爬虫“黑科技”:一网打尽AER





笔者从小的时候就有一个黑客梦,就像美国科幻电影里,一个一个代码跳跃于指间,完成了一个又一个不可能的奇迹,决胜于千里之外,是不是很酷! 笔者以为这是一个永远不可能的梦,当我进入爬虫俱乐部,看见师兄用编好的程序实现电影里的画面,小星星都冒出来了!想不想学习这种狂拽炫酷吊炸天的技能, 快和笔者走进爬虫世界。
世 界上公认的经济学No.1期刊无疑是American Economic Review。如果我在上面发篇文章,那岂不是迎娶白富美,出任CEO,走上人生巅峰,想想是不是有点小激动呢!好了不做白日梦了。但是我们可以参考 American Economic Review上的文章,然后发一个比较好的文章,那也是极好的。这时候要有个American Economic Review所有的期刊目录,那该有多好,所以今天笔者给大家带来的是爬取American Economic Review上的所有文章目录。
一
网页分析
知己知彼才能百战百胜,首先我们分析下American Economic Review的网页https://www.aeaweb.org/journals/aer/issues
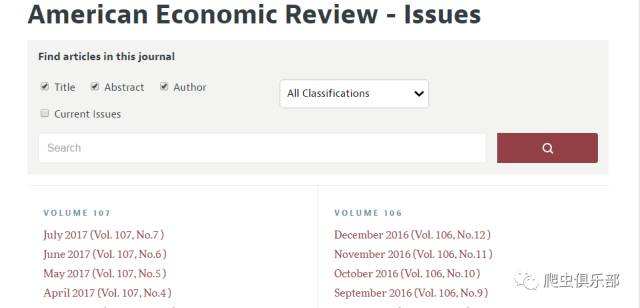
发现网页上有期刊号和时间,点开期刊号和时间的链接July 2017 (Vol. 107, No.7 ),结果如下: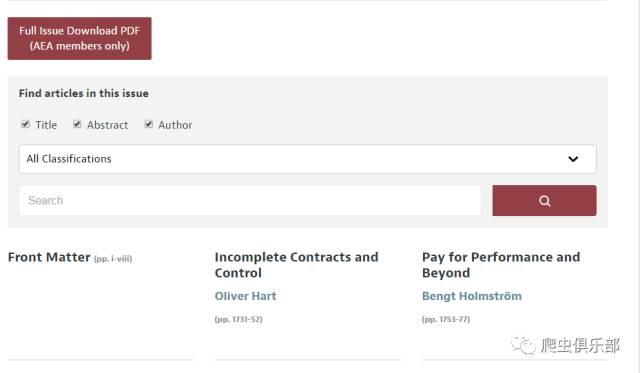
发现这个网页上有我们想要的,就是没有期刊和时间,我们继续点击Incomplete Contracts and Control 链接,结果如下:

发现这个网页上有文章标题,作者,期刊号,时间,我们想要的都有,太酷了!那接下来就开始我们的爬虫黑科技吧。
二
爬虫思路
首先我们的思路是先爬每个期刊号和时间的链接,然后通过每个期刊号和时间的链接,加入循环,爬取每篇文章的链接,最后通过每篇文章的链接,加入循环,爬取我们所需要的每篇文章的题目,作者,期刊号,时间,最后绘成最终目录。

三
爬虫流程
1、爬取期刊号和时间的链接
在爬虫里面最重要的是什么,没错,就是源代码。首先开启我们神奇的第一步,我们进入https://www.aeaweb.org/journals/aer/issues网页,查看每个期刊号和时间的源代码:

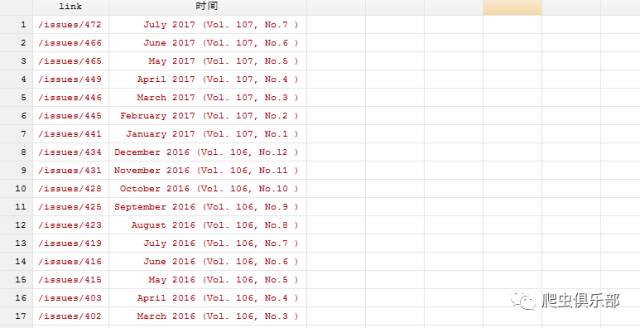
发现我们所要的行都有字符串“<a href='/issues/”。我们可以使用往期推文里“删繁就简三秋叶,subinfile似剪刀”中的subinfile命令,把字符串“<a href='”和“</a>”都删了,再用split命令按照字符串“'>”把数据分为“link”和“时间”两个部分。操作如下:
clear
cap mkdir d:/美国经济评论
cd d:/美国经济评论
copy "https://www.aeaweb.org/journals/aer/issues" d:/美国经济评论/temp.txt
subinfile temp.txt, index("<a href='/issues/")///
from("(<a href=')|(</a>)") fromregex dropempty replace
infix strL v 1-20000 using temp.txt, clear
split v,parse('>)
rename (v1 v2) (link 时间)
drop v

