正则表达式之拆分姓名

前不久,笔者在抓取数据时遇到这么一个问题:笔 者抓取单个网页所参考的单个网页每个单元格都只有一个英文名,但是放入循环中抓取到所有网页后却发现了有几个英文姓名在同一个单元格内,并且在删除了标签 后英文名之间没有间隔,我们需要把各个英文姓名分隔开。为了大家方便尝试,手动输入数据(篇幅限制,只列出部分数据),程序如下:
clear
set more off
input str50 partners
"Jeb SpencerSteven Hamerslag"
"Adam RothenbergDavid Tisch"
"Erik MittereggerChris Bischoff"
"Jules MaltzSteve Harrick"
"Ron ShahKen Fox"
"Jeff McCarthy"
"Raymond YangDavid LamJason LinKelly Liu"
"Blair MacLaren"
"Fred WilsonBrad Burnham"
"Ben LinAndrew Boszhardt, Jr."
end
运行结果如下:
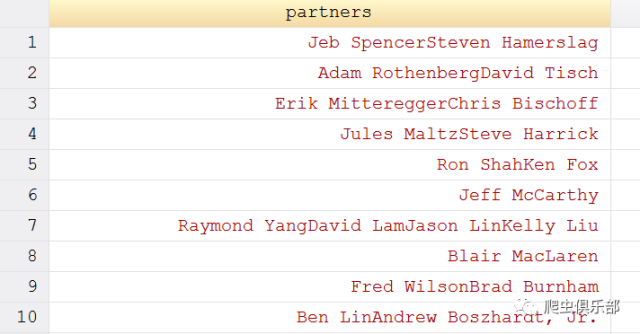
例如数据第一行中,其实是两个姓名:Jeb Spencer和Steven Hamerslag,问题是我们如何将它们分隔开呢?这里需要用到正则表达式回溯引用的替换用法。 在之前的推文浅谈正则表达式回溯引用中,我们已经介绍了回溯引用匹配的用法,即匹配第n个子表达式匹配到的内容。(例如:\1、\2分别表示匹配第1、2 个子表达式匹配到的内容);回溯引用还有另外一个用法就是把文本中的某个字符串替换成第n个子表达式匹配到的内容,其操作符为“$”(例如:$1、$2分 别表示将某个字符串替换成第1、2个子表达式匹配到的内容)下面举一个简单的例子介绍一下它的用法。
例如
. dis ustrregexra("This is is a cat.", "(\b\w+\b )\1", "$1")
This is a cat.
敲黑板:子表达式(\b\w+\b )中,第二个“\b”后边是有一个空格的。
这
个例子在推文浅谈正则表达式回溯引用中已经提及过,即假设有一段文本"This is is a
cat.",你要把这段文本里连续重复出现的单词(打字错误,其中有一个单词输了两遍)找出来,这时候就要用到回溯引用了。子表达式(\b\w+
\b )用来匹配一个单词和其后面的空格,其把整个模式的一部分单独划分出来以便在后边引用,模式的最后一部分是\1则是一个回溯引用,而它引
用的正是前面划分出来的那个子表达式:当(\b\w+\b )匹配到“is ”的时候,\1也匹配到“is ”。
而$1 是替换中的回溯引用,在ustrregexra("This is is a cat.", "(\b\w+\b )\1", "$1")函数中,“$1”中的“1”表示第一个子表达式,即(\b\w+\b )。在这个例子中,"(\b\w+\b )\1"匹配到的是“is is ”,则(\b\w+\b )就表示匹配到了“is ”。那么“$1”在本例子中,就代表把文本"This is is a cat."中的“is is ”替换为“is ”。
接下来继续探讨上述问题,怎么把各个英文姓名分隔开呢?笔者经过观察发现在两个英文姓名之间是有特征的,即小写字母后面跟了一个大写字母,例如“Jeb SpencerSteven Hamerslag”,“Jeb Spencer”和“Steven Hamerslag”分隔点是小写字母“r”和大写字母“S”之间;“Adam RothenbergDavid Tisch”,“Adam Rothenberg”和“David Tisch”分割点是小写字母“g”和大写字母“D”之间。要解决这个问题,笔者的整体思路是先用正则表达式把两个姓名连一块儿的字符串匹配出来(如 SpencerSteven),然后在其中间插入一个分隔符(如Spencer;Steven),再用split函数将其拆分。于是,笔者想到了如下正则 表达式(程序如下):
replace partners = ustrregexra(partners, "( .*?[a-z])([A-Z].*? )", "$1;$2")
