有问必答之数据处理
哈喽,诸君安。自从我们公众号推出有问必答栏 目,陆陆续续有很多朋友向我们投来自己的问题。我们本着有问必答的态度,认真对待每一个问题,并及时帮大家解答疑惑。近日,一位朋友在做一个关于环境监测 的研究时,由于数据是从各个政府网站上下载下来的,所以格式都十分的杂乱,用stata处理数据时遇到了一些问题不知如何解决。

问题有点复杂,大概是酱婶的:
第一
原始数据包括23个excel文件,合并时出现了问题。
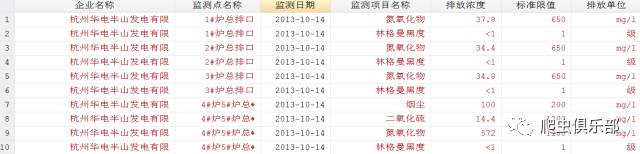
首先,由于数据是从各个政府网站上下载下来的,所以日期格式不一,比如2013年7月21日、2013/7/21、2013-7-21 00:00:00等格式。另外这23个excel文件中变量名称也是不相同的。所以在合并时会出现问题。如下图所示:

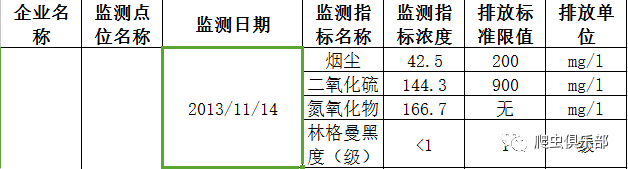
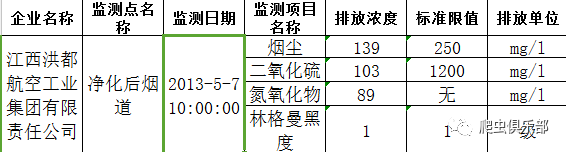
上述图片只列出来部分数据,可以看到,除了日期格式不一样外,变量名称也不尽相同。所以在合并之前:1.对各种日期格式进行处理;2.统一变量名称
程序如下:
clear
set more off
cd d:/废气
local files:dir "." file "*.xls" // 提取我们需要的文件名
dis `"`files'"'
foreach file in `files'{
import excel using `file',first case(lower) clear
cap rename 监测点位名称 监测点名称
cap rename 监测指标名称 监测项目名称
cap rename 排放限值 标准限值
cap rename 排放标准限值 标准限值
cap rename 监测指标浓度 排放浓度
cap rename 监测标准限值 标准限值 //统一23个文件的变量名称
cap split 监测日期, p("")
cap replace 监测日期=监测日期1
cap drop 监测日期1
cap drop 监测日期2
cap gen newdate=date(监测日期,"YMD") //处理类似2013-7-21 00:00:00格式的日期,只保留2013-07-21
cap destring 监测日期,ignore("/") replace // 处理类似2013/7/21/格式的日期
cap destring 监测日期,ignore("-") replace // 处理类似2013-7-21格式的日期
cap replace 监测日期=newdate
cap drop newdate
cap format 监测日期 %dCY-N-D //统一日期格式为%dCY-N-D
save "`file'.dta",replace
}
运行完上述程序,我们就得到了23个日期格式相同且变量名称相同的.dta文件。如图所示:
接下来就可以用openall命令把这23个dta文件进行纵向合并。用openall命令进行数据合并时,能简化程序。(具体详见往期推文送你一只粘合剂——用openall命令合并数据)
程序如下:
cd d:/废气
openall * // 纵向合并23个dta文件
结果如下:
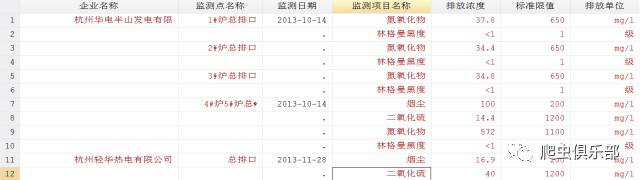
第二
由于变量企业名称、监测点名称、监测日期在Excel中有很多值是合并单元格的形式,转成.dta后只有第一行有数据,所以我们需要填充缺失值。使用carryforward命令非常便捷。
首先,需要下载carryforward命令:
ssc install carryforward
命令如下:
keep 企业名称-排放单位
carryforward 企业名称 ,gen(firm_name)
carryforward 监测日期 ,gen(monitor_date)
carryforward 监测点名称 ,gen(monitor_name) // 补全缺失值
replace 企业名称=firm_name
replace 监测日期=monitor_date
replace 监测点名称=monitor_name
drop firm_name monitor_date monitor_name
order 企业名称 监测点名称 监测日期 // 为了方便研究,使数据与原始数据的变量名称和顺序保持一致
这样就填充了缺失值。但是发现了监测日期中有一部分不是%dCY-N-D,而是一些非常大的数字。如下图所示:
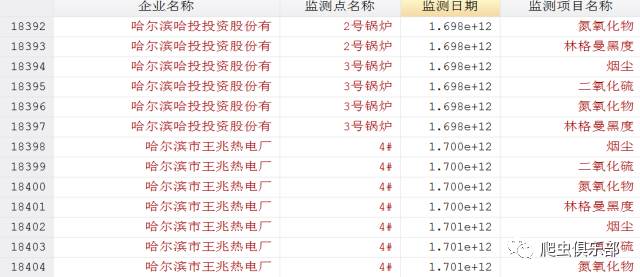
出 现这种情况是因为这一部分数据的日期格式为%tc,也就是这些数字表示的是毫秒数,(数据单位为毫秒、日、周、季度、半年、年,相应的函数为tc()、 td()、tw()、tq()、th()、ty(),以及相应的格式为%tc、%td、%tw、%tq、%th、%ty)所以这里我们需要将毫秒转变为天 数。
replace 监测日期=int(监测日期/86400000) in 18242/18651 // 部分日期格式为%tc
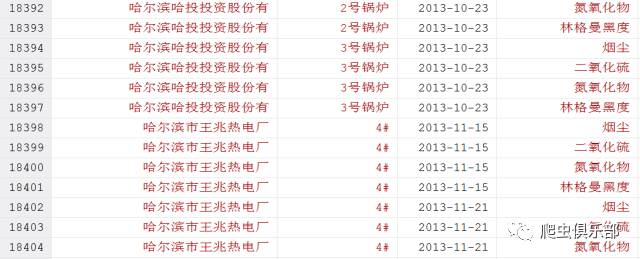
这样所有所有数据的日期格式都变成一致的了。之后的研究需要用到按季度显示的日期。
gen yq=yq(year(监测日期),quarter(监测日期))
format yq %tq
order 企业名称 yq 监测点名称 监测日期
第三
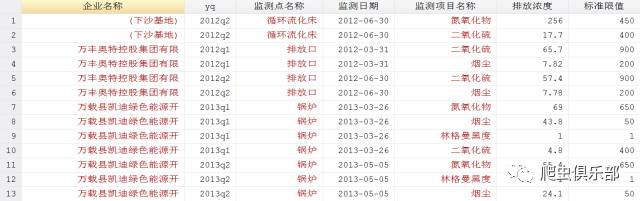
变量排放浓度所在列有”<”这样的字符,这会影响接下来的计算,我们需要把”<”全部拿掉。然后将排放浓度,标准限值由字符型转为数值型。
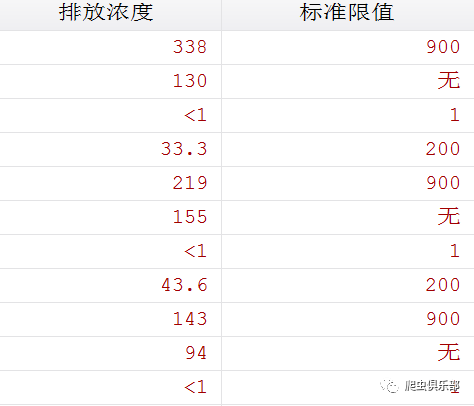
replace 排放浓度=subinstr(排放浓度,"<","",.)
destring 标准限值 排放浓度,replace force // 标准限值中有非数值型数据“无”,加上force选型
第四
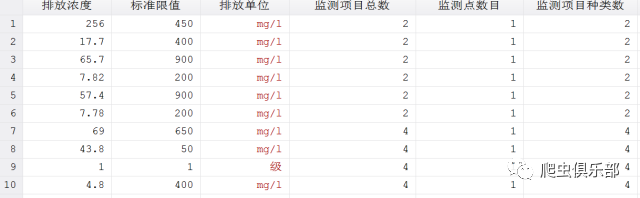
计算每个企业被监测的污染物种类数我们可以通过bysort 企业名称:gen number=_N就可以看到每个企业对应的监测项目种类数,但是有两个复杂的问题是:1.当一个企业对应多个季度时,就把不同的季度当成不同的观测点;2.当一个企业有多个监测点,计算监测项目种类数时需要用每个监测点的监测项目种类数的平均值作为该企业监测项目的的种类数。这要怎么实现呢?
