I have a Stata, I have a Python之二——pdf转word
哈喽,诸君安!之前我们曾向大家分享过Stata与Python的交互(I have a Stata, I have a Python),在那篇推文中介绍的方法是在Stata中使用命令python进入到Python环境,可以使用Python的命令。但在Stata中使用命令python需要制作相应的插件,过程比较繁琐,而且Stata只能与Python3.x实现交互,并且在Stata界面中使用python的命令存在明显的弊端,因此我们常常不用这个方法来实现Stata与Python的交互。
此前提到过,Stata中有一个email命令,通过file命令将Python的程序写入一个文件中,再通过dos命令调用,实现Stata与Python的交互。这也可以克服命令python实现交互中的种种弊端。接下来我们通过一个例子来教大家如何实现。目前有个网站,可以把pdf文件转换成word文件,网址为http://www.pdfdo.com/pdf-to-word.aspx,那么我们如何通过程序来操作而不是手工上传呢?


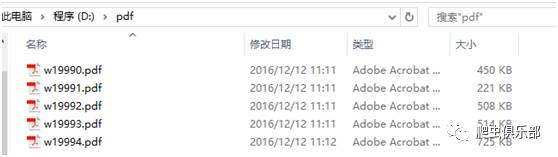
为了演示这一功能,我们首先从NBER上面批量下载一些working paper保存到D盘下面的pdf文件夹内。程序如下:
clear
set more off
forvalues i = 19990/19994 {
copy "http://www.nber.org/papers/w`i'.pdf" "D:/pdf/w`i'.pdf", replace
}
我们首先通过Python来实现把这些文件转换成为word文档。笔者电脑上安装的是Python3.6,如果你用的是Python2.x,部分程序需要做修改。我们需要用到以下几个模块,可以用import导入:
from selenium import webdriver
import time,re,urllib.request,os,random
我们通过打开Google Chrome浏览器,并转到我们用来转换文件格式的网页 http://www.pdfdo.com/pdf-to-word.aspx.
url = "http://www.pdfdo.com/pdf-to-word.aspx"
driver = webdriver.Chrome()
driver.get(url)
接着,我们对pdf文件夹下面的所有文件进行循环,这里需要用到os模块,将所有文件名装入一个列表里面。
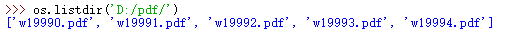
进行循环的命令为:
for filename in os.listdir('D:/pdf/'):
接下来,我们以w19990.pdf为例,展示转换的过程:
我们用GoogleChrome浏览器检查,找到type为“file”的部分,通过name定位,将文件上传到网页上,并休息1~3秒的时间。

driver.find_element_by_name("ctl00$content$FileUpload1").send_keys("D:/pdf/w19990.pdf")
time.sleep(random.randint(1, 3))

然后我们通过name定位到PDF转Word按钮,并点击。网页就会跳转到转码后可下载文件的页面。

driver.find_element_by_name("ctl00$content$cmdSaveAttachment").click()

然后我们获取当前网页的源代码,并通过正则表达式提取并补充完整的下载地址,然后休息3~6秒。

html = driver.page_source
result = re.findall('href="(Download.+?doc)"',html)
download = "http://www.pdfdo.com/" + result[0]
time.sleep(random.randint(3, 6))
此时,download即为下载地址。

我们下载这个链接的文件,并将下载到的文件保存在D盘下的word文件夹中
urllib.request.urlretrieve(download,"D:/word/" + filename + ".doc")
下载完毕后,我们再将上传的文件删除掉,休息5~8秒的时间,再进行下一次操作。删除时,通过xpath定位到删除文件按钮,用程序点击这个按钮,就可以将这个文件删除。

