嘿,我才不怕不一样的编码小怪兽!

不知道诸位读者是否和小编一样,在用stata的时候总是遇到因为stata版本不同,文档打开造成乱码的问题。这是因为stata13或更低版本的使用的是ASCII编码,而stata14使用的是UNICODE(统一码、万国码)编码。在我们的之前的朝花夕拾文章《识得庐山真面目—unicode命令》中有过详细介绍。今天,小编就来和大家分享几个好用的小命令,让不同的编码再也不成为你数据整理中的扰人的小怪兽!

首先我们来说一说:
什么是ASCII?
ASCII 是用来表示英文字符的一种编码规范。每个ASCII字符占用1个字节,因此,ASCII编码可以表示的最大字符数是255(00H—FFH)。这对于英文 而言,是没有问题的,一般只什么用到前128个(00H--7FH,最高位为0)。而最高位为1的另128个字符(80H—FFH)被称为“扩展 ASCII”,一般用来存放英文的制表符、部分音标字符等等的一些其它符号。
什么是UNICODE?
Unicode与ASCII一样也是一种字符编码方法,它占用两个字节(0000H—FFFFH),容纳65536个字符,这完全可以容纳全世界所有语言文字的编码。在Unicode里,所有的字符都按一个字符来处理,它们都有一个唯一的Unicode码。

首先需要安装命令unicode2ascii:
ssc install unicode2ascii
我们help一下可以看到以下三个命令:

简单解释一下就是:
whichencoding 检查Stata数据集和文本文件的编码
ascii2unicode 将数据集和文本文件从ASCII转换为Unicode编码
unicode2ascii 将数据集和文本文件从Unicode转换为ASCII编码
whichencoding:
语法:whichencoding filespec [ , detail nodata]
这个命令的用法实在简单,就是whichencoding后面加上文件名就好啦,上例子:
cd "F:\数据示例"
whichencoding *.dta *.do
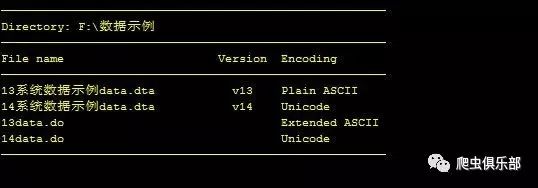
在这里我们就可以看到在两个dta文件和两个do文件中,有一个文件包含纯ASCII编码字符,一个文件包含扩展ASCII编码字符,两个文件包含Unicode编码字符。
具有纯ASCII字符的文件是不需要转换的,但是在我的文件中有一个文件包含扩展ASCII字符,这说明我们可以用stata14打开,但是会出现一些字符无法正确显示的情况,这时候我们就需要运用到ascii2unicode命令将它们转换为Unicode啦。
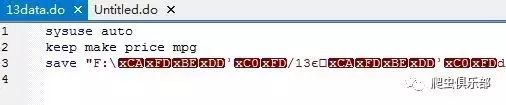
ascii2unicode:
语法:ascii2unicode filespec [ , encoding() suffix() detail nodata replace]
cd "F:\数据示例"
ascii2unicode *.dta *.do , encoding(gb18030)
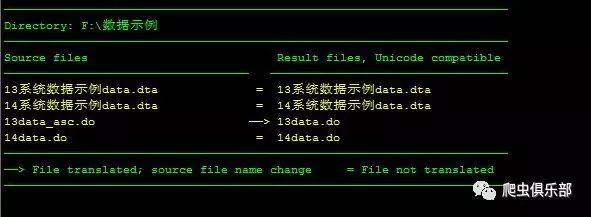
左侧为源文件,右侧为结果文件,比较两列可以发现结果文件与源文件有着相同的名称,其中三个是相同的文件,但是有一个文件从ASCII转换为Unicode码,这一个文件的源文件名称通过包含后缀而改变。对于do-files和其他文本文件,默认后缀为_asc。
我们看到,用14版本的stata打开13版本的do文件也不会有乱码的问题了。
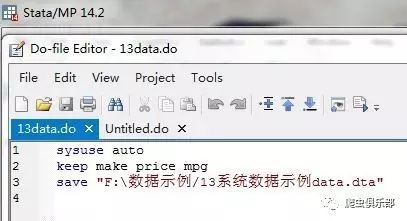
前面的结果中我们可以看到有一个文件包含Unicode编码字符。如果需要,我们可以使用saveascii将文件保存为Stata 11,12或13可以打开的版本,在我们之前的推文《你会用saveascii保存数据吗》中已经介绍过saveascii的用法,但是针对于dta文件,那么我们的do文件应该用什么呢?是时候让unicode2ascii命令闪亮登场了。
unicode2ascii:
语法:unicode2ascii filespec [ , encoding() version() suffix() detail nodata replace]
cd "F:\数据示例"
unicode2ascii *.dta *.do , encoding(gb18030)
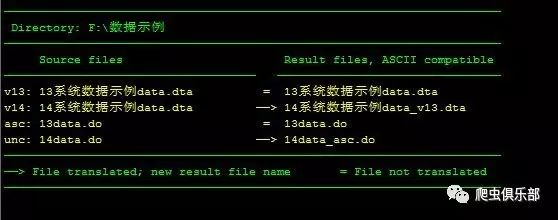
数 据中包含需要用stata13版本打开的一个dta文件和一个do文件,我们可以将它们从Unicode转换为ASCII。从结果中我们可以看到,左侧同 样列出源文件,右侧列出结果文件。源数据集文件名前面是它们的版本,do-file和其他文本文件前面是“unc”或“asc”,以指示它们的编码。如果 指示了转换,就会在结果文件名中添加后缀啦。
同样,我们用13版本的stata打开14版本的do文件也是无压力的。
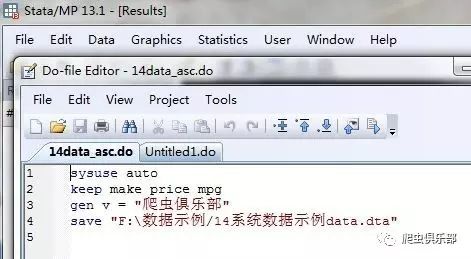
有了这几个小命令,你还怕整理数据的时候ASCII编码&UNICODE编码,高版本&低版本stata傻傻弄不清吗?

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:徐苾雯
技术总编:刘贝贝
往期推文推荐:
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号