元字符“.”真的能够匹配任意单个字符吗?
我们知道“.”是正则表达式的一个基本元字符,有很多书籍中都称其匹配任意单个字符,其实不然,元字符“.”匹配的应当是除了回车符(\r)和换行符(\n)之外的任意字符,下面笔者以一个例子来说明这一点。
笔者在抓取新浪上市公司公告内容时,用copy命令将源代码保存在temp.txt文档中,然后通过fileread函数将源代码读入stata,程序如下:
clear
set more off
cd d:/
copy "http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletinDetail.php?stockid=300225&id=1792687" temp.txt,replace
unicode encoding set gb18030
unicode translate temp.txt,transutf8
unicode erasebackups,badidea
set obs 1
gen v = fileread("temp.txt")
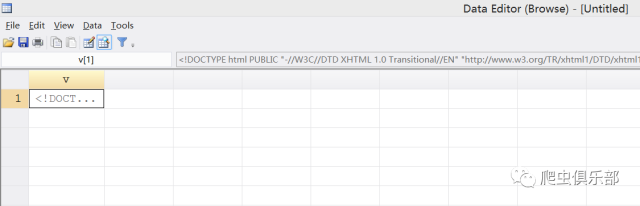
并且通过分析网页源代码可知,在公告内容起始位置有一个唯一的字符“<pre>”,末尾位置有字符“<br>”,虽然它不是唯一的,但是我们只需要从这个字符开始到文档末尾的所有内容删除即可,如下图所示:

接着,我们通过正则表达式叫公告内容前后多余的字符串删掉,程序如下:
replace v = ustrregexra(v,".+?<pre>","")
replace v = ustrregexra(v,"<br>.+","")
运行结果如下图所示:
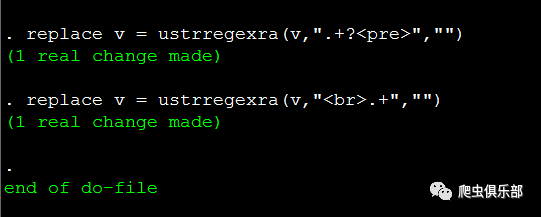
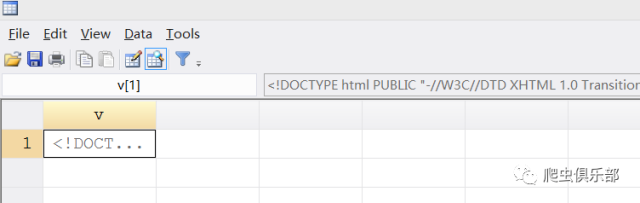
奇怪的是,程序运行结果显示观测值确实发生了变化,但是我们看到Stata内存中的数据,开头部分的字符串仍然没有删除掉,这是为什么呢?在推文“用正则表达式揭开回车键的面纱” 中,我们讲到在windows操作系统中是把\r\n用作文本行的结束标签,而元字符“.”可以匹配除了回车符(\r)和换行符(\n)之外的任意字符, 所以由于这里存在着换行符(\n)和回车符(\r),而元字符“.”不能匹配到它们,因此匹配结果仅仅是位于字符串“<pre>”的所在行以 及字符串“<br>”的所在行。要解决这个问题,有两种思路:
1、删除掉换行符和回车符,再用“.”进行匹配,程序如下:
replace v = ustrregexra(v,"\r\n","")
replace v = ustrregexra(v,".+?<pre>","")
replace v = ustrregexra(v,"<br>.+","")
运行结果如下所示:
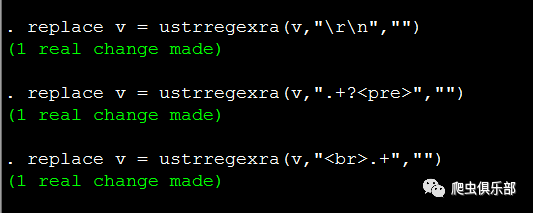

这样,我们就把公告内容前后多余的字符串删除掉了。
2、通过含义相反的一组元字符来匹配任意字符
我们知道,元字符\d匹配数字,而\D匹配非数字字符,因此我们可以利用这一组合来匹配任意字符:
程序如下:
replace v = ustrregexra(v,"[\d\D]+?<pre>","")
replace v = ustrregexra(v,"<br>[\d\D]+","")
运行结果如下:

可以看到,我们通过[\d\D]可以匹配到任意单个字符。类似于这样的组合还有很多,例如:\w匹配任一字母、数字、下划线,在unicode编码中也可 匹配汉字等,\W则为\w的反义;\s表示空白字符,\S为\s的反义,即非空白字符等,这些具有相反含义的元字符的组合([\s\S]、[\w\W]) 都可以用来匹配任意单个字符。

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:高娜娜
技术总编:刘贝贝
往期推文推荐:
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号