如何快速得出变量包含的数字个数




“
上课:起立!
老……师……好!
童鞋们好!
请坐下!
今天我们这节课讲得是一题多解
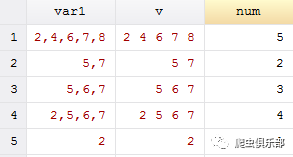
先来看下面图1
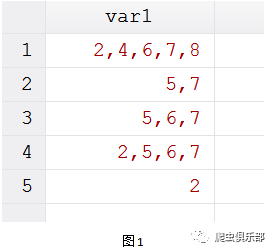
根据图1可以看到,变量var1对应的列中,第1行包含有5个数字,第2行含有2个数字,第3行有3个数字……如此等等。
问题
如果变量var1对应的列有很多行,如何得出每行包含的数字个数分别是多少呢?

方法一
每一行都数一下,记录一下,就可以了。
解析
方 法一的最大优点就是:简单直接,如果只有5行的话,该方法就是最好最快的办法,but,如果有5000行,你还这么干的话,我也不拦着你,反正我不会这么 干,我懒,懒人总得想个懒办法:什么懒办法呢,肯定不能让人来一行行数,而是让计算机去数,解放人类!它会比人更快更准更放心!
方法二
moss命令,让计算机快速得出每行包含的数字个数,结果见下面图2
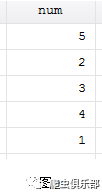
解析
1.引理:moss命令(我们之前有推文介绍:参见moss命令、正则表达式与简单的文本分析)
moss var1,match(",")
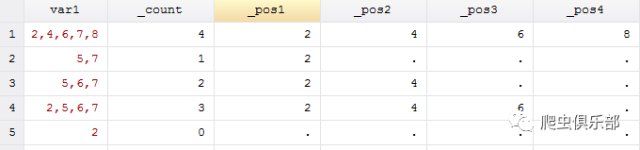
note:_count:逗号","的个数,_post1-4:分别是每个逗号","所在的位置
2.证明:
∵数字都是用逗号隔开的
∴数字个数即为逗号个数+1
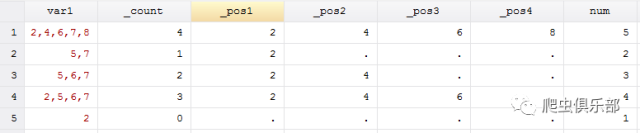
即:gen num = _count+1
num即为所求,证毕。
见下图:
另辟蹊径
另外除了用moss命令得到“,”的个数,来进一步统计出数字的个数,我们还可以利用moss命令,结合正则表达式直接得到数字的个数,程序如下:
moss v ,match("(\d+)") regex unicode

变量_count即为变量v中数字的个数。
方法三
wordcount(s)命令可直接数出在s中包含的词的个数。
解:
gen v = ustrregexra(var1,","," ") (1)
gen num= wordcount(v) (2)
解之,得:num即为所求。
解析
(留为作业,各位童鞋下去归纳总结)
提示:
式(1)用正则表达式,将原题中var1中的逗号全替换成空格
式(2)则是直接用wordcount()函数数出数字个数(每个数字看做一个词,被空格分开)
具体见下图:
红星照我去奋斗
根据今天上课的内容,大家拿到一道题,首先要先分析,对于今天上课讲的题呢,大家下去重新练习一下,每种解题方法之前,写一个分析过程,要善于思考、分析以及归纳总结,多练多积累,以培养思维分析和解题能力,方法多种,殊途同归,只有熟练掌握灵活运用,才能找到既快又简单的方法。
咳…咳…咳,五一快到了,回家的童鞋举手,好,出去玩的童鞋举手,好,不回家也不出去玩的童鞋举手,好,布置一下五一假期作业(教室一片骚乱),静一下,听好了,五一假期作业是:
回家的,回来给我带特产
出去旅游的,回来给我带特产
不回家也不出去旅游的,那就留下来请我吃饭,我也不回家了
所有童鞋表忘记复习爬虫俱乐部推文(开学回来检查)
所有童鞋欢迎给爬虫俱乐部打赏
祝大家五一快乐,出行安全!
今天的课就上到这里,下课!

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:司海涛
技术总编:刘贝贝
往期推文推荐:
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号