【有问必答】这个命令我曾见过的——债项评级数据处理
诸君安
又是有问必答时间
今天教大家一些数据清理的方法
都是爬虫君介绍过的命令
但有不一样的精彩呢
1
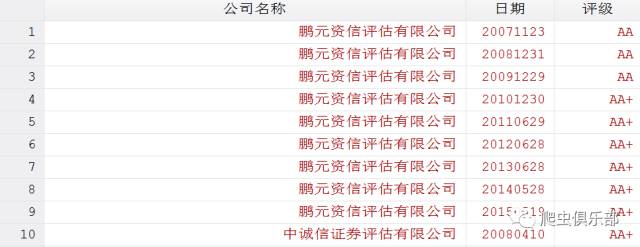
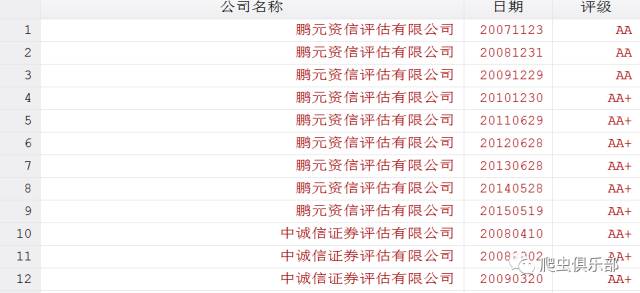
有如下一个数据:

可以看到,每一条观测值都包含有同一个公司不同日期的评级,我们需要把变量“历史债项评级”拆分为公司名称、日期以及对应的评级。如下图所示:
首先,我们想到通过split命令对其进行拆分,程序如下:
split 历史债项评级 ,p("(" ")""-")
我们通过“(”、“)”、“-”对变量进行拆分,结果如下:
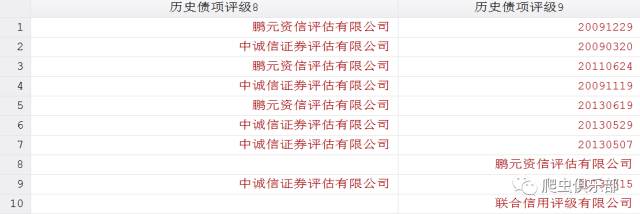
可以看到,拆分后数据发生了错位,这是因为除了公司和日期之间含有“-”,部分评级中也包含有“-”。(如第10行中第三个评级AA-)所以拆分后就发生了错位。这里我们需要对变量进行两次拆分,首先用“(”和“)”进行拆分,然后再用“-”进行对变量拆分,程序如下:
split 历史债项评级 ,p("(" ")")
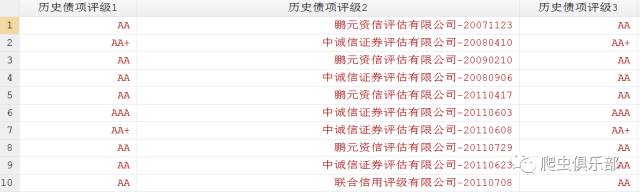
这样,就把评级与公司名称和日期拆分开来,接着在用split对公司名称和日期进行拆分,程序如下:
forvalue i = 2(2)20{
split 历史债项评级`i' ,p("-")
drop 历史债项评级`i'
}
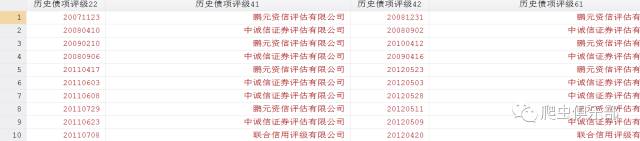
好了,这里我们就把变量“历史债项评级”拆分完毕。
数据拆分完毕,但是怎么把拆分后的数据整理成我们想要的格式呢?由于每个观测值公司评级的数量不相同,再加上两次拆分使得变量顺序非常乱,这里我们可以用数据整理的法宝post整理数据。程序如下:
cap postclose mypost
postfile mypost str100 公司名称 str20 日期 str10 评级 using d:/历史债项评级.dta,replace
forvalue i = 1(1)`=_N'{
post mypost (历史债项评级21[`i']) (历史债项评级22[`i']) (历史债项评级1[`i'])
post mypost (历史债项评级41[`i']) (历史债项评级42[`i']) (历史债项评级3[`i'])
post mypost (历史债项评级61[`i']) (历史债项评级62[`i']) (历史债项评级5[`i'])
post mypost (历史债项评级81[`i']) (历史债项评级82[`i']) (历史债项评级7[`i'])
post mypost (历史债项评级101[`i']) (历史债项评级102[`i']) (历史债项评级9[`i'])
post mypost (历史债项评级121[`i']) (历史债项评级122[`i']) (历史债项评级11[`i'])
post mypost (历史债项评级141[`i']) (历史债项评级142[`i']) (历史债项评级13[`i'])
post mypost (历史债项评级161[`i']) (历史债项评级162[`i']) (历史债项评级15[`i'])
post mypost (历史债项评级181[`i']) (历史债项评级182[`i']) (历史债项评级17[`i'])
post mypost (历史债项评级201[`i']) (历史债项评级202[`i']) (历史债项评级19[`i'])
}
postclose mypost
use d:/历史债项评级.dta,clear
drop if 公司名称 == ""
compress
save d:/历史债项评级.dta,replace
结果如下:
2
第二个问题,数据如下所示:
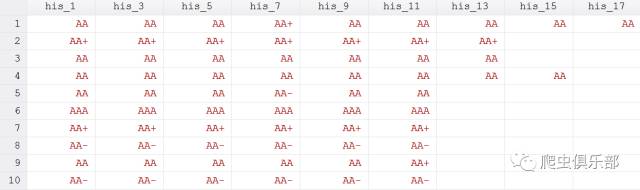
我们需要生成一个变量v,如果his_1-his_17除了缺失值都相同,取值为1,否则为0。这个问题如果从his_1-his_17都相同的,取1的角度,是非常麻烦的。因为要在变量不为缺失值的情况下同时满足his_1 = his_3 & his_1 = his_5 & his_1 = his_7 ......反过来,his_3-his_17当中只要有一个与his_1不相同,v即取0。程序如下:
gen v = 1
forvalues i = 1/`=_N' {
foreach v of varlist his_3 - his_17{
if `v'[`i'] != "" {
if his_1[`i'] != `v'[`i'] {
replace v = 0 in `i'
}
}
}
}
运行结果如下:

这里,我们首先生成变量v,取值全部为1。然后对所有观测值和变量进行循环,对于每一条观测值,在保证变量不为缺失值的情况下,如果his_3-his_17有一个与his_1不相同,v取值就变为0。
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:梅洁瓷傲
技术总编:刘贝贝
往期推文推荐:
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部

微信扫一扫
关注该公众号