朝花夕拾|新浪网上市公司公告整理
当当当,今天我们的爬虫俱乐部又开通了一个新的板块——朝花夕拾。近日,有读者朋友反映说在我们原来的公众号里还有许多好玩的命令没有学完,贴心的爬虫酱将会在这个板块中给大家推送一些之前好用的命令,既方便我们的老朋友们继续熟悉那些有用的命令,也帮助新来的小伙伴们学习新的技巧。
文章来源:数据处理援助中心公众号 已获得授权
今天这篇推文介绍如何从Sina网将上市公司的公告信息一条条整理列表出来。喜欢网络数据整理Stata编程的朋友们收好今天的推文哟。
先看看一个公告的页面吧,以长江电力的最新公告为例:长江电力公司公告的第二页的地址是:
http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletin.php?stockid=600900&Page=2
长江电力公司公告的网页如下,但是我们需要的信息只是被high light的部分:

长江电力有很多公告,每页显示30行,我们可以点击下一页进入下一个页面,也可以直接将地址栏的最后面page=2修改为page=3, page=30等进入下一个页面。最后一个页面的地址和页面展示如下:
http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletin.php?stockid=600900&Page=31
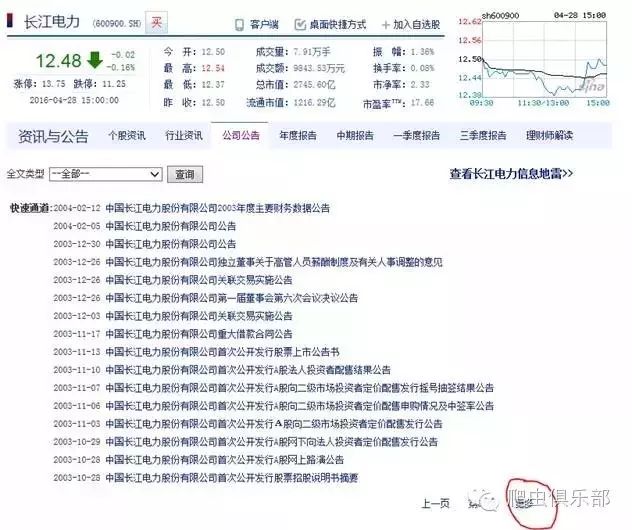
这个页面显示的公告数量不足30行了,而且也没有“下一页”选项了。
如果我们将地址栏的股票代码“stockid=600900”修改为“stockid=000002”则得到万科公司的公告信息的网址和页面信息如下:
http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletin.php?stockid=000002&Page=36

万科的最后一页可是第36页呀!说明万科信息披露次数较多吧。如果我们执迷不悟地将这个地址的page=36硬是改成page=37,我们将得到如下的页面:

好吧,现在你知道如何找到每家公司的公告信息了,只要你在地址栏中将地址替换成对应的股票代码和公告信息页码即可。可是我们怎么能将这些公告页面复制到我们的excel表格中呢?难道是使用复制粘贴的快捷键“ctrl+c”和“ctrl+v”吗??这个方法当然可以了,可是算算你需要多少时间吧!3000家上市公司,加入每家公司有30页,假如每处理一个页面需要20秒钟,一共耗时3000x30x20/3600=500小时,假如你连续高强度劳动,每天工作8小时,需要62.5天,如果你需要双休日,好吧,3个月时间过去了!这里还没有考虑你需要在复制粘贴以后给每页添加一个股票代码的时间。而且这里并没有给你提供公告的具体内容,你要看具体内容恐怕还需要将一个个链接打开。你就别任性了,不要认为你勤能补拙好不好。
这个工作需要计算机来完成,Stata可以帮助我们用非常简单快捷的方式完成。首先介绍一个能帮助我们完成这个任务的Stata命令:copy。好吧,就是这么一个及其简单的命令,可以帮我们上网,将网页的内容copy到计算机硬盘里:
copy http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletin.php?stockid=600900&Page=1d:/temp.txt, replace
现在就将长江电力的第一页公告保存到d:/temp.txt了。打开看看吧,不是网页,而是网页的源代码:
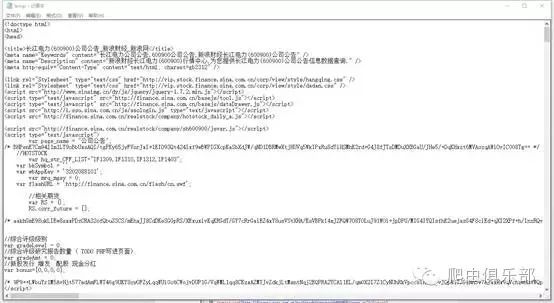
如何在浏览器中查看源代码呢?直接在浏览器中点击右键查看源,好吧,你能看到如下的页面信息:
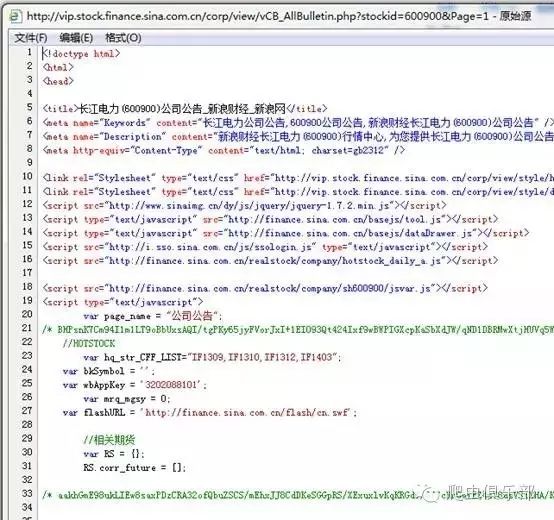
我们需要的信息在第691行。