首先,我们要得到每个观测点的监测项目总数和每个观测点的监测点数目。
程序如下:
bysort 企业名称 yq: gen 监测项目总数=_N
bysort 企业名称 yq 监测点名称: gen id=(_n==1)
bysort 企业名称 yq : gen v=sum(id)
bysort 企业名称 yq: egen 监测点数目=max(v)
drop id v
接下来就可以计算每个观测点监测项目的种类数。
gen 监测项目种类数 = 监测项目总数/监测点数目
接着求安全边界sm。(sm=(标准限值-排放浓度)/标准限值)并且排除排放单位不是mg/l的情况。
gen sm = (标准限值-排放浓度)/标准限值 if 排放单位=="mg/l"
第五
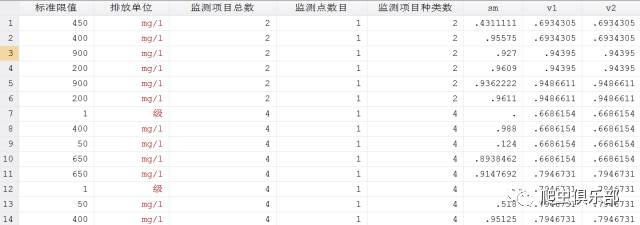
求企业sm的平均值。当然我们想到bysort 企业名称:egen averagesm=mean(sm),但是和上个问题相似:1.同一个企业的监测时间为不同季度时,看做不同的观测点;2.观测点对应多个监测点时,需要取每个监测点sm的平均值的再次平均作为这个观测点sm的平均值。
程序如下:
bysort 企业名称 yq 监测点名称: egen v1= mean(sm)
label var v1 每个监测点的sm平均值
bysort 企业名称 yq: egen v2= mean(v1)
label var v2 每个观测点的sm平均值
这样,我们就一步一步的解决了上述五个问题,得到了最终想要的数据。如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文中给予解答。

接下来
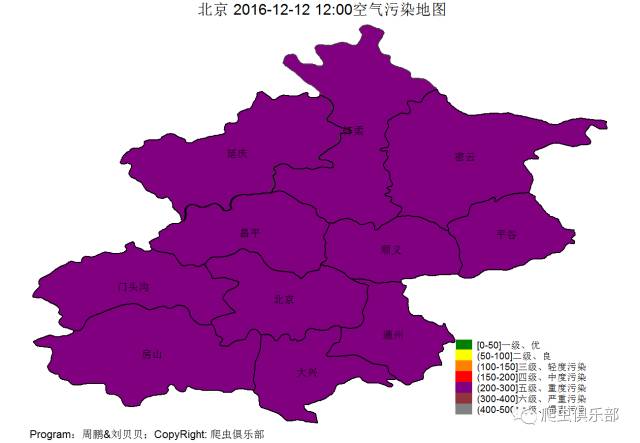
让我们来关心一下空气
总体的空气质量如下图
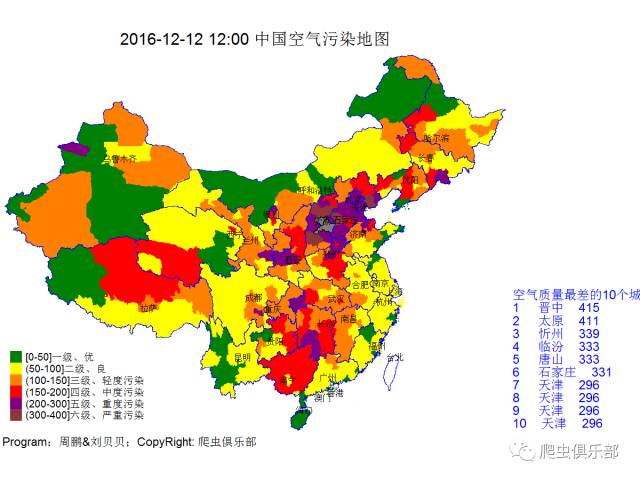
今天点名批评
帝都
以上就是今天给大家分享的内容就是这些了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~,点赞打赏随您心意,么么哒~
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
编辑 by 司海涛

往期推文推荐:
7.爬虫俱乐部周末送大礼——chinagcode提取中文地址经纬度
10.I have a Stata, I have a python
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号