卤味哪家强?——与STATA全局暂元的一次美丽邂逅
文章来源:香樟经济学术圈公众号
已获得授权
本篇文章原作者为湖南大学经济管理研究中心:梁晓波

今天我们要介绍好多小技巧,请接招。先看引子~
引
子
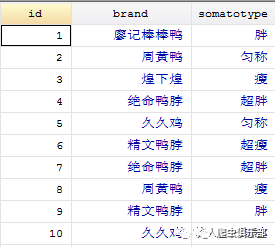
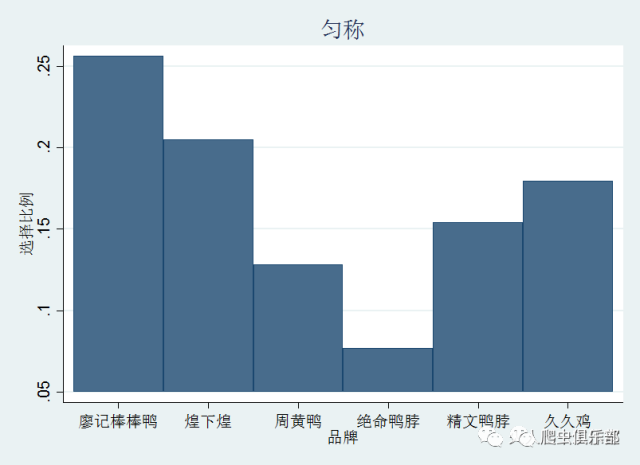
假设我们有这样的一个调查数据,如上图所示,该数据包含3个变量:调查对象(ID),卤味品牌(brand),还有调查对象的体型(somatotype)。现在我们要对这个数据进行处理,找出各个体型的人对卤味品牌的偏好,并用图形描述出来,如下图所示,即是体型匀称的人对个卤味品牌的偏好,他们最爱廖记棒棒鸭,绝命鸭脖的追捧程度最低。
那么,我们应该怎么做呢?也许,你想到以下的程序:
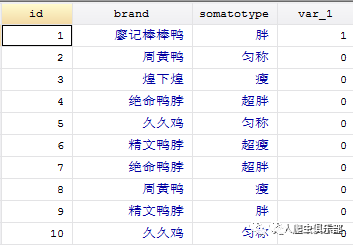
既然是这样,我们开始动手做吧,首先找出偏爱各品牌的人数。第一步,我们先找出喜欢廖记棒棒鸭的人:建立一个变量var_1,当brand=1时,令var_1=1,否则,var_1=0.

运行结果如下:
第二步,按体型求和:bysort somatotype: egen brand_1 = sum(var_1). 下图所示的结果表示超瘦的人中喜欢廖记棒棒鸭的有3个。
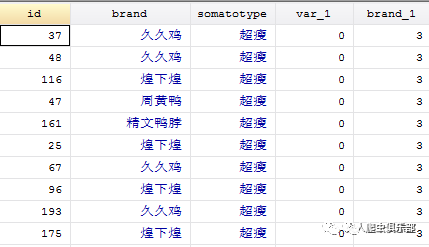
第三步,我们只保留somatotype和brand_1两个变量,删去重复的obs,得到的便是喜欢廖记棒棒鸭的人数。
这时,只要我们重复以上的步骤,就可以得到喜欢各品牌的人数了,品牌数只有6个,所以这一过程还算简单,但是,假若我们有10个,100个,200个,如果重复以上的步骤,貌似相当费时,有没有方法可以使得stata自己运算,不用我们将若干个品牌一个一个地找出来呢?办法肯定有啊,一个forvalues函数就能使得以上自动运行,不过问题就在于,第一步中的条件“if brand == ???”中的品牌代号,能不能用一个变量来表示,我们需要的时候引用这个变量的值就可以了呢?Stata作为一个成熟的软件,当然有这样的功能,接下来,我们的猪脚——“全局暂元”粉墨登场啦~

那全局暂元究竟是个什么东东?敲黑板,重点来了。我就直接告诉你好啦。全局暂元,它就像游走在各个数据文件中的精灵,藏身于STATA内存的最深处,它不受任何一个数据文件的控制,但是,当你打开任何一个文件,一旦你需要它,只要你喊一句“I want you!”,它就会马上现身,任你摆布,而你不需要它的时候,它就挥一挥衣袖,默默离开,除开它的值以外,什么都没有留下。全局暂元,你值得拥有!