可以用infix读入我们copy到电脑上的源代码,然后直接保留第691行,命令如下:
infix strL v1-20000 using d:/temp.txt, clear
keep in 691
现在你的Stata中只有一个变量v,这个变量有一个观测值,是一个很长的字符串,具体内容包括每次公告的日期、公告内容的标题和链接地址,中间有一些制表符,分别是:
<atarget='_blank' href='
'>
</a><br>
我们可以将这些分隔符专门用高亮度显示出来,截取中间一部分代码如下:
2016-04-15 <atarget='_blank' href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2352193'>长江电力非公开发行人民币普通股(A股)募集资金验资报告</a><br>2016-04-15 <atarget='_blank' href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2352190'>长江电力发行股份及支付现金购买资产并募集配套资金发行结果暨股本变动公告</a><br>2016-04-15 <atarget='_blank' href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2352189'>长江电力:中信证券股份有限公司、华泰联合证券有限责任公司关于中国长江电力股份有限公司发行股份及支付现金购买资产并募集配套资金暨关联交易实施情况之独立财务顾问核查意见</a><br>2016-04-15 <atarget='_blank' href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2352188'>长江电力发行股份及支付现金购买资产并募集配套资金暨关联交易实施情况报告书</a><br>2016-04-15 <atarget='_blank' href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2352187'>长江电力验资报告</a><br>
如果这时候我们用“</a><br>”作为分隔符,可以将上面的长长字符串分割为30段,代表30条公告信息,对应的命令是:
split v, p("</a><br>")
drop v
然后内存中存在如下的变量,v1 v2 v3-v31
我们可以用sxpose, clear将这一行31列变量进行转置,变成一列31行的一个数据,变量名是_var1。

由于之前分割出来的变量中,第31个变量为无用的内容“</ul>”。

因此在转置后我们需要删除最后一行:
drop in -1
最后我们要将这个变量的字符串用split拆开,具体命令是:
split _var1, p(" <a target='_blank'href='" `"'>"’)
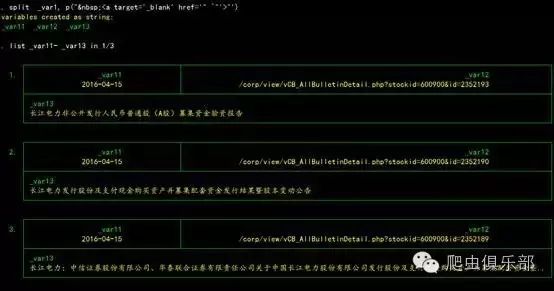
这时候我们就将这30行一列的信息拆细成30行3列,分别是公告日,标题和网页地址。
具体的处理程序如下:
clear
*copy"http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletin.php?stockid=600900&Page=31"d:/temp.txt, replace
local sina1"http://vip.stock.finance.sina.com.cn/corp/view/"
local sina2"vCB_AllBulletin.php?stockid="
copy"`sina1'`sina2'600900&Page=31" d:/temp.txt, replace
infix strL v1-200000 using d:/temp.txt, clear
keep ifindex(v," <a target='_blank' href='")
if _N==2 {
drop in -1
}
splitv,p("</a><br>")
drop v
sxpose, clear /*besure to install sxpose, ssc install sxpose*/
drop in -1
rename _var1 var
splitvar,p(" <a target='_blank' href='" `"'>"')
drop var
rename var1 date
rename var2 url
rename var3 title
replace url ="http://vip.stock.finance.sina.com.cn"+url
save d:/网络数据/独董辞职/600900_2,replace
进一步的工作就是将长江电力的31个网页抓取整合起来,或者进一步将所有上市公司的网页全部抓取下来,这需要两层循环而已,读者可以自己去琢磨。
以上的内容就是关于Stata网络爬虫技术的初步内容。朝花夕拾,旧文重提。我们的公众号搬家已经有一段时间啦,读者朋友们不用再辛苦穿梭于两个公众号之间,爬虫俱乐部将不定期回顾之前公众号中有用的文章,满足大家的需求。说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场,点赞打赏,且随心意。今朝点滴,让我们更进一步;他年涌泉,更好的文章给更好的你。
往期推文推荐:
8.爬虫俱乐部周末送大礼——chinagcode提取中文地址经纬度
12.I have a Stata, I have a python
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。

长按二维码关注我们哟
微信扫一扫
关注该公众号