朝花夕拾 | 倾向得分匹配(PSM)之一对一精确匹配

在政策评价中,我们常常需要把我们的样本数据分为实验组和对照组,以往的方法是先规定几个标准,比如上司公司样本的几个特征变量,如公司规模,资产负债率等等,然后按照顺序依次配对,这样做会比较麻烦,并且对数据的要求比较高。统计学家Rosenbaum and Rubin在19983提出了“倾向得分”的思想,即某一个体i,在各个匹配变量值都给定的情况下,被选入实验组的概率,而这个概率的计算,我们正好可以使用条件概率模型probit或是logit来实现。具体的分组方法如下,
我们以就业培训项目评估为例,我们的处理变量为个体是否在1974年参加的就业培训,我们选用的控制变量,即我们用来配对的变量为员工的年龄、受教育年份和是否已婚,以及在1974年的工资水平以及是否处于失业状态,我们要评估的结果为1978年工资水平在接受培训和未接受培训的员工之间是否有显著差别。
具体数据如图,
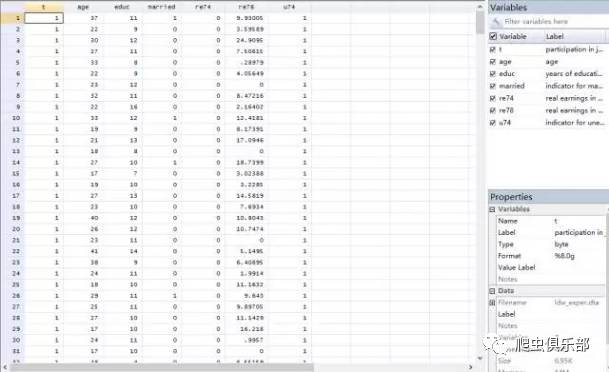
我 们现在为了排除员工自己决定是否参加培训的自我选择问题,我们需要把我们的全部样本分为两组:处理组(接受培训)和对照组(未接受培训),我们这里需要保 证在其他条件不变的情况下,保证两组的员工在年龄、受教育程度、婚姻状况以及在接受培训时的工资水平以就业状况尽可能的保持一致,以检测培训对78年工资水平的影响。
具体的配对命令如下:
首先下载psmatch2命令:findit psmatch2

点击命令包,然后下载安装。
下面我们开始执行一对一匹配,匹配得到的结果中处理组与对照组中样本数量相等,即我们对每一个处理组中的个体都根据得分倾向匹配的原理在未参加培训的样本中找到一个配对个体(在各控制变量数据给定的情况下,配对的两个员工参加培训的可能性最近似。)具体命令如下:
psmatch2 t age educ married re74 u74,outcome(re78) noreplacement
t代表处理变量,这里为员工是否参加过培训,age,educ,married, re74, u74这些为控制变量,即我们设定的作为配对标准的变量,outcome()括号内为我们要对比的结果变量,noreplacement这个option表示不能重复配对,即在对照组中不允许出现重复的个体。
输出结果中,我们需要的结果为这一部分:

黄色数据部分中,作为对比,第一行为未配对数据的结果,第二行为我们需要的处理效应,即配对以后的结果,我们发现,在控制了其他因素的影响以后,接受培训的员工在1978年的工资水平在5%的水平上显著大于为接受培训的员工(即我们需要注意的是第二行中的Difference的显著性),我们得到培训能够增加员工工资水平的结论。
值得注意的是,我们这里为显示出配对的过程,如果我们仅仅需要的是从全部样本中找到处理组和对照组两个组的样本,我们需要进行下面操作:
keep if _weight==1
当_weight为1时,表示的是这个个体参加了配对,为空值时表示该个体未参加配对。所以我们执行这样的操作后,就得到完整的配对结果,如图
tab t
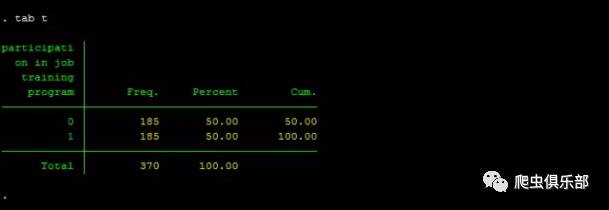
即样本中本来的185个参加培训的个体,并在剩下的260个未参加培训的员工中按照倾向得分匹配的方法找到185个个体作为对照。
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:高娜娜
技术总编:刘贝贝
往期推文推荐:
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号