好啦,言归正传,我们怎么用这个全局变量?今天的推送,我们就走进全局变量的小小世界。
建立全局变量的语句是global variable = another variable

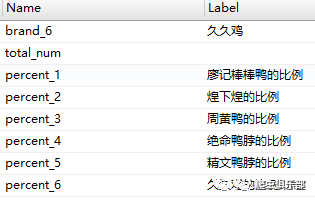
在以上的语句中,我们建立了13个全局暂元:表示数据文件中的obs数量的l,表示品牌代号的brand_id_1,brand_id_2,brand_id_3,brand_id_4,brand_id_5,brand_id_6,分别表示廖记棒棒鸭、煌下煌、周黄鸭、绝命鸭脖、精文鸭脖和久久鸡,还有表示品牌名字brand_name_1,brand_name_2,brand_name_3,brand_name_4,brand_name_5,brand_name_6,分别表示的品牌跟品牌代号一致。由以上可知,全局变量可储存的值的类型既可以是数值型,也可以是字符型。那我能不能直接把包含一系列值的变量直接付给一个全局暂元呢?例如,令global brand_id = brand. 这样貌似行不通,这种情况下我们只把brand的第一个值,亦即111,赋给了brand_id,换句话说,brand_id只储存了一个值,111。全局暂元只能储存单值!

类似地,我们建立可以利用体型数据文件建立体型全局暂元。

用macro list可以查看我们建立的所有全局暂元。

这时,我们就可以用forvalues来实现引子中的三个步骤了。

在这段代码中,有三个值得注意的的地方:
以上的代码展示了全局暂元的两种引用方法:forvalues函数内的引用和函数外的引用。先说函数外的引用方法:在变量名前添加美元符号“$”,如上面的“$l”,如果该全局暂元储存的值是字符型,还需要添加双引号“”””,如“”$l””。至于函数内的引用方法:先用大括号“{}”把变量名包住,再在前面添加美元符号“$”,如上面的${brand_id_`i'},当i=3时,引用的是brand_id_3的值——333,语句gen var_`i' = 1 if brand == ${brand_id_`i'}实际执行的是gen var_3 = 1 if brand == 33,即建立变量var_3,并且品牌为周黄鸭时,令var_3的值为1.如果引用的全局暂元储存的值是字符型,也是添加双引号“”””即可,如上面给变量添加标签时的引用"${brand_name_`i'}"。
分类求和时,我们用到的是egen brand_`i' = sum(var_`i'),而不是gen brand_`i' = sum(var_`i')。使用gen时,sum( )是一个逐步求和函数,不是全部加总,我们可以实际运行结果来区别egen和gen的不同功能。以下两图,上图用的是egen,下图用的是gen。
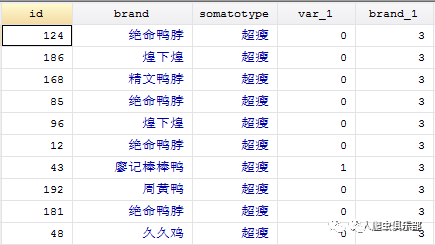
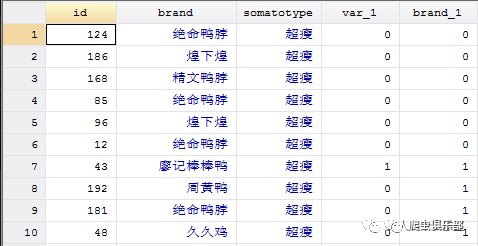
在第二个图中,brand_1[1] = var[1],brand_1[2] = var[2] + brand_1[1],brand_1[3] = var[3] + brand_1[2],以此类推。鉴于var[1]到var[6]都是0,var[7]是1,直到第7个obs时brand_1的值才是1,而var[8]到var[10]又全是0,brand_1[8]到brand_1[10]的值全是1.而在第一个图中,brand_1直接给出一个总数。显然,只用egen才达到我们的全部加总的目的。
在以上的forvalues函数,我们对每一个品牌生成一个独立的数据文件(“save brand_`i'.dta, replace”),现在,我们合并这些数据文件,加总求和。

按体型求和是怎样做到的呢?我们可以先观察数据结构。

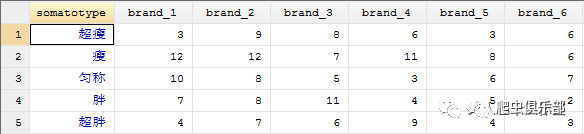
显然,每一行对应的是某一体型下选择各个品牌的人数,我们只需要横向加总求和,直接加。在这里,我们也可以查看total_num的描述性统计,以检验我们的做法对不对。
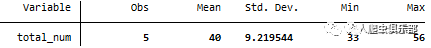
Obs为5,mean为40,总数为5*40=200,而survey文件中的obs有200个,两个数字一致,也就是说每一个obs已经算到里面了,我们的步骤应该是正确的。
这也简单。用各品牌的人数除以总人数就可以了。

不过,我们在这里用到了全局暂元的更高级的引用方法:与其他文字混搭。建立标签时,我们在品牌名字后面添加了“的比例”3个大字,显示出这是一个比例,不是频数。
终于来到最后一步——作图了。但是,我们可以直接作图吗?我们这次需要做的是柱形图,使用的基本语句是“twoway bar yvar xvar”,换句话说,我们要用到两个变量,一个表示品牌的名称,一个表示某一体型偏好各品牌的比例,然而,我们并没有表示品牌的变量。嗷,又出现了问题。那怎么办呢?

