天作之合——reclink

诸君安!上联:红花理应绿叶配;下联:英雄自当美女陪。横批:天作之合。小编这就给你们带来本期的匹配神器——reclink
一、reclink介绍
reclink 是一种模糊匹配方法,可以提高匹配的效率。当用于匹配的变量在两份数据中的记录不完全一样时,reclink就派上大用场了。reclink命令会在两份 数据匹配的过程中生成匹配得分(matching scores),也就是两个观测值的相似度,匹配得分的值介于0和1之间,如果匹配得分等于1,则说明两个观测值是完全一样的。
二、reclink语法
reclink varlist using filename , idmaster(varname) idusing(varname) gen(newvarname) [wmatch(match weight list) wnomatch(non-match weight list) orblock(varlist) required(varlist) exactstr(varlist) exclude(filename) _merge(newvarname) uvarlist(varlist) uprefix(text) minscore(#) minbigram(#)]
从reclink的语法上看,其逗号之前的部分和merge的用法类似,都是依据某些变量将using data匹配到master data中,但reclink有很多选项,这也使得reclink命令比merge更灵活、更强大。
三、reclink使用
idmaster(varname)、 idusing(varname)、gen(newvarname)是reclink的必要部分。gen(newvarname)用来记录匹配得分。 idmaster(varname)和idusing(varname)分别是master data和using data中可以唯一识别每一条观测值的变量,在模糊匹配后,可以根据idmaster(varname)和idusing(varname)查看 master data和using data中的谁和谁匹配到一起了。
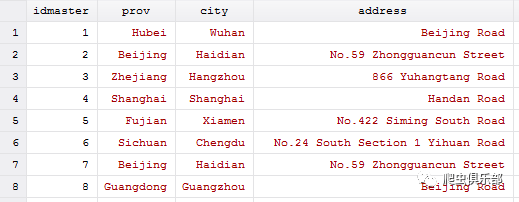
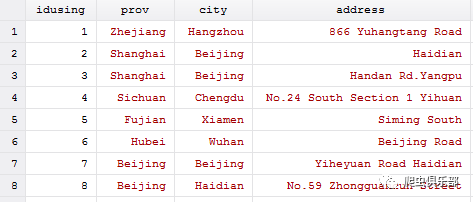
例 如:我们现在有两份数据(如下图),master data中可以唯一识别每一条观测值的变量是idmaster,using data中可以唯一识别每一条观测值的变量是idusing,可以看到的是,虽然在master data中第2个和第7个观测值的内容是一样的,但他们的idmaster是不一样的。
现在,我们想依据“prov+city+address”的准则将两份数据匹配在一起,使用命令
reclink prov city address using using.dta,idmaster(idmaster) idusing(idusing) gen(matchscore)

我们可以从结果看到以下几点:
1、根据idmaster变量和idusing变量可以看出,master data的第1个观测值和using data的第6个观测值匹配在一起了。
2、新生成的变量matchscore的值介于0和1之间,代表着每条观测值的匹配得分,其值越大,说明相似度越高,如果两条观测值完全相同,则匹配得分值等于1。
3、 using data中的第8个观测值既和master data中的第2个观测值相似又和master data中的第7个观测值相似,那么using data中的第8个观测值分别和master data中的第2个观测值和第7个观测值匹配了。这是因为reclink使用的是记录连接方法(RL),即在using data中找能和master data中的数据相匹配的数据,是单向的。
4、using data中的第2个观测值没有匹配进来,这是因为依据我们设定的“prov+city+address”准 则,“Shanghai+Beijing+Haidian”这条观测值和master data的所有观测值都不相似。这也是reclink和merge命令的主要区别之一,对于无法和master data匹配的观测值,不进入最后结果。
5、 _merge表示匹配的结果,_merge==3表示匹配成功,_merge==1表示master data中的观测值在using data中没有找到能够匹配的。如,master data中的第8个观测值在using data中没有找到能够匹配的观测值,其_merge==1。
在 上述例子中计算匹配得分的时候,我们并没有指定prov、city和address的权重,如果没有指定,则默认prov、city和address的权 重都为1,也就是prov、city和address在匹配中的重要性一样。而reclink的wmatch(match weight list)和wnomatch(non-match weight list)选项还可以分别给prov、city和address匹配成功和匹配不成功的指定权重,来区分不同的变量在匹配中的重要性,从而依据指定的权重 来计算匹配得分。权重是一个介于[1,20]之间的整数。
假如我们认为city和address变量的信息很重要,prov的信息不那么重要,我们可以分别给prov、city和address指定权重5、10、15,使用如下命令:
reclink prov city address using using.dta,idmaster(idmaster) idusing(idusing) gen(matchscore) wmatch(5 10 15)

假如我们认为prov和address变量的信息很重要,city的信息不那么重要,我们可以分别给prov、city和address指定权重15、5、10,使用如下命令:
reclink prov city address using using.dta,idmaster(idmaster) idusing(idusing) gen(matchscore) wmatch(15 5 10)

从 上述两种情况可以看出,指定的权重不同,匹配的结果也不同,在第二种情况下,我们弱化了city所能提供的信息,因此master data的第4个观测值和using data中的第3个观测值匹配在一起了,尽管他们的city是不同的。而在第一种情况下,这两条观测值并没有匹配成功。
上述是使用wmatch(match weight list)选项为匹配成功指定权重,还可以使用wnomatch(non-match weight list)为匹配不成功指定权重。
reclink prov city address using using.dta,idmaster(idmaster)idusing(idusing) gen(matchscore) wmatch(15 5 10) wnomatch(2 3 4)

在为匹配不成功指定权重,匹配得分的值也不一样了。
reclink 是一种模糊匹配方法,因此有些原本不属于同一个观测值的,也被匹配到一起了,如上述master data的第4条和using data的第3条的city明显不是同一个,但也匹配在一起了。如果我们想指定一个或多个变量必须完全匹配才算匹配成功的话,可以使用 required(varlist)选项。现在我们指定prov和city必须完全匹配才算匹配成功,使用如下命令:
reclink prov city address using using.dta,idmaster(idmaster)idusing(idusing) gen(matchscore) required(prov city)

我们看到,master data的第4条观测值并没找到可以匹配的观测值。
除
此之外,还可以使用_merge(varname)选项来指定匹配结果变量,默认情况下是_merge;使用uprefix(string)选项指定匹配
到master data中的using
data中变量名的前缀,默认的前缀为U,例如,当匹配的变量名为prov、city和address时,则结果数据中会显示Uprov、Ucity和
Uaddress;还用minscore(#)选项来指定最小总体匹配度,默认值是0.6,当匹配得分小于指定的得分时,则认为未匹配成
功,_merge==1;使用uvarlist(varlist)选项来指定using data中和master
data中变量名不同的匹配变量。例如,master data中的匹配变量是prov、city和address,而using
data中的匹配变量是prov、city和add,那么,可以使用uvarlist(prov city add)来指定,而不用再using
data中修改变量名;等等。
reclink命令非常灵活,但是,需要注意的是,这种模糊匹配是不完美的,在匹配后需要再check一下。尤其是对于那些匹配得分低的。
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:王明
技术总编:刘贝贝
往期推文推荐:
7.一言不合就用stata写邮件(Outlook/Foxmail)
9.I have a Stata, I have a python
10.I have a Stata, I have a Python之二——pdf转word
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部

微信扫一扫
关注该公众号