试试用file read读入外部数据!

大大大大大新闻————爬虫俱乐部新推出了视频讲解环节。小编突然浮现出一个画面——看着视频嗑着瓜子学着stata,妈妈再也不用担心我的stata了!详情请猛戳文章下面的视频。

一般而言,我们将网页爬取的源代码保存为文本文档(.txt),然后再导入stata进一步的整理分析,往期推文中我们也介绍了将txt文档导入stata的多种导入方式,主要有insheet、infix、import delimited命令以及fileread()函数。因为我们遇到的实际问题往往是多样且复杂的,灵活使用各种方法是很有必要的哟!贴心的爬虫酱为大家总结如下:

1、insheet: 读入以制表符(Tab分隔)或者以逗号分隔的txt文档,但不能读入同时使用两种分隔方法的数据,每一个观测值只能占一行;再者,为了节省读入数据的时间,可在insheet所在命令行后面加上选项nonames或names定义第一行是否为变量名。
2、infix:导入固定格式的文本文件,会自动删除文本文件开头的空白字符,但是infix是不能导入不是以回车符结尾的数据,并且用infix读入固定宽度的文本内容,其最长的长度为50多万个字符。
3、import delimited:往期推文用infix读入不完整?用import delimited试试吧中就介绍过命令import delimited的用法,该命令读入文本文件的时候需要编写相应的代码删除掉开头的空白字符。同时,import delimited默认是以每一个单个字符为分隔符的,若需要设置以一个字符串为分隔符,需要加上选项asstring。另外,import delimited不限制读入字符的长度,也不会出现因为文本文件的最后一行没有换行符而无法读入的现象。
4、fileread()函数:往期推文再谈源代码只有一行时如何导入也介绍了fileread()函数的用法,它可以将只有一行的且不以换行符结尾的文本文档导入stata,保证读入数据的完整性。用fileread()函数读入文本文档时,会将所有内容读入同一个单元格内,一般多用于网页源代码的读入。


今天,我们为大家介绍另一种读入外部文本文件的命令——file read。 该命令不但将文本文件导入stata,还可以将文本文件的内容放入一个局部宏中,在stata中直接调用文本信息或是提取某些关键信息。在接下来的例子中 我们就通过调用这个局部宏来直接使用数据、提取某个单词以及合并数据等。一起来看看具体介绍吧!说不定那天你就用到这个方法哟~
首先,我们生成一个文本文件temp.txt,程序如下:
clear all
cd e:\
tempname temp
file open `temp' using temp.txt, text write replace
file write `temp' "爬虫 俱乐部" _n
file write `temp' "将 爬虫进行到底" _n
file write `temp' "number one"
file close `temp'
shellout temp.txt
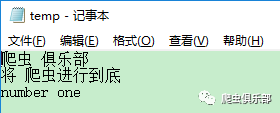
我们生成的temp.txt有3行内容,且每一行内容都不一样。现在我们用file read命令读入stata,需要说明的是,该命令一次只能读入一行内容,键入如下所示命令:
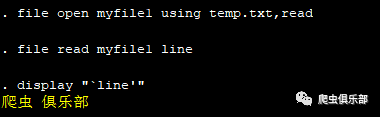
file open myfile1 using temp.txt,read
file read myfile1 line
display "`line'"
file close myfile1
结果如下所示:
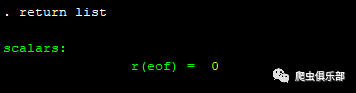
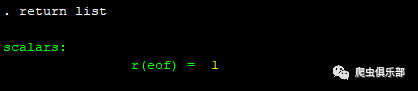
那如果我们想要读入所有内容,该怎么实现呢?其实,file read命令在读入文本文件的第一行内容后,生成了一个返回值r(eof),用于判断是否是最后一行的末尾,如果不是,r(eof)=0,否则r(eof)=1。如下所示,刚才读入temp.txt的第一行后,返回值r(eof)=0。
所以,我们可以在读入第一行命令后,对该返回值进行判断,然后继续读入剩下的内容,继续键入命令如下:
file open myfile2 using temp.txt, read
file read myfile2 line
while r(eof)==0 {
display "`=word("`line'",1)'"
file read myfile2 line
}
file close myfile2
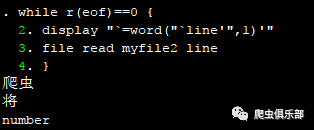
可以看到,将文本的所有行都读进来了。此时,我们看到返回值r(eof)=1
通过前面的介绍,相信大家对file read命令有了简单的认识。不过看得出,前面简单的介绍,并不能体现它的独特之处,接下来,敲黑板、划重点、放大招了哟~
假如,我们想要用file read读入某一路径下同属性的所有文件。下面我们以后缀是txt和dta格式的文件为例展开介绍。首先我们生成一些txt文件和dta文件,命令如下:
cap mkdir e:\fileread
cd e:\fileread
sysuse auto,clear
forvalue i = 1(1)5 {
drop in 1/5
outsheet using temp`i'.txt,replace
save temp`i'.dta,replace
}
我们生成了5个txt文档和5个dta文件

