我来存储估计结果,您来选择输出方式
很久很久以前,有一位牛博士,做了一篇牛文章。一天他正在专心地做实证,突然收到一个好消息:“恭喜!您的文章已经通过专家匿名评审环节,拟被我刊录用。按照我刊习惯,请您将实证中的显著性标识输出到系数之后,并于今天下班前返回修改结果。”接到这个消息后,牛博士是既高兴,又发愁。
多好的事啊,还发愁?!原来,牛博士使用的样本量特别大,如果要是更改输出方式的话,就需要重新跑一次程序,这个过程大约需要耗时4-5个小时。如果说是手工复制粘贴输出的结果,既慢又容易出错。要如何处理这个问题呢?爬虫酱感慨道,如果他之前了解estwrite就好了!
estwrite是一个外部命令,可以将估计结果存储在后缀名为sters的文件中。使用estread命令,我们可以将估计结果读入Stata,然后任意更改输出方式。
安装estwrite命令:
ssc installestwrite
命令的格式如下,具体请
help estwrite:
estwrite [namelist using] filename [, id(varname) alt estsave replace append ]
estread [namelist using] filename [, id(varname) estsave describe ]
实例演示
estwrite存储估计结果
下面做两个回归,并将结果用estwrite存储:
clear
set more off
webuse nlswork,clear
xtset idcode year
qui tab year,gen(yd)
*回归1: 控制年份的OLS,对标准误进行聚类修正
reg ln_w age ttl_exp tenure not_smsa south yd*, vce(cluster idcode)
estadd local Cluster "Yes",replace
estadd local Year_FE "Yes",replace
estadd local Fixed_Effect "No",replace
est store m1
*回归2: 控制年份的面板固定效应模型,对标准误进行聚类修正
xtreg ln_w age ttl_exp tenure not_smsa south yd*, fe vce(cluster idcode)
estadd local Cluster "Yes",replace
estadd local Year_FE "Yes",replace
estadd local Fixed_Effect "Yes",replace
est store m2
使用estwrite命令存储估计结果:
estwrite * using mymodels
Stata返回信息,存储了两个回归的结果[m1和m2]以及一个sters文件[mymodels.sters]
实例演示
estread更改输出方式
假定在文章排版的时候,需要改变输出方式,这时候我们就可以通过estread调用mymodels.sters文件,使用esttab或estout输出结果:
clear
estread mymodels
*输出方式1
esttab m1 m2, star(* 0.1 ** 0.05 *** 0.01) compress nogap indicate("Year=yd*") ar2(%9.3f) title("Table1 Wage") mtitle("OLS" "FE")
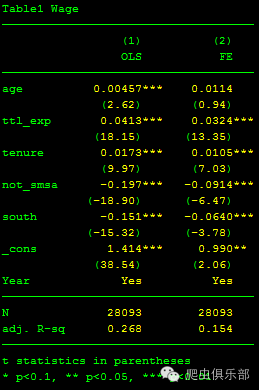
*输出方式2:
esttab m1 m2, star(* 0.1 ** 0.05 *** 0.01) staraux b(%6.3f) t(%6.3f) compress nogap drop(yd*) stats(Year_FE Fixed_Effect Cluster N r2_a, fmt(%3s %3s %3s %12.0f %9.3f)) varwidth(20) title("Table1 Wage") mtitle("OLS" "OLS" "FE")
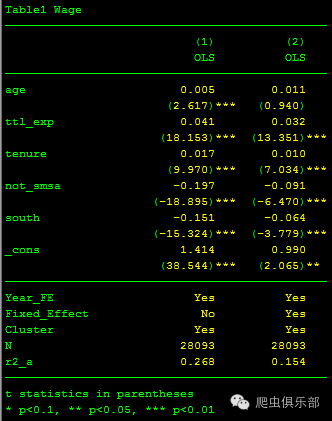
以上,就是我们今天和大家分享的全部内容。如果您对esttab和estadd命令不熟悉,还请参考往期推文--esttab功能挖掘:“Yes”or“No”。希望本次推送对您有所帮助,谢谢!
(编辑 @强宇曦)
那些让你具有高手气场的黑科技:
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。

长按关注你懂得哦~
微信扫一扫
关注该公众号