年报,快到碗里来!
穿越高山大海喧哗落寞欢聚和别离
再见已是物是人非
我用尽最后的力量去爱你
为你奉上最后一朵娇艳欲滴
你真的不来看最后一眼?
这积淀的深情一如你的成长积淀
还有那
胖三斤前的萧伯伊安
——萧伯伊安《再见经年·致虫宝宝 十日后我在这等你》
诸君安。预祝新年大吉。爬虫酱要去醉生梦死过春节惹,打烊十天,这是春节前的最后一篇推文啦,大家不要太想念。
最近有朋友询问如何使用Stata下载上市公司的年报。深交所和上交所的网站上都有pdf格式年报。比如我们看到上交所网站上披露的上市公司年报。
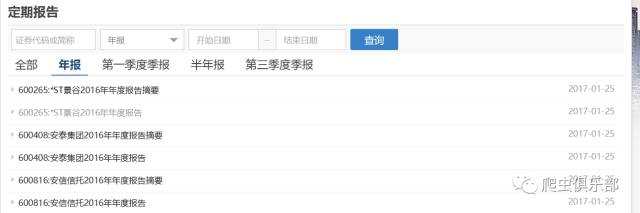
例 如点击*ST景谷2016年年度报告的链接之后,会转到年报的链接http://www.sse.com.cn/disclosure /listedinfo/announcement/c/2017-01-25/600265_2016_n.pdf。我们可以使用Stata的copy 命令来下载这个pdf文件。
copy "http://www.sse.com.cn/disclosure/listedinfo/announcement/c/2017-01-25/600265_2016_n.pdf" 600265_2016.pdf, replace

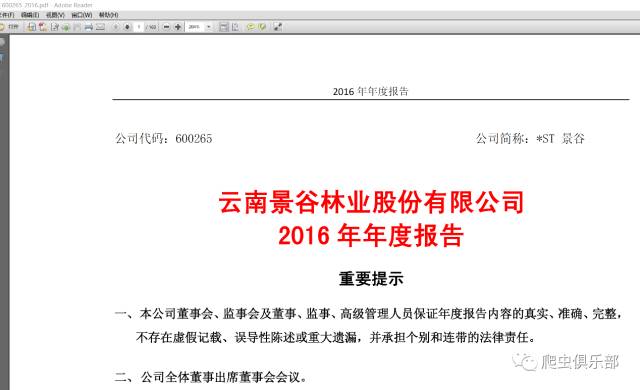
使 用copy命令我们可以很快下载到上市公司的年报,那么现在的问题就是我们如何使用循环下载到多家上市公司多年的年报。我们多点开家上市公司的年报的链接 来寻找链接的规律,可以发现除了股票代码、年份和年报上传到上交所的日期之外,都是一样的。股票代码和年份我们可以使用两层循环来解决,剩下的问题就是如 何获得日期了。使用错误的日期我们将无法下载到年报,例如,我们将上面这个例子中的日期换成2017-01-24,再使用copy命令,就会出现如下的结 果。

这 时就会报错,年报无法下载。显然我们很难搜集到每一家上市公司每一年的年报上传的日期,那么我们怎么办呢?答案就是一个一个试,不过当然不是我们手工去一 个一个试,而是通过程序将这一年的每一天给穷举出来。每年的第一天都是1月1日,我们只需要在这个基础上写一个循环每次加上一天就可以了。使用之前我们公 众号上介绍过的宏扩展函数的方法,可以很容易把日期调整成为CY-N-D的格式,并且放入一个局部宏中。比如我要看2017年1月1日到1月10日这十天 的日期,程序如下:
forvalues date=0/9{
local reptdate: disp %dCY-N-D mdy(1, 1, 2017)+`date'
disp "`reptdate'"
}
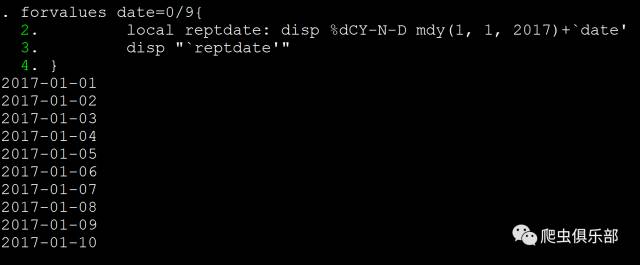
这 样,我们就可以将一年中的每一天穷举出来,看能否下载到年报。但现在还有一个问题,如果我们copy了错误的链接,就会报错终止程序,如何才能在我们尝试 了错误的链接的时候仍然能够使程序继续运行不会报错终止呢?这里就需要用到我们以前介绍过的capture命令。当这个copy命令可以运行时就运行,不 能运行的时候就继续运行后面的程序。可是还有问题,每家上市公司年报上传到上交所的时间都不尽相同,如果我们在已经下载到当年的年报后还继续尝试这一年中 剩下的日期,就会多做许多无用功,浪费时间。如何判断我们是否下载到了这一家上市公司这一年的年报从而跳出循环呢?我们使用capture命令时都会有一 个返回值_rc,例如上一个例子中,我们用错误的链接来copy年报时,_rc是这样的。
capture copy "http://www.sse.com.cn/disclosure/listedinfo/announcement/c/2017-01-24/600265_2016_n.pdf" 600265_2016.pdf, replace
disp _rc

返回值_rc就是当我们不使用capture命令时的报错601。当我们的这个程序可以运行时,返回值_rc就为0。
capture copy "http://www.sse.com.cn/disclosure/listedinfo/announcement/c/2017-01-25/600265_2016_n.pdf" 600265_2016.pdf, replace
disp _rc

