我知道你的城市空气质量
秋冬是雾霾的高发季节,网上各式的雾霾段子体现了全国人民对雾霾的“热情”。小编关心关心雾霾,关心stata,更关心你。之前的推文中已经多次介绍到用subinfile命令替换、保留、删除数据,今天我们就使用stata的subinfile命令获取你城市的空气质量,让你提前做好准备防雾霾。
昨天,小编在编辑时发生了程序错误的情况,所以今天把正确的程序再和大家分享一次,和大家道歉啦~昨天小编少吃了一顿肉惩罚自己,请各位读者要保持对我们的爱哟。小编会更加用心给大家做推送哒~

我们任意打开天气网一个地区的空气质量查询情况http://www.tianqi.com/air/naqu.html
页面是这样的:
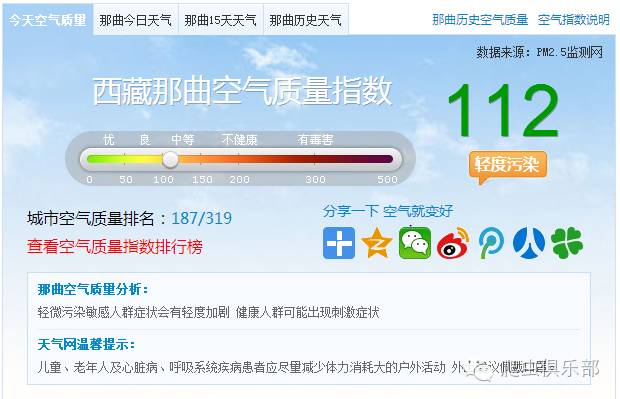
如何获取这样一个城市的空气质量指标呢?现在我们一步一步进行:


Copy网页源代码
首先我们用copy命令将网页的内容copy到计算机硬盘并进行转码
clear
set more off
cd D:\stata空气质量
copy "http://www.tianqi.com/air/naqu.html" "D:\stata空气质量/naqu.txt", replace
unicode encoding set gb18030
unicode translate naqu.txt, transutf8
unicode erasebackups, badidea

保留所需信息代码
以那曲天气为例,我们打开其网页源代码,通过分析我们找到显示空气质量的源代码的位置如下:
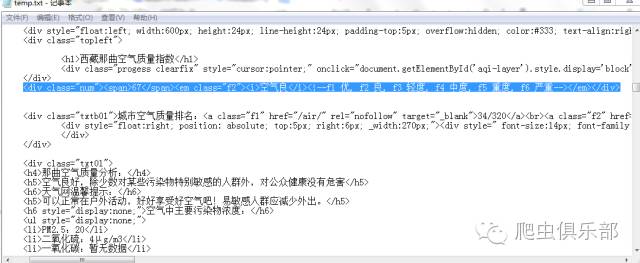
因此,我们只要保留该部分即可,这时候就要用上我们的subinfile命令
subinfile naqu.txt, index("<!--f1 优, f2 良, f3 轻度, f4 中度, f5 重度, f6 严重-->") replace
结果就是这样的啦:

我们将“<i>”替换成“;”便于导入Stata后进行拆分,再将其他的尖括号中的内容用正则表达式全部替换掉。
用subinfile命令可以写成这样:
subinfile naqu.txt, from("<i>") to(";") replace
subinfile naqu.txt, from(<.+?>) fromregex replace
当然,我们可以把前两个命令写在一起,变成:
subinfile naqu.txt, index("<!--f1 优, f2 良, f3 轻度, f4 中度, f5 重度, f6 严重-->") from("<i>") to(";") replace
subinfile naqu.txt, from(<.+?>) fromregex replace
这时候我们的读者朋友肯定有问题了
问:爬虫酱,我需要获得多个城市的空气质量指数要可以通过这样的方式获取吗?
答:当然可以!爬虫酱现在就给你展示stata的强大作用。
需要获得多个城市的空气质量指数情况,那我们只需要在刚刚的程序中输入需要的所有城市名称,加入一个小小的循环,就可以实现了。我们以西藏各个地市的空气质量情况为例:
Copy网页源代码
保留所需信息代码
clear
set more off
cd D:\stata空气质量
foreach city in naqu lasa changdu linzhi rikaze shannan{
clear
copy "http://www.tianqi.com/air/`city'.html" "`city'.txt", replace
unicode encoding set gb18030
unicode translate `city'.txt, transutf8
unicode erasebackups, badidea
di "`city'"
subinfile `city'.txt, index(`"<!--f1 优, f2 良, f3 轻度, f4 中度, f5 重度, f6 严重-->"') from("<i>") to(";") replace
subinfile `city'.txt, from(<.+?>) fromregex replace
infix strL v 1-2000 using `city'.txt, clear
gen city = "`city'"
save `city'.dta,replace
}
注意:因为我们加入了一个循环,所以将网页中各地市的名称替换为宏`city’,按照我们之前处理单个城市的套路,通通丢进我们的循环就好啦。此时我们生成了一个新的变量用于放置每个城市名称,让我们的结果看上去更清楚明了。
数据整合
为了方便我们的观察,我们将不同的城市中的数据黏贴到一张表中,这时我们就用到之前推文中介绍到的openall命令(对于命令详细地使用请移步推文送你一只粘合剂——用openall命令合并数据)
openall *
我们看到结果是这样的: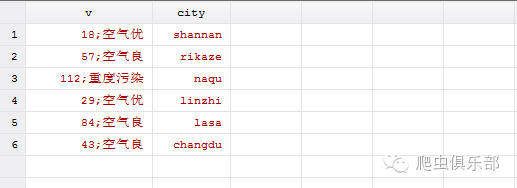

数据拆分
以上我们就完成了对所需要城市空气质量数据的保留、删除和整合。接下来我们就用split将所需要的空气指数和空气质量拆分出来:
split v,parse(";")
drop v
rename v1 index
rename v2 quality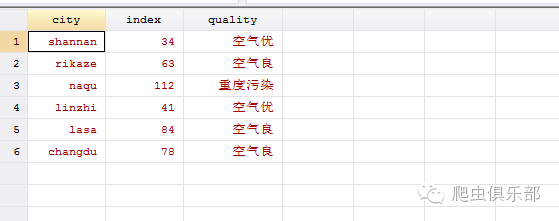
你们看,我想知道的城市的空气质量就清楚地展现在眼前啦。

另附多城市版完整程序:
clear
set more off
cd D:\stata空气质量
foreach city in naqu lasa changdu linzhi rikaze shannan{
clear
copy "http://www.tianqi.com/air/`city'.html" "`city'.txt", replace
unicode encoding set gb18030
unicode translate `city'.txt, transutf8
unicode erasebackups, badidea
di "`city'"
subinfile `city'.txt, index(`"<!--f1 优, f2 良, f3 轻度, f4 中度, f5 重度, f6 严重-->"') from("<i>") to(";") replace
subinfile `city'.txt, from(<.+?>) fromregex replace
infix strL v 1-2000 using `city'.txt, clear
gen city = "`city'"
save `city'.dta,replace
}
openall *
split v,parse(";")
drop v
rename v1 index
rename v2 quality

分享了空气指数获取方法
现在
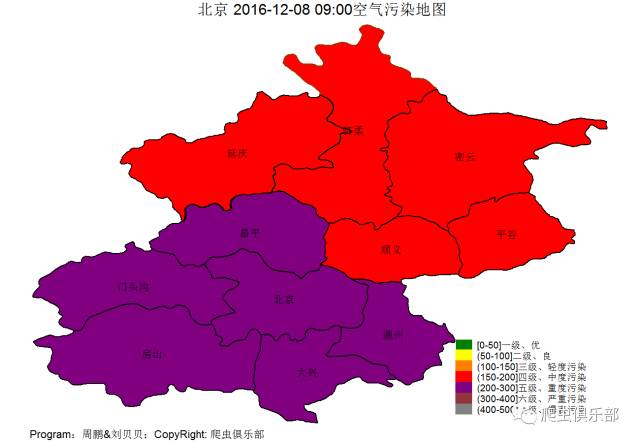
我们关注一下空气质量地图
总的空气质量如下图

今天点名批评
北京
以上就是今天给大家分享的内容就是这些了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~,点赞打赏随您心意,么么哒~
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
编辑 by 徐苾雯

往期推文推荐:
7.爬虫俱乐部周末送大礼——chinagcode提取中文地址经纬度
10.I have a Stata, I have a python
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号