浅谈正则表达式回溯引用:前后一致匹配
在之前的推文“擂台赛|Stata14 VS Stata13之字符串函数PK”、“字符串函数、正则表达式与变量拆分”中,小编已经给大家分享过Stata13和Stata14中的字符串函数以及它们之间的比较,还有Stata正则表达式中的常用元字符,推文中也给出了相应的例子。今天小编给大家介绍一下正则表达式的回溯引用。
在正则表达式中,往往前后匹配的模式存在一定的关系,比如后面匹配的和前面的部分要求保持一致,这个时候就需要用到回溯引用了。回溯引用的具体定义是指模式的后半部分引用在前半部分中定义的子表达式。为了更好的理解回溯引用的概念,我们通过两个例子来加以说明。
提取vip靓号
现
在假设某公司需要统计vip客户卡号中有多少是靓号。该公司的vip卡号一共有8位数。前三位为字母或数字的任意组合(如:a23、bd6、523)后五
位为连续的数字。如果最后四位为相同的数字,则该vip卡号即为靓号。我们需要从该公司全部vip卡号中把靓号找出来!为了方便大家使用数据,这里手动输
入部分数据:
clear
set more off
input str8 vip_num
ax882163
52632253
as726263
sas12222
ni848888
as672645
sa824165
jh843333
asd19999
das65652
sda56565
89q95555
end
结果如下:
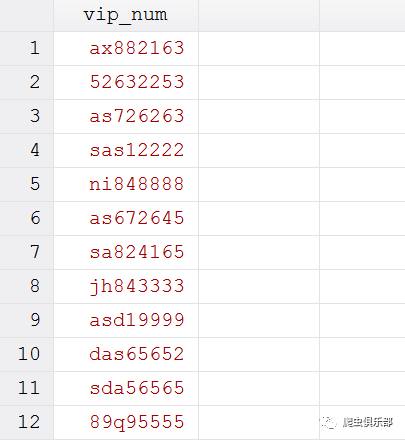
上 边列出了12个vip卡号,其中第4、5、8、9、12行为靓号,当然12个卡号我们通过眼睛搜索就可以查找出来,但是一个公司的vip卡可能成千上万 个,我们不可能一个一个的去查找。我们该怎样的利用stata解决这个问题呢?我们知道靓号与非靓号的差别在于最后四位数字是否一样。而最后四位数字无非 有0000、1111......9999这10种情况,前四位为字母和数字的组合。我们可以构造相应的正则表达式把它们提取出来。
gen nice_num = ustrregexs(0) if ustrregexm(vip_num,"(\w{4})(0{4}|1{4}|2{4}|3{4}|4{4}|5{4}|6{4}|7{4}|8{4}|9{4})")
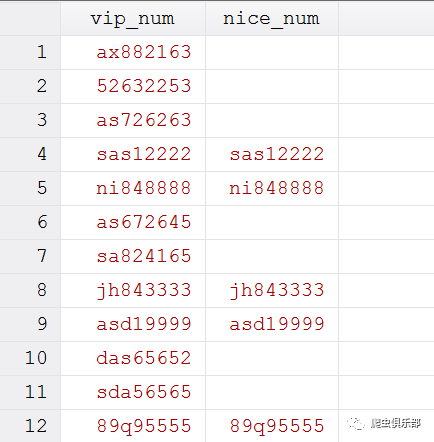
可以看到,我们通过正则表达式把靓号提取了出来。
解释:
(1)\w是一个元字符,这里需要注意的是,\w只能在Stata14中使用,并且只能在ustrregexm、ustrregexs、ustrregexrf、ustrregexra等函数中使用。它表示任何一个字母(大小写均可)、数字、汉字或下划线字符。这里,我们用子表达式(\w{4})匹配4个字母数字字符,即卡号前四位。
(2)子表达式(0{4}|1{4}|2{4}|3{4}|4{4}|5{4}|6{4}|7{4}|8{4}|9{4})表示0000、1111.....9999这10种情况的某一种,即靓号后四位。
这个模式虽然找到了我们想要的东西,但是过于繁琐,我们能不能用更为简洁的正则表达式得出相应结果呢?在这里,我们引入正则表达式回溯引用。
正则表达式如下:
(\w{4})(\d)\2{3}
解释:
该正则表达式中,有两个子表达式:第一个是(\w{4}),第二个是(\d)。
(1)第一个子表达式([\w]{4})仍然是匹配4个字母数字字符,即卡号前四位。
(2)第二个子表达式(\d)表示匹配任意数字字符,在这里对应vip号的第五位。
(3) 这个正则表达式的最后一部分为\2{3}。\2就是一个回溯引用,而它引用的就是前边划分出来的子表达式。\2到底代表着什么?它代表正则表达式中的第2 个子表达式,相应的,\1代表第1个子表达式、\3代表第3个子表达式,以此类推。{3}表示匹配前一个字符(子表达式)的3次重复。
(4)在这里,\2引用的就是该模式的第二个子表达式即(\d),当(\d)匹配到数字1时,\2也匹配到数字1;当(\d)匹配到数字9时,\2也匹配到数字9......\2{3}可以匹配到3个连续的相同数字,且该数字与子表达式(\d)匹配的数字相同。
正则表达式回溯引用:
gen nice_num1 = ustrregexs(0) if ustrregexm(vip_num,"(\w{4})(\d)\2{3}")
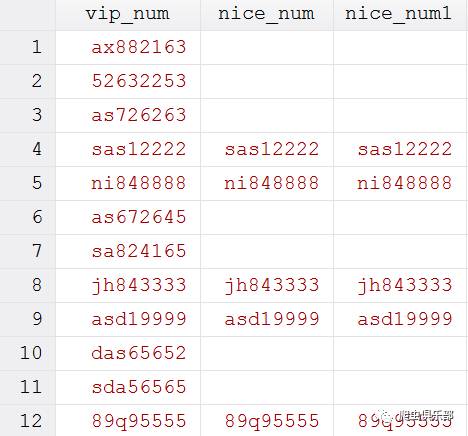
两种模式都能得到我们想要的东西,但是运用正则表达式回溯引用,将使程序变得更为简洁。
查找重复单词
假设你有一段文本,你想把这段文本里所有连续重复出现的单词(打字错误,其中有一个单词输了两遍)找出来。显然,在搜索某个单词的第二次出现时,这个单词必须是已知的。回溯引用允许正则表达式模式引用前面的匹配结果(具体到这个例子,就是前面匹配到的单词)。
数据如下:
clear
set more off
input str25 text
"this is a block of of text"
"seveal words here are are"
"repeated, and and they"
"should not be."
end