因此,我们就可以通过返回值来判断是否要跳出循环。例如我们要下载600900长江电力2015年的年报,程序就可以写成:
forvalues date=0/364{
local reptdate: disp %dCY-N-D mdy(1, 1, 2016)+`date'
disp "`reptdate'"
capture copy "http://www.sse.com.cn/disclosure/listedinfo/announcement/c/`reptdate'/600900_2015_n.pdf" 600900_2015.pdf, replace
if _rc == 0 {
continue, break
}
}
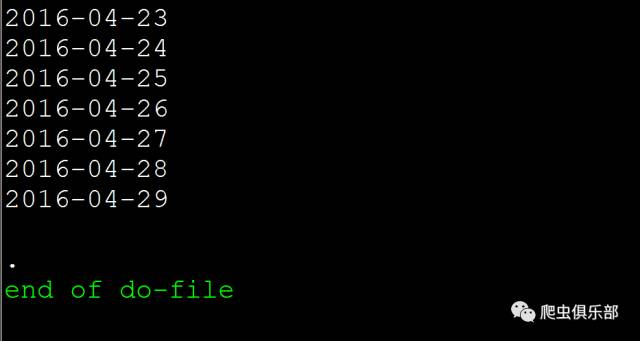
当运行到2016-04-29时程序停止了,说明我们已经下载到了这一年的年报了。如果我们要下载多家上市公司多年的年报,只需要加两层循环就可以了。比如我们要下载600000、600900、601988三家上市公司2013-2015年三年的年报,可以把程序写为:
clear
set more off
cap mkdir "D:\上交所上市公司年报"
cd "D:\上交所上市公司年报"
foreach stkcd in 600000 600900 601988 {
forvalues year = 2013/2015 {
forvalues date=0/364{
local reptdate: disp %dCY-N-D mdy(1, 1, `year' + 1)+`date'
disp "`reptdate'"
capture copy "http://www.sse.com.cn/disclosure/listedinfo/announcement/c/`reptdate'/`stkcd'_`year'_n.pdf" `stkcd'_`year'.pdf, replace
if _rc == 0 {
continue, break
}
}
}
}
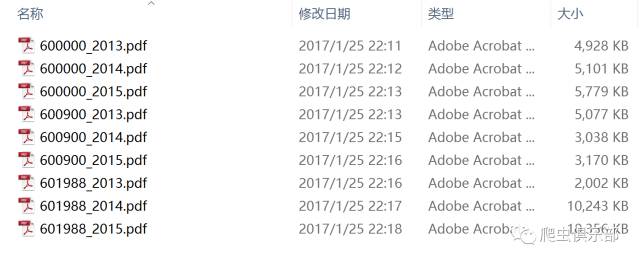
如果下载所有上交所上市公司的年报的话,只需要将所有股票代码放在一个dta文件中用levelsof命令就可以了。大家感兴趣可以尝试。
深交所上市公司的年报在思路上要简单许多,只需要做两次爬虫就可以了。由于深交所的年报链接是没有规律的,因此我们第一次爬虫要先抓取年报的链接。通过解析深交所网页源代码,我们对检索链接进行补充,添加stockCode(证券代码)、noticeType(公告类型)、startTime(起始日期)、endTime(截止日期)以及pageNo(页码)这几部分,例如查看平安银行2010-01-01到2017-01-25所公布过的年报的链接就可以写为http://disclosure.szse.cn/m/search0425.jsp?pageNo=1&stockCode=000001¬iceType=010301&startTime=2010-01-01&endTime=2017-01-25。我们再对抓取到的源代码进行整理,提取年报的链接。
clear
set more off
cap mkdir "D:\深交所上市公司年报"
cd "D:\深交所上市公司年报"
copy "http://disclosure.szse.cn/m/search0425.jsp?pageNo=1&stockCode=000001¬iceType=010301&startTime=2010-01-01&endTime=2017-01-25" temp.txt, replace
unicode encoding set gb18030
unicode translate temp.txt, transutf8
unicode erasebackups, badidea //笔者使用Stata14,对源代码进行转码
infix strL v 1-200000 using temp.txt, clear
keep if index(v, "<a href='") & index(v[_n + 1], "摘要") == 0 //保留年报的链接,不保留年报摘要的链接
replace v = ustrregexs(1) if ustrregexm(v, "<a href='(.+?)'")
replace v = "http://disclosure.szse.cn/" + v
这时,我们就只剩下年报的链接了。
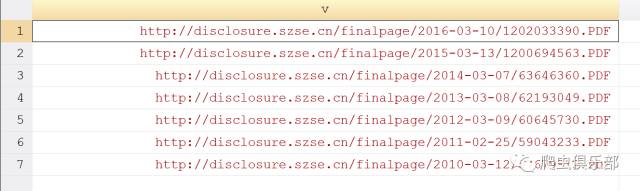
同样是对股票代码进行循环,之后将所有连接合并在一起,再用一次levelsof就可以实现所有深交所上市公司年报的批量下载。
除了上述的方法,我们还可以通过新浪财经网易财经等财经网站下载到上市公司的年报,之前的推文介绍过新浪财经上市公司公告的整理,大家也可以自己尝试一下。

接下来报告空气质量
全国空气质量如下

山西的朋友们请保重
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~,点赞打赏随您心意,么么哒~
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
编辑by梅洁瓷傲
往期推文推荐:
1.合并输出回归结果和其他检验结果——esttab和estadd
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:xueyuan19920310@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号