2、爬取每篇文章的链接
接 着我们开始奇幻的第二步,我们以https://www.aeaweb.org/issues/472为例,先爬取一个期刊号和时间对应的每篇文章链接, 然后加上循环获取所有期刊号和时间所对应的文章链接。我们看下https://www.aeaweb.org/issues/472的源代码:
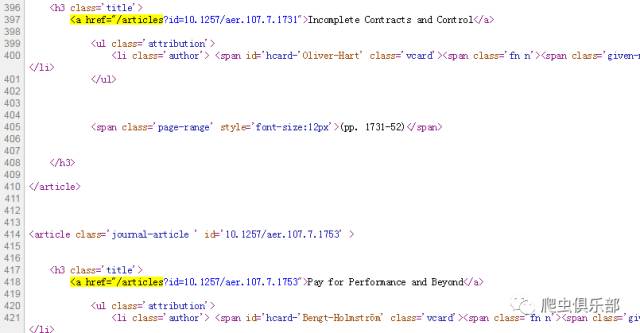
发现我们所要的行都有字符串“<a href="/articles”。我们可以使用往期推文里“删繁就简三秋叶,subinfile似剪刀”中的subinfile命令,把字符串“<a href='”和“</a>”都删了,再用split命令按照字符串“">”把数据分为v1和v2两个部分,保留每篇文章的链接sublink。操作如下:
copy "https://www.aeaweb.org/issues/472" d:/美国经济评论/sublink.txt,replace
subinfile sublink.txt, index(`"<a href="/articles"')///
from(`"(<a href=")|(</a>)"') fromregex dropempty replace
infix strL v 1-20000 using sublink.txt, clear
split v,parse(`"">"')
drop v v2
rename v1 sublink
3、爬取我们需要的信息
最重要的一步来了,我们根据每篇文章的链接抓取我们需要的期刊号,时间,作者,文章标题。
笔 者以https://www.aeaweb.org/articles?id=10.1257/aer.20121437上一篇文章为例,抓取这些这篇文 章的所有信息,然后放入循环,抓取所有文章的信息。我们先分析https://www.aeaweb.org/articles?id=10.1257 /aer.20121437的源代码。

我们发现有多个作者,于是我们想法是匹配到字符串“<div style='margin-top:25px;'>”开始,往上一行加,并删除这一行,直到不匹配到字符串`“<ul class="attribution">”' 为止,这样我们就把所有的作者放到一行里了,然后我们写入循环,接着我们用正则表达式以字符串“<h1>”,“<div style='margin-top:25px;'>”,“<li>vol”分别抓取题目,作者,期刊号和时间。我们可以使用往期推文 里的“数据的转置—xpose&sxpose”中的sxpose对字符串进行装置,并用正则表达式分别提取期刊号和年月,重新命名一下,得到我们所需要的数据。
copy "https://www.aeaweb.org/articles?id=10.1257/aer.20121437" d:/美国经济评论/paper.txt,replace
infix strL v 1-200000 using paper.txt, clear
forvalues i =`=_N' (-1) 1{
if index(v[`i'],"<div style='margin-top:25px;'>") & !index(v[`i'],`"<ul class="attribution">"') {
replace v = v+ v[`i'] in `=`i'-1'
drop in `i'
}
}
keep if ustrregexm(v,`"(<h1 class="title">)|(<div style='margin-top:25px;'>)|(<li class='journal'>vol)"')
replace v = ustrregexra(v, "<.*?>" , "")
replace v = ustrregexra(v, "\s{2,}" , ";")
replace v = ustrregexra(v, ";$", "")
sxpose ,clear
gen ym = ustrregexs(0) if ustrregexm(_var3, "[A-Z].*")
gen journal_number = ustrregexra(_var3,", [A-Z].*","")
drop _var3
rename (_var1 _var2 ) (title author)
drop if author == ""

然后我们进行循环,可以得到所有的题目,作者,期刊号和时间。我们可以用往期的推文“送你一只粘合剂——用openall命令合并数据”中的命令openall把每篇文章的题目,作者,期刊号和时间合并起来,得到AER的终极目录。
四
完整程序
clear
set more off
cap mkdir d:/美国经济评论
cd d:/美国经济评论
copy "https://www.aeaweb.org/journals/aer/issues" d:/美国经济评论/temp.txt,replace
subinfile temp.txt, index("<a href='/issues/") from("(<a href=')|(</a>)") fromregex dropempty replace
infix strL v 1-20000 using temp.txt, clear
split v,parse('>)
rename (v1 v2) (link 时间)
drop v
levelsof link, local(level)
local i = 1
foreach a of local level {
copy "https://www.aeaweb.org`a'" d:/美国经济评论/sublink.txt,replace
subinfile sublink.txt, index(`"<a href="/articles"') from(`"(<a href=")|(</a>)"') fromregex dropempty replace
infix strL v 1-20000 using sublink.txt, clear
split v,parse(`"">"')
drop v v2
rename v1 sublink
levelsof sublink, local(levels)
local j = 1
foreach c of local levels {
copy "https://www.aeaweb.org`c'" d:/美国经济评论/paper.txt,replace
infix strL v 1-200000 using paper.txt, clear
forvalues i =`=_N' (-1) 1{
if index(v[`i'],"<div style='margin-top:25px;'>") & !index(v[`i'],`"<ul class="attribution">"') {
replace v = v+ v[`i'] in `=`i'-1'
drop in `i'
}
}
keep if ustrregexm(v,`"(<h1 class="title">)|(<div style='margin-top:25px;'>)|(<li class='journal'>vol)"')
replace v = ustrregexra(v, "<.*?>" , "")
replace v = ustrregexra(v, "\s{2,}" , ";")
replace v = ustrregexra(v, ";$", "")
sxpose ,clear
gen ym = ustrregexs(0) if ustrregexm(_var3, "[A-Z].*")
gen journal_number = ustrregexra(_var3,", [A-Z].*","")
drop _var3
rename (_var1 _var2 ) (title author)
drop if author == ""
save "`i'_`j'.dta",replace
local j =`j'+1
}
local i=`i'+1
}
openall
save AER.dta

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑: 王明
技术总编:刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
7.Stata 15之Markdown——没有做不到,只有想不到!
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号