driver.find_element_by_xpath('//*[@id="divFile"]/input').click()
time.sleep(random.randint(5, 8))
将整个程序放入到循环里面,程序如下:
for filename in os.listdir('D:/pdf/'):
driver.find_element_by_name("ctl00$content$FileUpload1").send_keys("D:/pdf/" + filename)
time.sleep(random.randint(1, 3))
driver.find_element_by_name("ctl00$content$cmdSaveAttachment").click()
html = driver.page_source
result = re.findall('href="(Download.+?doc)"',html)
download = "http://www.pdfdo.com/" + result[0]
time.sleep(random.randint(3, 6))
urllib.request.urlretrieve(download,"D:/word/" + filename + ".doc")
driver.find_element_by_xpath('//*[@id="divFile"]/input').click()
time.sleep(random.randint(5, 8))
最后全部文件都转换过之后,我们将浏览器关闭。
driver.quit()
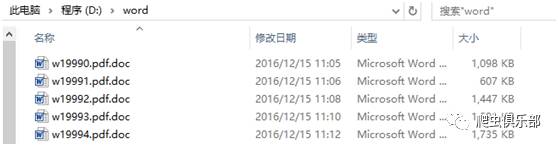
这个时候我们看D盘的word文件夹,文件全部转换成为doc格式并下载了。
以上的过程全部是通过Python实现的,那么怎么样用Stata来做呢?这里就需要用到file命令,将Python的程序写入到一个.py格式的文件中,通过shell调用cmd来运行。用Stata来实现的完整程序如下:
clear
set more off
tempname temp
file open `temp' using "pdftoword.py", write replace
file write `temp' "from selenium import webdriver" _n
file write `temp' "import time,re,urllib.request,os,random" _n
file write `temp' `"url = "http://www.pdfdo.com/pdf-to-word.aspx""' _n
file write `temp' "driver = webdriver.Chrome()" _n
file write `temp' "driver.get(url)" _n
file write `temp' "for filename in os.listdir('D:/pdf/'):" _n
file write `temp' `" driver.find_element_by_name("ctl00\$content\$FileUpload1").send_keys("D:/pdf/" + filename)"' _n
file write `temp' " time.sleep(random.randint(1, 3))" _n
file write `temp' `" driver.find_element_by_name("ctl00\$content\$cmdSaveAttachment").click()"' _n
file write `temp' " html = driver.page_source" _n
file write `temp' `" result = re.findall("""href="(Download.+?doc)""",html)"' _n
file write `temp' `" download = "http://www.pdfdo.com/" + result[0]"' _n
file write `temp' " time.sleep(random.randint(3, 6))" _n
file write `temp' `" urllib.request.urlretrieve(download,"D:/word/" + filename + ".doc")"' _n
file write `temp' `" driver.find_element_by_xpath("""//*[@id="divFile"]/input""").click()"' _n
file write `temp' " time.sleep(random.randint(5, 8))" _n
file write `temp' "driver.quit()"
file close `temp'
! python pdftoword.py
这样,就实现了Stata与Python的交互。当然,前提条件是你的电脑上已经安装了Stata和Python,并且安装了所需要的模块,不然肯定会报错哦。
接下来我们关注一下今天空气质量情况
全国空气质量如下
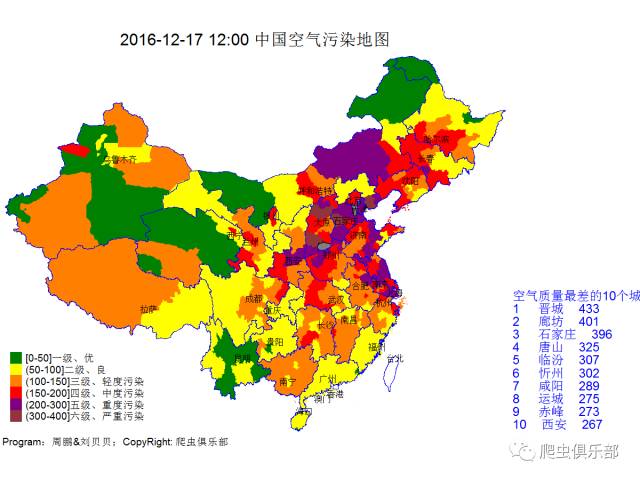
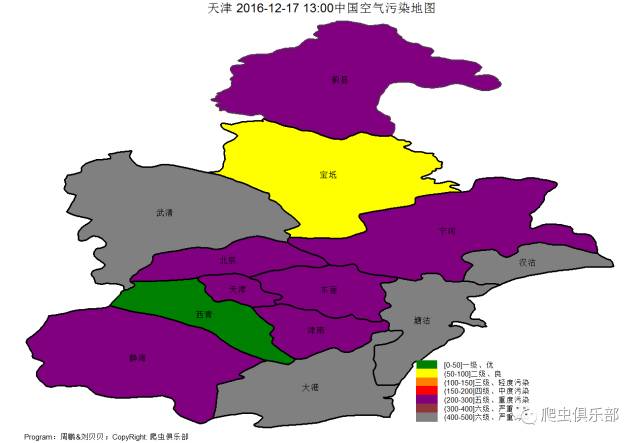
今天
天津的朋友可要注意了
以上就是今天小编与大家分享的全部内容了,如果各位看官喜欢今天分享的内容,不要吝啬你的打赏哦!想了解更多的Stata知识,请继续关注我们的公众号,我们将在后期继续分享更多的干货!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
编辑by张欢

往期推文推荐:
1.火锅和肥羊,啤酒和炸鸡,cnstock和chinafin
5.爬虫俱乐部周末送大礼——chinagcode提取中文地址经纬度
10.I have a Stata, Ihave a python
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号