爬虫的套路之好事成“三”
在之前的推文虫文共享|我才不要YSL星辰,我要用word函数分列数据中, 笔者获取了2000多条Stata程序及描述语句,随后有筒子问我是怎么获取这么多程序的?哈哈,我是不会告诉你我是手动点了30多次鼠标获得哒(一本正 经脸)。但是为了提升逼格,今天就来讲讲如何利用网络爬虫来从网页获取这些程序,并进行相应的处理。俗话说:“好事成三”,本文来点儿套路,分三步走。
(一)网页获取数据
登录http://econpapers.repec.org/software/bocbocode/default.htm网站,如下所示: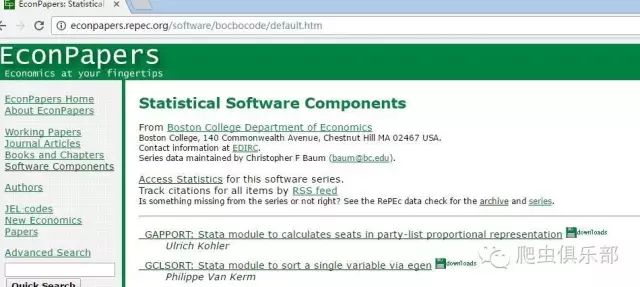
可以发现网站共有58个程序页面,网址
从http://econpapers.repec.org/software/bocbocode/default.htm到http://econpapers.repec.org/software/bocbocode/default57.htm。要获取网页数据,需要以下步骤:
1、copy源代码
利用copy命令把网页源代码保存下来,然后用infix命令将文件读入stata。
命令如下(文末有完整代码):

这样就用文本保存了网页代码,并读入stata。不过,当你用记事本打开的时候,一定是满脸懵逼状,so,浏览器打开试一下,以IE为例,依次点击“查看-源”,如下图所示:

2、分析网页源代码
我们看到,所需要的程序名称及描述语句字段前面都有<dt><ahref=这一串字符,与其他显著不同,因而只需保留这些字段的记录即可,利用index函数把这些用<dt><a href=代号标记的记录值保存下来,命令:
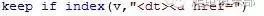
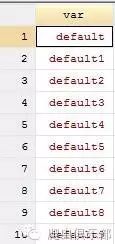
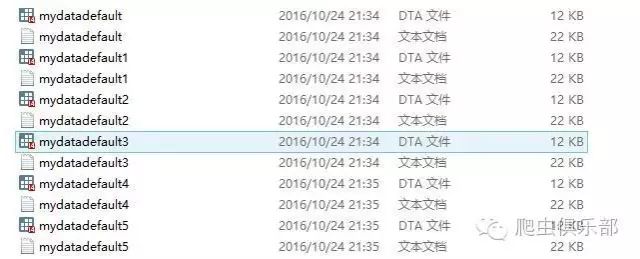
对于所有58个网页,可以利用levelsof命令,进 行local(暂元)循环,具体的,笔者生成了一个var_name.dta文件,如下(共有58个观测值,仅列示前10个),然后依次按照名称代入暂元 进行循环,这样就依次把58个网页的数据内容抓取下来,形成58个dta文件,第一部分的代码如下,并附上部分文件截图:

(二)数据合并
这一步最简单粗暴,哈哈,append。

(三)数据处理
先看一下所得数据格式:

通过观察,可以先以“>”对字符串进行分列,将变量v分为v1-v6,我们需要的是v3,v4;然后可以对v3再以“<”分列,分成v31跟v32,对v31的空值以v4的相应字符串填充,代码如下:
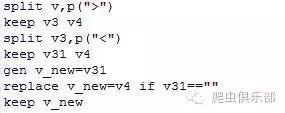



相应的得到以下结果:

对这一部分可以再以“:”分列,同时对于程序名称,可以再利用upper函数变成小写字符,最终得到的结果如下:

至于变量名称,可能与前面的推文有所差异,但没太大影响。
完整代码
*(1)网页爬虫
use "d:\stata14\ado\mydata\var_name.dta",clear
levelsof var,local(levels)
foreach v of local levels {
copy "http://econpapers.repec.org/software/bocbocode/`v'.htm"d:\stata14\ado\mydata\mydata`v'.txt,replace
infix strL v 1-200000 using d:\stata14\ado\mydata\mydata`v'.txt, clear
keep if index(v,"<dt><a href=")
save d:\stata13\ado\mydata\mydata`v' ,replace
}
*(2)数据追加合并
use d:\stata14\ado\mydata\mydatadefault.dta,clear
forvalues i=1/57{
append using d:\stata14\ado\mydata\mydatadefault`i'.dta
}
*(3)数据处理
split v,p(">")
keep v3 v4
split v3,p("<")
keep v31 v4
gen v_new=v31
replace v_new=v4 if v31==""
keep v_new
split v_new,p(":")
gen v_name=lower(v_new1)
rename v_new2 v_des
keep v_name v_des
gen pro=word(v_des,1)
keep if pro=="Stata"
sort v_name
drop pro
order v_name v_des
save d:\stata14\ado\mydata\mydata_finish ,replace
值得注意的是,在爬虫的过程中,因为网速及服务器访问速度的问题,有时stata会报错,因此由于条件限制,可以分几次抓取,比如我想先抓前25个页面,利用preserve restore命令,第一部分可以写做:
use "d:\stata14\ado\mydata\var_name.dta",clear
preserve
keep in 1/24
levelsof var,local(levels)
foreach v of local levels {
copy "http://econpapers.repec.org/software/bocbocode/`v'.htm"d:\stata14\ado\mydata\mydata`v'.txt,replace
infix strL v 1-200000 using d:\stata14\ado\mydata\mydata`v'.txt, clear
keep if index(v,"<dt><a href=")
save d:\stata14\ado\mydata\mydata`v' ,replace
}
restore
终于得到了需要的文件mydata_finish,想想还有点儿小激动呢,哈哈哈。我走过的最长的路就是Stata的套路,爬虫也可以有套路,现在逼格是不是又提升了呢!哈哈,相约stata,下次再会。
(编辑 @强宇曦)
那些让你具有高手气场的黑科技:
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。

长按关注你懂得哦~
微信扫一扫
关注该公众号