不怕,我们把表格转置过来就OK。

Xpose是STATA自带的转置函数,详情请输入help xpose. 转置以前,我们先删掉一些无关变量, somatotype,total_num,brand_1到brand_6。使用以上语句转置后,原来的5行变成5个变量,表示各体型偏好各品牌的比例的,v1-v5,以及一个新变量_varname,_varname描述了各行对应的转置前的变量名。

以下两个图中,上图是转置前的数据,下图是转置后的数据。
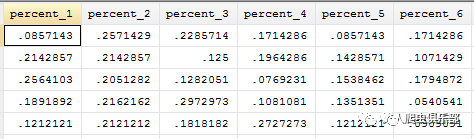
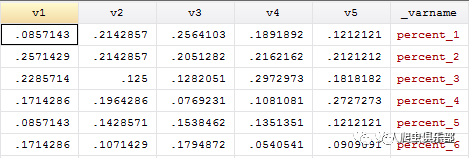
为了使变量名更加直观些,我们对变量重命名,添加标签。

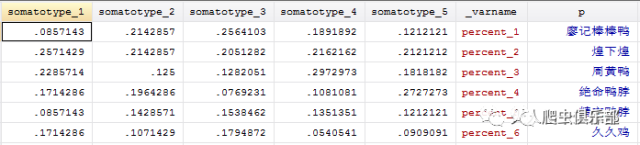
我们添加一个变量p,表示品牌,并对p的各个变量添加标签。

P的值的标签来自brand数据文件。在这里我们用brand_name的值添加到p的值的标签里的。这样的好处是不用一个一个地添加。这种方法包括两步:先encode要作为标签的变量,然后给目标变量添加标签(labmask).这又是一个重要技巧~

现在,我们得到形如如下的数据了,可以画图了。
接下来当然是画图,保存啦。
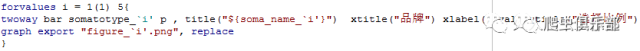
Twoway bar其实有很多巧妙的小方法让你的图形变得好看起来,或者减轻你的工作负担。比方说,上面在xlabel选项里加入一个val子选项,x轴上显示的是p的各个值的标签,而不是各个值。更多请输入help twoway bar挖掘!

至此,我们画图的目的已经完成。不过,一切都还没有结束。在最后,还抛砖引玉——简单介绍mata. Mata是STATA 13新加入的一个函数集(大概是这样的吧!),可将文字段、表格、图片插入到word文档里,甚至,还可以将图片插入到表格的某一个单元格里,功能十分强大。在这里,我们仅仅介绍将图片插入到一个新的word文档里。请看示例code:
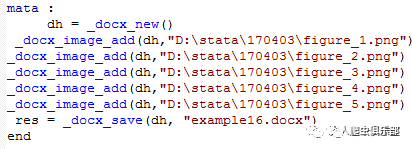
使用mata时,先要告诉STATA接下来要执行mata函数集咯。
然后,新建一个docx文件。Dh是一个值,在后面的语句中,如果有引用到dh,运行该语句后,屏幕会显示dh值,如果返回的dh值是个负值,则说明该语句没有成功运行。如下图所示,目标code成功运行。

新建文档后,接下来就是添加图片,使用_docx_image_add( , )函数,括号内,逗号前是返回dh值,逗号后是图片的路径与文件名。也许你会问,我有很多图片要添加的时候,能不能用forvalues一次性解决啊?很遗憾,没有~不过,只要你想办法,就不用一行一行地输入了。虽然STATA帮不了你,但是你还有excel啊啊啊啊。

好了,本次推送的最后一个干货来了:你把第一行复制到excel的某一个单元格,然后下拉填充,别说这次的5个语句,就算是上万句,都能瞬间给你完成啊啊啊啊啊!
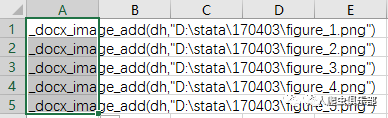
自动生成的语句,照样复制粘贴会do文件,这也不需要多久啊啊啊啊!
图片添加完毕,保存文件~提醒一下,如果文件夹中已有同名的文件,傻逼_docx_save( , )函数并不会帮你把旧文件覆盖掉~所以,每次运行之前,记得修改文件名!
最后,别忘了添上end命令,否则STATA还沉浸在mata的世界里无法自拔。

好了,剩下的就交给你们了!


以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:司海涛
技术总编:刘贝贝
往期推文推荐:
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部

微信扫一扫
关注该公众号