可以看到,第1、2、3行中都有重复的单词出现(of、are、and)我们可以通过正则表达式回溯引用找到这些重复的单词。
程序如下:
gen doube = ustrregexs(0) if ustrregexm(text,"\s+(\w+)\s+\1")

这个模式找到了我们想要的东西,但它是如何做到这一点呢?
(1) 首先,元字符\s表示匹配任何一个空白字符,其等价于[\f\n\r\t\v]。(\f表示换页符、\n表示换行符、\r表示回车符、\t表示制表符 (Tab键)、\v表示垂直制表符)但是,在stata中\s表示的就是空格,例如:制表符导入stata中就变为3个连续的空格。所以这里我们用\s+ 匹配一个或多个空格。(这个例子中正则表达式还可以写成[ ]+(\w+)[ ]+\1,[ ]+也可以匹配一个或多个空格。)
(2)子表达式(\w+)匹配一个或多个字母数字字符。这个子表达式把整个模式的一部分单独划分出来以便在后边引用。
(3)这个模式的最后一部分是\1,这是一个回溯引用,而它引用的正是前面划分出来的那个子表达式:当(\w+)匹配到单词of的时候,\1也匹配到单词of,当(\w+)匹配到单词and的时候,\1也匹配到单词and。
回溯引用指的是模式的后半部分引用在前半部分中定义的子表达式。于是,在这个例子中,\s+(\w+)\s+\1将匹配同一个单词的连续两次重复出现,找到我们想要的东西。

今天分享的内容就是这些啦
接下来让我们关注一下空气质量情况
全国空气质量如下
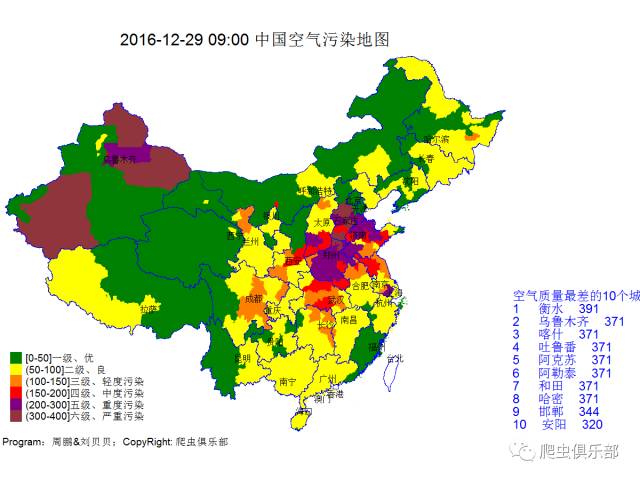
河南的朋友们
出门要戴带口罩哦!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~,点赞打赏随您心意,么么哒~
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
编辑 by 张欢
往期推文推荐:
1.火锅和肥羊,啤酒和炸鸡,cnstock和chinafin
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号