这 里用正则表达式“(.*?[a-z])([A-Z].*?)”匹配含有小写字母后跟一个大写字母的字符串以及它们两边的任意字符。后边“$1;$2”就是 替换中的回溯引用,“$1”中的“1”表示第一个子表达式,“2”表示第二个子表达式,“$1;$2”表示在第一和第二个子表达式之间加一个“;”,整个 模式结合ustrregexra函数,就表示把匹配到的两个子表达式替换为“$1;$2”,即在两个子表达式中间加一个“;”。例如“Raymond YangDavid LamJason LinKelly Liu”这一行中有四个名字,用上述正则表达式将首先匹配到(Raymond Yang)(David LamJason LinKelly Liu),然后进行替换,变为“Raymond Yang;David LamJason LinKelly Liu”接着匹配(Raymond Yang;David Lam)(Jason LinKelly Liu),再进行替换变为Raymond Yang;David Lam;Jason LinKelly Liu,最后又匹配到(Raymond Yang;David Lam;Jason Lin)(Kelly Liu),再进行替换变为Raymond Yang;David Lam;Jason Lin;Kelly Liu。我们来看一下运行结果:
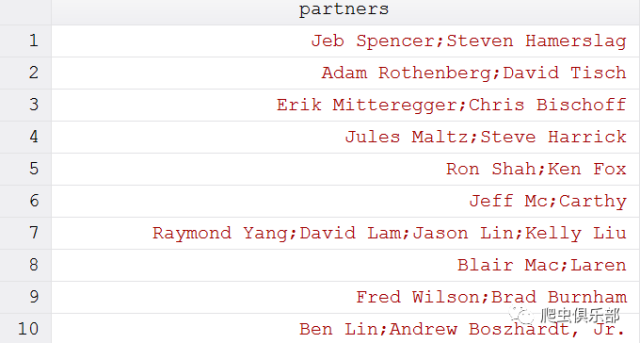
乍 一看,好像把问题解决了呢!但是我们又发现有些英文姓名是这样的“Jeff McCarthy”、“Blair MacLaren”,就是说这些姓名本身就有小写字母后跟一个大写字母的特征,那么上述方法也将把这些姓名拆分掉。(如上图6、8列所示)怎么办呢?观察 “Jeff McCarthy”这些姓名,其中“McCarthy”只有前边有空格,其后是没有空格的;而其他诸如“SpencerSteven”其前后均有空格,那么我们在之前正则表达式的基础上在两端个加一个空格,就排除了拆分像“Jeff McCarthy”这样完整姓名的情况,程序如下:
replace partners = ustrregexra(partners, "( .*?[a-z])([A-Z].*? )", "$1;$2")
我们来看一下结果:
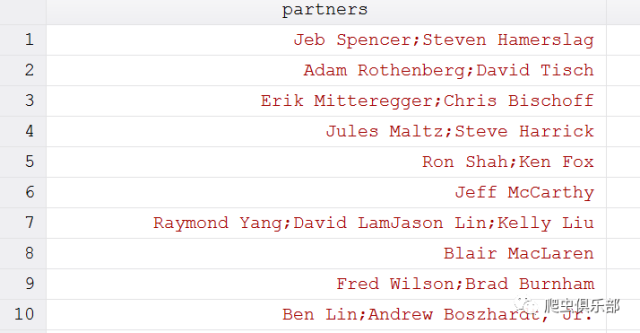
可 以看到,第6和8行的姓名没有被拆分。可是,新的问题又出现了,第7行中,“LamJason”居然没有进行拆分!这是怎么回事儿呢?我们用正则表达式 “( .*?[a-z])([A-Z].*? )”进行匹配的时候,先匹配到 “( Yang)(David )”这里注意其前后均有空格,然后进行替换整个字符串变为“Raymond Yang;David LamJason LinKelly Liu”,接着再进行匹配的时候,就要注意了,以为“LamJason”前的空格已经出现在第一次匹配结果中(即“YangDavid”后的空格),因此 第二次匹配时,“LamJason”前是没有空格的,于是“LamJason”没有被匹配到,相应也没有进行拆分。这又该怎么办呢?关键的问题是怎么让 “LamJason”前的空格参与第二次匹配,在之前的推文我们介绍了正则表达式前后查找具有“只匹配但不消费”的用法。我们可以将上述正则表达式中的空 格换为前后查找空格,每一次只匹配到空格,但不消费它,这样就可以使“LamJason”前的空格参与第二次匹配。程序如下:
replace partners = ustrregexra(partners, "((?<= ).*?[a-z])([A-Z].*?(?= ))", "$1;$2")
运行结果如下:
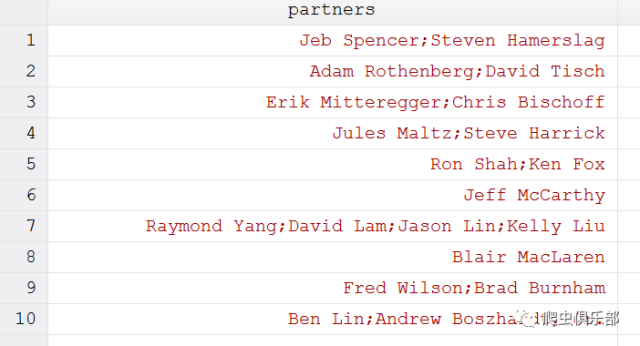
接下来,再用split命令拆分,post命令整理,程序如下:
split partners, p(;)
local num = r(nvars)
cap postclose mypost
postfile mypost str50 partners using D:\stata学习资料\数据\partners.dta, replace
forvalues i = 1/`=_N' {
forvalues j = 1/`num' {
if partners`j'[`i'] == "" {
continue, break
}
post mypost (partners`j'[`i'])
}
}
postclose mypost
use D:\stata学习资料\数据\partners.dta, clear
compress
save D:\stata学习资料\数据\partners.dta, replace
结果如下:
当当当当,跟着小编的指导,我们一步一步就可以用正则表达式将姓名成功拆分。看着整理好的数据,你是不是和小编一样有大大的成就感呢~
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:徐苾雯
技术总编:刘贝贝
往期推文推荐:
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号