双重差分模型的平行趋势假定如何检验? ——coefplot命令来告诉你(一)

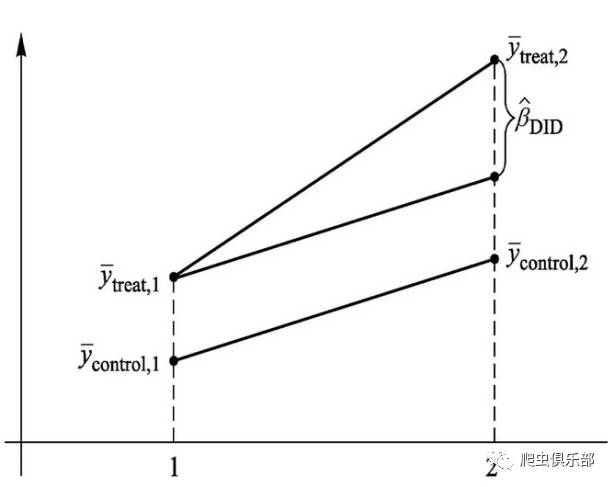
双重差分模型(difference-in-differences)主 要被用于社会学中的政策效果评估。其原理是基于一个反事实的框架来评估政策发生和不发生这两种情况下被观测因素y的变化。如果一个外生的政策冲击将样本分 为两组—受政策干预的Treat组和未受政策干预的Control组,且在政策冲击前,Treat组和Control组的y没有显著差异,那么我们就可以 将Control组在政策发生前后y的变化看作Treat组未受政策冲击时的状况(反事实的结果)。通过比较Treat组y的变化(D1)以及 Control组y的变化(D2),我们就可以得到政策冲击的实际效果(DD=D1-D2)。
具体地,单一冲击时点的双重差分的模型如下:
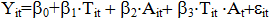
其中,Ti为政策虚拟变量;Ai为时间虚拟变量; Ti ×At为两者的交互项;b3即为我们需要的双重差分估计量。
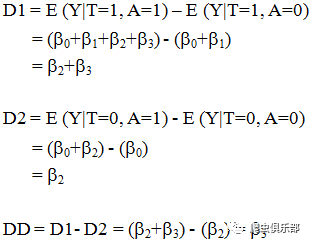
需要特别指出的是,只有在满足”政策冲击前Treat组和Control组的y没有显著差异”(即平行性假定)的条件下,得到的双重差分估计量才是无偏的。

下面我们就通过模拟数据来进一步介绍双重差分估计和平行性假定的检验:

一、构造数据

1.首先我们构造观测值并生成随机数种子
clear
set more off
set obs 1000
set seed 123456789
2.构造面板数据,将1000个样本,分为两组:实验组(Treat==1),对照组(Treat==0)
gen Treat=(uniform()<=0.6)
3.根据随机数构造公司-年度数据
bysort Treat: gen int group=uniform()*90+Treat*90+1
bysort group: gen year=2016-_n+1
4.假定2012年,实验组(Treat==1)公司受到一个外生政策冲击
gen Post=(year>=2012)
5.模拟被解释变量y,控制变量x1,x2
gen y=ln(1+uniform()*100)
replace y=y + ln(uniform()*10+rnormal()*3) if Treat==1 & Post==1
gen x1=rnormal()*3
gen x2=rnormal()+uniform()
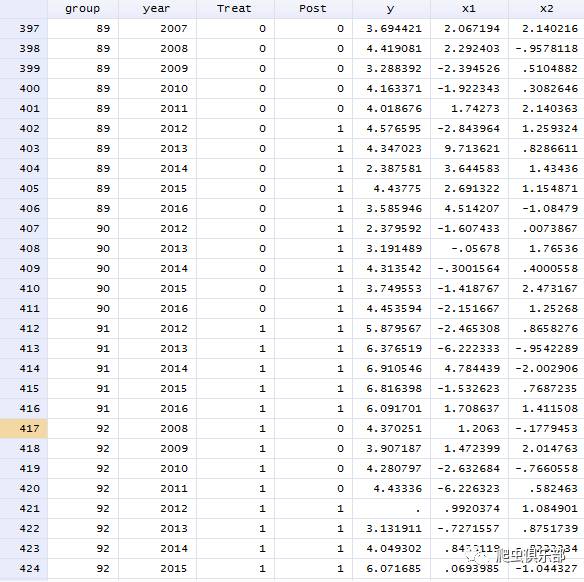
我们可以看到,公司id(group)、年份(year)、分组标识(Treat)、冲击发生标识(Post)、被解释变量(y)以及控制变量(x1, x2)已经生成。
二、双重差分模型估计
gen Treat_Post=Treat*Post
xi: regress y Treat Post Treat*Post x1 x2 i.year, vce(robust)
est store OLS_DID
xtset group year
xi: xtreg y Post Treat*Post x1 x2 i.year,fe vce(robust)
est store FE_DID
esttab OLS_DID FE_DID, ar2(%9.3f) b(%9.3f) t(%9.3f) nogap compress ///
indicate("Year=_Iyear*") star(* 0.1 ** 0.05 *** 0.01)
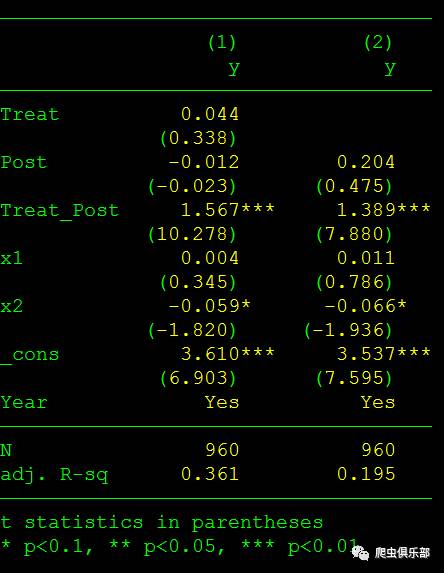
结果显示交互项(Treat*Post)的系数显著为正,表明政策实施导致了y显著增加。然而,此时我们还不能确切的说,这一政策效果的评估是准确的,因为只有在对照组和实验组满足平行性假定的时候,Treat和post的交互项才是处理效应。因此平行趋势假定的重要性不言而喻。平行性假定的检验可以通过回归分析或者绘图的方式进行。
三、平行性假定和
动态效果分析
gen Dyear=year-2012
gen Before2=(Dyear==-2 & Treat==1)
lab var Before2 "2 Year Prior"
gen Before1=(Dyear==-1 & Treat==1)
lab var Before1 "1 Year Prior"
gen Current=(Dyear==0 & Treat==1)
lab var Current "Year of Adoption"
gen After1=(Dyear==1 & Treat==1)
lab var After1 "1 Year After"
gen After2=(Dyear==2 & Treat==1)
lab var After2 "2 Year After"
gen After3_=(Dyear>=3 & Treat==1)
lab var After3_ "3 or More Year After"
xtset group year
xi:xtreg y Treat Post Before2 Before1 Current After1 ///
After2 After3_ x1 x2 i.year,fe vce(robust)
est store Dynamic
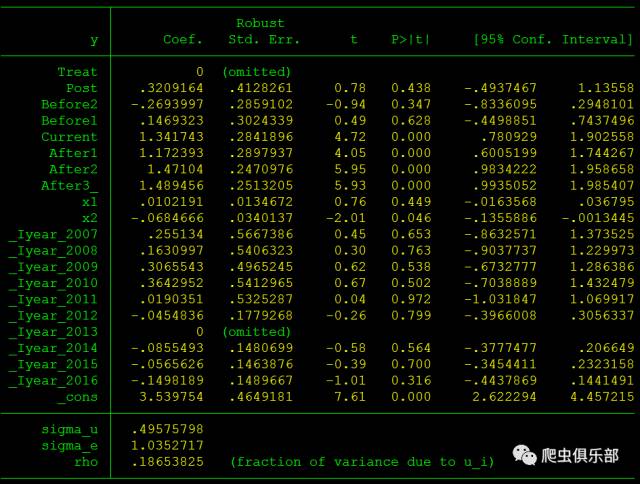
Before2,Before1 均为虚拟变量,如果观测值是受到政策冲击前的第2年和第1年的数据,则该指标分别取1,否则取0;如果观测值是受到政策冲击当年的数据,则Current 取值为1,否则取0;当观测值是受到政策冲击后的第1年、第2年、第3年的数据时,After1、After2、After3分别取1,否则取0。
我们看到Before2,Before1的系数均不显著,而Current、After1、After2、After3的系数均正向显著,说明双重差分模型满足平行趋势假定。
在下一期推文中我们将介绍关键部分,即如何使用coefplot命令输出图形,用图形来反映平行趋势假定。预知后事如何,请继续关注我们的公众号哟~祝大家周末愉快!

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:徐苾雯
技术总编:刘贝贝
往期推文推荐:
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号