删繁就简三秋叶,subinfile似剪刀
诸君安。日前与诸君分享了新浪网上市公司公告整理的案例。然而命令繁冗,实在耽误大家搞事情。为此,今天我们给大家就新浪网上市公司公告整理的案例介绍subinfile的用法,大家可与往期文章朝花夕拾|新浪网上市公司公告整理相对比,具体感受一下subinfile删繁就简的实力。

以长江电力的最新公告为例:长江电力公司公告的第二页地址是:http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletin.php?stockid=600900&Page=2
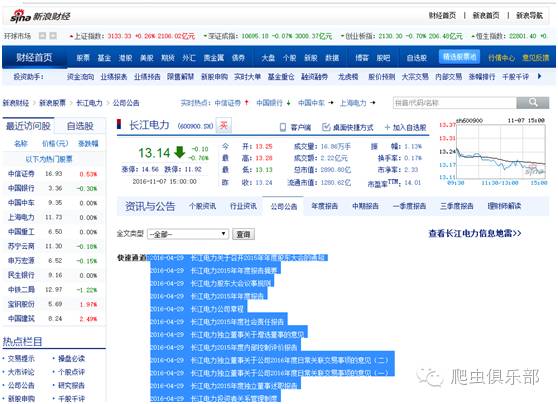
1、copy网页源代码
首先我们用copy命令将网页的内容copy到计算机硬盘并进行转码:
clear
set more off
capture mkdir c:/公告/
cd c:/公告/
copy"http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletin.php?stockid=600900&Page=2"c:/公告/temp.txt, replace
unicode encoding set gb18030
unicode translate temp.txt, transutf8
unicode erasebackups, badidea
打开c:/公告/temp.txt,copy到电脑上的源代码就一目了然了
2、保留所需信息源代码
根据我们所需的信息,我们可以找到其在网页源代码中的位置,如下:
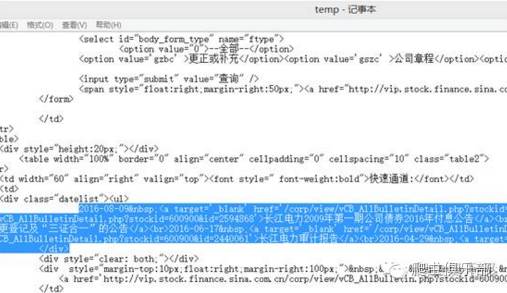
因此,我们只需保留该部分即可,而subinfile之保存功能可以帮我们保留文本文档中含有某个字符串的行。我们所要保留的部分有没有特定的字符串呢?通过分析可知,其均含有如下high light的字符串:
2016-08-09 <atarget='_blank'href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2634052'>长江电力关于向湖北省抗洪救灾捐款的公告</a><br>2016-08-09 2016-08-09 <atarget='_blank'href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2634052'>长江电力关于向湖北省抗洪救灾捐款的公告</a><br>2016-08-09 <atarget='_blank'href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2634051'>长江电力第四届董事会第十二次会议决议</a><br>
Subinfile满足使用条件!开工!
subinfile temp.txt, index(<atarget='_blank' href='/corp/view/vCB_AllBulletinDetail.php?stockid=) replace
执行结果如下:
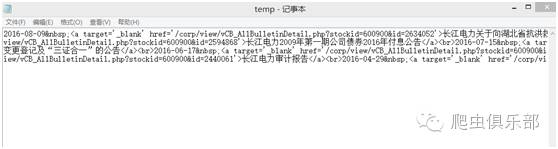
Subinfile成功帮我们保留了所需信息,包括每次公告的日期、公告内容的标题和链接地址,但中间有一些制表符是我们不想看到的,分别是:
<atarget='_blank' href='
'>
</a><br>
以及文末格格不入的</ul>
我们可以将这些分隔符high light出来,截取一部分代码如下:
2016-04-29 <atarget='_blank'href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2438452'>长江电力第四届董事会第十次会议决议公告</a><br>2016-04-29 <atarget='_blank' href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2438451'>长江电力控股股东及其他关联方资金占用情况的专项说明</a><br>2016-04-29 <atarget='_blank' href='/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2438450'>长江电力2016年第一季度报告</a><br> </ul>
而分隔符所隔开的正是我们想要整理列表出来的一条条信息,想想若我们用subinfile之替换功能将繁琐的分隔符替换为简单的”;”,subinfile之删除功能让格格不入的字符串消失,我们的源代码文件岂不是更清晰明了?
subinfile temp.txt, from(</a><br>) to(;;) replace
subinfile temp.txt, from( <atarget='_blank' href=') to(;) replace
subinfile temp.txt, from('>) to(;)replace
subinfile temp.txt, from(</ul>)replace
(</a><br>所隔开的是两个公告的内容,我们将其替换为;;,为了相区分,我们将每条公告内的分隔符 <atarget='_blank'href=''>换为;)
摘取部分处理过后的文件如下:
2016-04-29;/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2438452;长江电力第四届董事会第十次会议决议公告
;;2016-04-29;/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2438451;长江电力控股股东及其他关联方资金占用情况的专项说明
;;2016-04-29;/corp/view/vCB_AllBulletinDetail.php?stockid=600900&id=2438450;长江电力2016年第一季度报告;;
subinfile通过替换、保留、删除功能帮助我们对长江电力第二页公告的源代码文件做完了全部的修改工作,剩下的就交给infix导入修改完成的文件,split将所需变量公告日期、公告标题和链接地址拆分出来:
infix strL v 1-20000 using temp.txt, clear
split v, parse(;;)
drop v
sxpose, clear
rename _var1 v
split v, parse(;)
drop v
compress
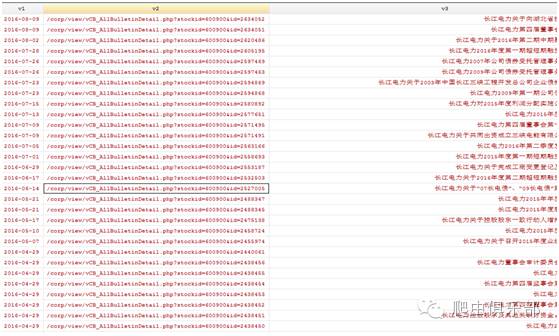
至此,我们以长江电力第二页公告为例的内容整理工作就结束了,工整的数据就在眼前~赶快试试吧!
clear
set more off
capture mkdir d:/公告/
cd d:/公告/
copy"http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletin.php?stockid=600900&Page=2"d:/公告/temp.txt, replace
unicode encoding set gb18030
unicode translate temp.txt, transutf8
unicode erasebackups, badidea
subinfile temp.txt, index(<a target='_blank'href='/corp/view/vCB_AllBulletinDetail.php?stockid=) replace
subinfile temp.txt, from(</a><br>) to(;;) replace
subinfile temp.txt, from( <atarget='_blank' href=') to(;) replace
subinfile temp.txt, from('>) to(;)replace
subinfile temp.txt, from(</ul>)replace
infix strL v 1-20000 using temp.txt, clear
split v, parse(;;)
drop v
sxpose, clear
rename _var1 v
split v, parse(;)
drop v
compress
编辑by梅洁瓷傲

往期推文推荐:
8.爬虫俱乐部周末送大礼——chinagcode提取中文地址经纬度
12.I have a Stata, I have a python
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号