接下来我们想用命令file read把后缀是txt的文件导入stata。在这里,我们用到昨天推文介绍的内容,用到dos命令dir将后缀是txt格式的文件名放在一个文档filelist1.txt中。这里需要注意的是,不能将新生成的文本文件filelist1.txt放在当前的工作路径,是因为该文件名会被视为需要处理的txt文件而列入filelist1.txt中。命令如下:
cap mkdir e:\fileread\sample
! dir *.txt /a-d /b > e:\fileread\sample\filelist1.txt
shellout e:\fileread\sample\fileli
然后按照刚开始介绍的读入方式,将第一行内容放到局部宏中,接着调用这个局部宏(相当于读入第一个文件的内容),命令如下所示:
file open myfile3 using "e:\fileread\sample\filelist1.txt", read
file read myfile3 line
insheet using `line',names clear
gen id=_n
save e:\fileread\sample\mydata1.dta,replace
接下来,通过判断返回值r(eof)的大小,不断读入其他行并进行合并。命令行如下所示:
file read myfile3 line
while r(eof)==0 {
insheet using `line', clear names
gen id=_n
append using e:\fileread\sample\mydata1.dta
save e:\fileread\sample\mydata1.dta, replace
file read myfile3 line
}
为了验证数据是否读入,我们做一个简单的描述性统计:
use e:\fileread\sample\mydata1.dta,clear
sum id price mpg
file close myfile3
结果如下:
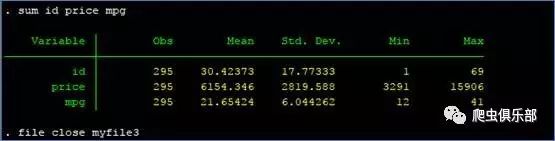
可以看到6个数据文件已经被合并。

我们也可以用相同的方法合所有dta文件。首先还是用到dos命令dir将所有的dta文件放到一个txt文档:
! dir *.dta /a-d /b >e:\fileread\filelist2.txt
shellout filelist2.txt
接下来,我们读入数据,我们先导入第一个dta 文件,并验证是否被读入:
file open myfile4 using "e:\fileread\filelist2.txt", read
file read myfile4 line
use `line',clear
sum price mpg
file close myfile4

接下来,我们合并其他行,将所有dta文件都导入stata。
clear
file open myfile5 using "e:\fileread\filelist2.txt", read
file read myfile5 line
while r(eof)==0 {
append using `line'
file read myfile5 line
}
save mydata2.dta,replace
use mydata2.dta,clear
sum price mpg
file close myfile5
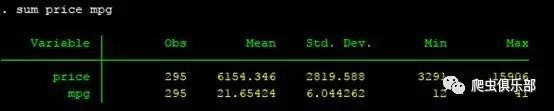
同样看到,6个dta文件已经全部合并完成。
什么?!没看懂!!不要紧!!戳下面,听爬虫小将的详细讲解,也欢迎大家的批评指正哟!

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:高金凤
技术总编:刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
7.Stata 15之Markdown——没有做不到,只有想不到!
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号