area & rarea——我填了谁的阴影
在之前的推文中我们多次介绍Stata作图的相关命令,其作图功能的强大与便捷想必大家有目共睹了,今天我们继续分享作图命令area和rarea的用法,它俩都是在图形中填充阴影的命令,仅一字之别,到底有哪些区别与联系呢?
 命令area rarea之初体验
命令area rarea之初体验命令area和rarea都是曲线作图时给图形添加阴影区域的。其中,area所绘图形是指曲线与平行于x 轴的直线所围成的区域为阴影部分,而命令rarea所绘图形是曲线和曲线,曲线和任意直线所围成的区域为阴影部分。关于它们的具体用法,我们help 一下,看看它们的常见选项。
. help twoway area

注:
vertical :是指所做图形是水平方向的,一般Stata的默认值就是vertical;
horizontal:是指图形是垂直方向的即x和y的方向发生变化同时改变相应的图形设置;
cmissing(y|n):是指若变量中有缺失值,加上该选项可以忽略缺失值,使变量为连续的;
base(#):一般默认命令area所绘图形是与x轴即直线y=0所围成的部分为阴影区域,此处的y=0就相当于base(0),当然也可以设置其他的值;
nodropbase:该选项的含义和base(#)是一样的,只不过加上该选项后所绘图形是和y的第一个值与最后一个值的连线围成的部分为阴影区域;
sort: 为了使函数图形有意义,一般将变量x进行排序。
. help twoway rarea

可以看到,命令rarea的语法中显示有两个yvar,说明是需要两个函数围成的区域设置为阴影,这也正是命令rarea比命令area少了选项base(#)和nodropbase的原因。下面通过一个简单的例子进行介绍。我们通过对简单函数y=x^2的作图,介绍命令的选项。具体代码如下:
set scheme s1color
clear
set obs 5000
gen x=uniform()*8
replace x=. if x<1
gen y=x^2
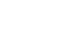
twoway area y x , sort base(10) cmissing(y|n) ///
fcolor(green) lcolor(yellow) title(the graph of x^2) ///
ytitle("the value of x^2") xtitle("") ///
xlabel(0(2)8 5) ylabel(0(20)60 10 27) legend(off) ///
text(27 5 "y=x^2")
可以看到绘制图形如下所示:
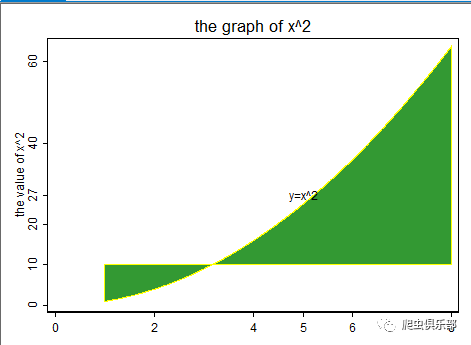
为了学习每一个选项的用法,将绘图命令中的选项稍作修改如下,可以看到图形发生了变化。
twoway area y x , horizontal sort nodropbase cmissing(y|n) ///
fcolor(green) lcolor(yellow) title(the graph of x^2) ///
xtitle("the value of x^2") ytitle("") ///
ylabel(0(2)8) xlabel(0(20)60 28) legend(off) ///
text(6 28 "y=x^2")
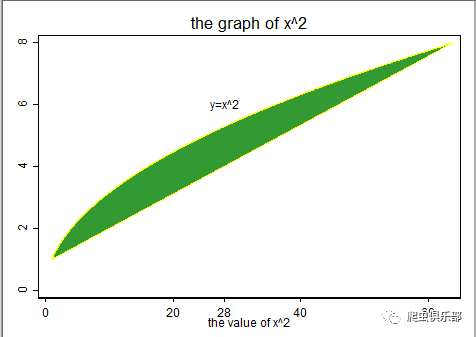
上面这样的图形,乍一眼瞧过去像是两个函数所围成的部分为阴影区域,而选项nodropbase的用途很是局限,当我们碰到要求设置两个函数相交部分为阴影区域恰好可以使用命令rarea很好地解决问题。我们以函数y=x^2与 y=2-x为例说明,具体代码如下:
set scheme s1color
clear
set obs 5000
gen x1=uniform()
gen x2=uniform()*4+1
gen y1 =x1^2
gen y2=2-x1
gen y3=sin(x2)
gen y4=x2^2
twoway rarea y1 y2 x1 ,sort fcolor(green) lcolor(black)|| ///
rarea y3 y4 x2,sort fcolor(blue) lcolor(black) ///
title(the shady graph of y=x^2 and y=2-x) ///
text(-0.5 2 "y=2-x") text(12 3 "y=x^2") ///
xlabel(0(1)5) ylabel(0(5)25 12) legend(off)
命令rarea的其它选项的用法同area,如有需要,请读者自行学习。
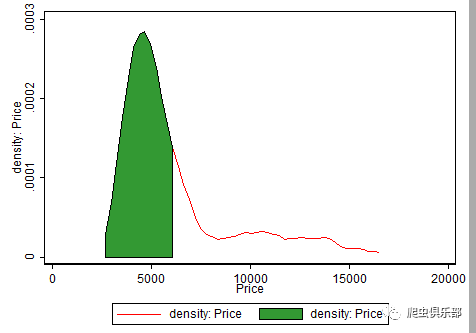
命令area rarea之再应用很多实证研究中,也少不了命令area和rarea的用法。例如我们想看一数据集auto.dta中变量price的大概分布,我们可以绘制该变量的概率密度曲线,为了使得图形更直观,我们可以标记某一部分,这时候就用到命令area,具体代码如下:
sysuse auto, clear
summarize price, mean
local mean = r(mean)
kdensity price, gen(x h) //求解变量price的概率密度函数,并生成估算点x和概率密度值h
line h x,color(red)|| area h x if x< `mean',fcolor(green) lcolor(black)
在时间序列的分析中,为求序列的平稳,差分图的绘制也可用命令area,具体的用法可参考stata自带的例子中对数据集gnp96的研究!
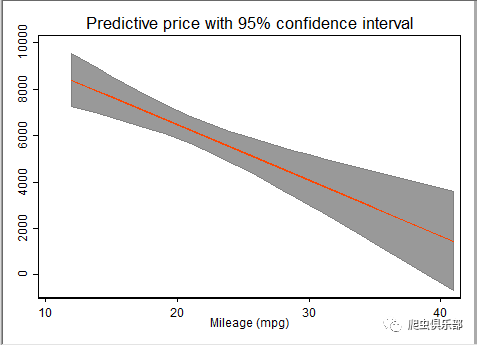
同样以auto数据为例,这是1978年美国汽车销售的数据,汽车的公里耗油量(mpg)如何影响汽车的销售价格price的研究中,我们可以用命令rarea绘制价格price预测值的置信区间,代码如下:
sysuse auto, clear
regress price mpg
predictnl pprice=predict(xb),ci(max95 min95) l(95)
twoway rarea max95 min95 mpg,sort color(gray)||line pprice mpg, ///
title(Predictive price with 95% confidence interval) ///
legend(off)
接下来是空气质量报告
全国空气质量如下

趁着这几天
大家快来养养眼
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~,点赞打赏随您心意,么么哒~
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:张 欢
技术总编:刘贝贝
往期推文推荐:
1.合并输出回归结果和其他检验结果——esttab和estadd
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号