朝花夕拾|生成交叉变量和非线性关系
今天是朝花夕拾板块的不定期更新时间。不管你是想温习我们之前推送的命令,还是要学习新的技巧,都且听小编慢慢道来。
文章来源:数据处理援助中心公众号 已获得授权
在回归模型中,我们经常会用到交叉变量,考察核心解释变量与某控制变量的交叉效应,或者用解释变量的高次项来刻画与被解释变量的非线性关系。今天的推文我们简单介绍如何在回归中生成交叉变量和二次项。
webuse fvex,clear
des
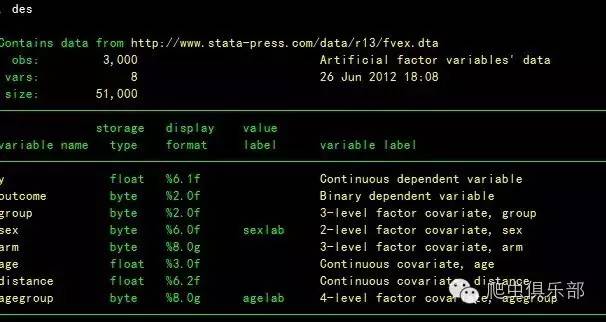
其中sex表示性别,是虚拟变量;age和distance分别表示年龄和距离,是连续变量。
首先,我们生成虚所拟变量与连续变量的交叉项。当然可以通过gennerate新的变量表示交叉项,但也有更简便的方法。虚拟变量用i作前缀,连续变量用c作前缀,用#表示两个变量的交叉变量:
reg y i.sex#c.distance age
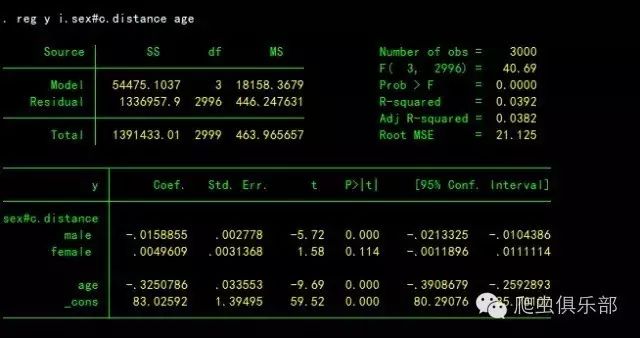
回归结果显示,对于male来说,distance负向影响y,对于female来说,distance正向影响y。上面的回归只纳入了交叉变量,并未纳入独立的虚拟变量。在命令中,使用##,可以将虚拟变量本身加入回归模型:
reg y i.sex##c.distance age
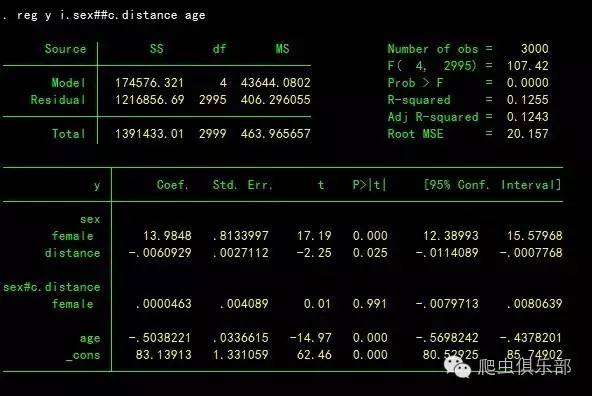
回归结果显示,female的distance对y的影响比male高0.0000463。
当然,我们也可以使用两个连续变量的交叉项:
reg y i.sex c.distance##c.age
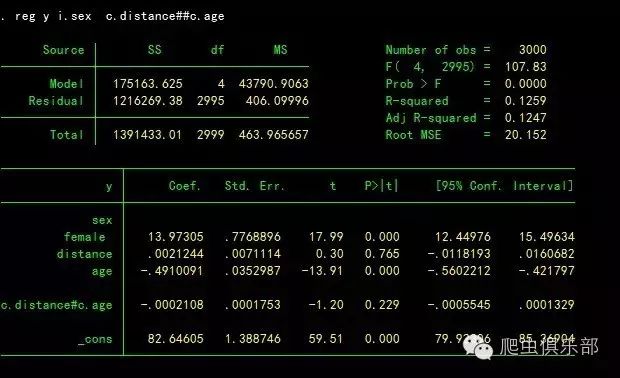
假定我们认为y与distance的关系是非线性的,可以尝试把distance的二次项放进回归模型。二次项就相当于distance与distance的交叉。
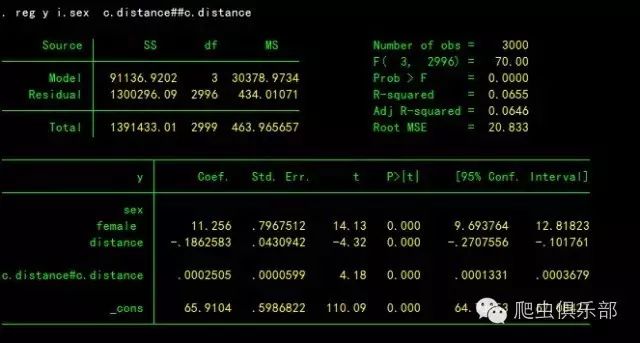
我们可以看到结果中distance一次项系数为负,二次项系数为正,且都显著,表明distance对y的影响是非线性的。只有当distance大于某个临界点时才会对y有正的影响;当distance小于某个临界点时,其对y的影响是负的。
以上的内容就是生成交叉变量和非线性关系的小技巧。朝花夕拾,旧文重提,希望我们“朝花夕拾”不定期的更新能满足大家的需求。说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场,点赞打赏,且随心意。今朝点滴,让我们更进一步;他年涌泉,更好的文章给更好的你。
往期推文推荐:
7.爬虫俱乐部周末送大礼——chinagcode提取中文地址经纬度
10.I have a Stata, I have a python
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。

欢迎关注爬虫俱乐部
✬如果你喜欢这篇文章,欢迎分享到朋友圈✬
评论和打赏功能都已开启,灰常接受一切形式的吐槽和赞美
微信扫一扫
关注该公众号