为变量v里面包含的数字都是在1-51之间的,所以我首先是这样做的:
forvals=1(1)51 {
genv_`s'=strpos(v,"`s'")>0
}
结果是这样的:

然后我们就发现了一个问题,v_1 全部都是1,但事实上,只有id=2时变量v中才是真正有1,id=1和id=3时只是因为变量v中有16和51而被错误识别。真是磨人的小妖精。也就说只要变量v里面有1,10,11,21等这些数字,变量v_1就会显示为0,这并不是我想要达到的目的,那么如何解决这个问题呢?
那既然是这样,我先把变量v拆分一下,并把字符型变成数值型:
split v, gen(number) destringparse(",")
结果就是这样:

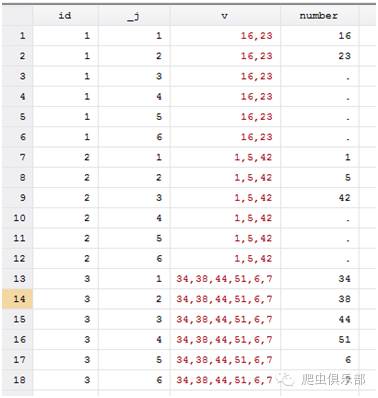
这跟我们平时所接触的数据形式有点不同,所以先把它变成长型的,命令为:
reshape long number,i(id) j(_j)
这样就变成了我们很熟悉的变量形式,变量v中包含的数字也全部被提取出来放到变量number中,我们可以借助number进行后面的工作。
我们最后要生成的v_xx这些变量,xx应该包括number里面的所有数字,我们可以把这些数字一个个地写上去,然后按照上面的foreach 循环,生成对应的变量,但是这样工作量比较大。这个时候我们可以考虑一下运用宏来解决问题,我们把number的内容赋给一个宏,后面再直接调用宏就可以获得number的内容,此时需要用到levelsof命令,这个命令的具体用法最后有提到。
levelsof number,local(options)
foreach i oflocal options {
egen byte v_`i' =max(number == `i'), by(id)
}
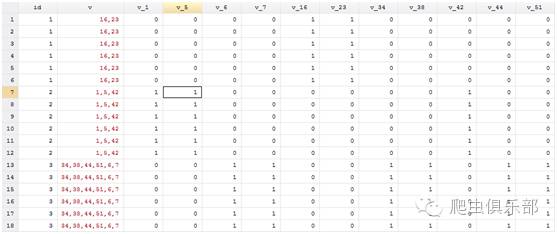
最后,因为只要id是一样的,其实后面的变量全都是一样的,所以把重复的行都删掉,只保留每一个id的第一行就可以了。
by id, sort: keepif _n == 1
运行完之后,结果就是我们想要的,而且也没有出现错把10,11当成是1的情况。我们这样做之后与原来的错误做法还有的一个区别就是生成的v_xx这些变量中,xx只包括v中出现过得数字,比如v中没有出现过21,那么就没有v_21这个变量,而按照第一种的错误做法是生成了v_1——v_51共51个新变量,所以新方法是最后的结果更简洁。

最后附上完整代码和levelsof的用法给大家。
代码:
clear
input byte idstr15 v
1"16,23"
2"1,5,42"
3"34,38,44,51,6,7"
end
*************************错误做法***************
forval s=1(1)51 {
gen v_`s'=strpos(v,"`s'")>0
}
**************************正确做法**************
split v,gen(number) destring parse(",") //把变量v拆分,并把拆分后的变量变成数值型
reshape longnumber, i(id) j(_j) //把数据变成长型数据
levelsof number,local(options) //把变量number 的内容赋给宏options
foreach i oflocal options {
egen byte v_`i' =max(number == `i'), by(id)
}
drop _j number
by id, sort: keepif _n == 1
Levelsof命令:

嗯哼,只需几个步骤,我们用stata辨识出了变量里有没有我们想要的数字。然而,拿什么寻找她,你的爱人?算了,憋找了,来学stata才是正经事。谈恋爱不如stata。
说的好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场,多赏多赞多转发。祝诸君都在或单身或恋爱的生活中找到足够的乐趣,不负此生。
我们团队原来的微信公众号是“数据处理援助中心”,现在正式搬家到“爬虫俱乐部”,欢迎关注。新的公众号开始,我们推出有问必答栏目,对您提出的问题,我们会尽力回答,并通过推文的形式进行发布。我们也欢迎各位粉丝向公众号投稿。
(编辑 @梅洁瓷傲)
欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

长按二维码关注公众号呀
微信扫一扫
关注该公众号