玩转Stata15之:内生性处理新命令——eregress

2017年|夏
大大大大大新闻————爬虫俱乐部新推出了视频讲解环节。小编突然浮现出一个画面——看着视频嗑着瓜子学着stata,妈妈再也不用担心我的stata了!详情请猛戳文章下面的视频。

各 位好~经常做经验研究的童鞋都知道,内生性问题几乎是研究过程中不可避免的,然而,这一问题的解决历来是一大难题。致力于服务经验研究者的Stata公司 也关注到了这方面的强大的需求,并在Stata15中增加了一个专门处理内生性问题的命令模块——Extended regression models (ERMs),包括eregress, eintreg, eprobit 以及eoprobit等命令。我们将通过一个推文系列对这一模块中涉及的命令逐个进行介绍。
一、语法介绍
在Stata15中输入help eregress命令可知,eregress主要用于处理线性回归中导致内生性的以下三种情况:内生协通过变量,非随机对照试验,以及内生样本选择问题。今天我们主要关注如何使用eregress命令处理线性模型中存在内生协变量的问题,即使用eregress命令进行工具变量回归。
eregress的基本语法如下:
eregress depvar [indepvars], endogenous(depvars_en = varlist_en) [options]
其中,depvar为被解释变量;indepvars为外生控制变量;depvars_en为内生协变量;varlist_en则包括工具变量和影响内生变量的其它控制变量。遵行工具变量法的计量原理,eregress命令会根据用户输入的变量,构建主回归方程(main)和辅助(auxiliary)回归方程,并使用最大似然法对模型进行估计。
二、案例介绍
【小 案例】:某项目欲探究学生的高中平均成绩(hsgpa)对大学平均成绩(gpa)的影响(为了使研究更加简化,忽略退学等因素的影响)。因此,这里的被解 释变量就是大学平均成绩(gpa),解释变量就是高中平均成绩(hsgpa)。考虑到家庭因素,如家庭收入(income),也可能会对学生的成绩产生影 响,也需要对其进行控制。
这里首先构造基本的OLS回归,程序如下:
clear
webuse class10
reg gpa hsgpa income
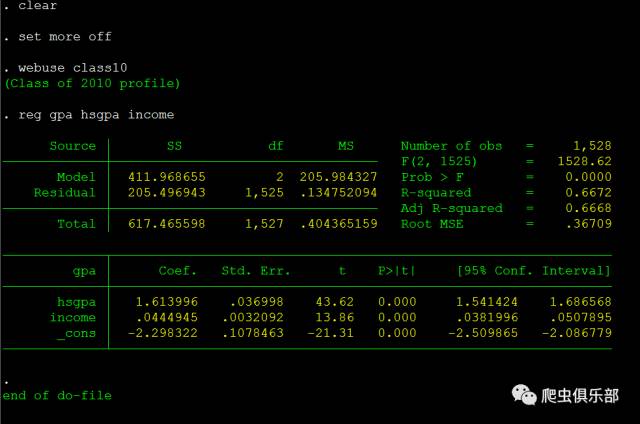
回归结果显示,hsgpa的系数为1.61,且在1%的水平上显著,表明高中平均成绩会对大学成绩产生显著影响。
然而,此处的OLS回归存在严重的内生性问题——遗漏变量。因为存在一些不可观测因素既会影响高中平均成绩(hsgpa)也会影响大学平均成绩(gpa)。比如高中成绩好的学生可能本身智商(IQ)就很高,其大学成绩好很可能是由智商导致的,而非高中平均成绩。
研 究人员通过分析认为一所高中的竞争力会影响学生的成绩,而一旦高中平均成绩(hsgpa)得到控制,高中的竞争力对大学平均成绩(gpa)的影响就可以忽 略。因此他们选择高中的排名(hscomp)作为高中GPA的工具变量(IV)。这一IV的选择符合工具变量的筛选标准,首先高中的排名是学生所不能控制 的,是独立于学生系统的外生因素,因此排除了其他因素的影响,满足外生性要求。第二是因为高中竞争力和高中生的平均成绩是(hsgpa)高度相关的,一般 情况下,排名靠前的高中,学生的成绩也更好。实际操作中,把高中竞争力(hscomp)分为低水平高中(low)、普通高中(moderate)和高水平 高中(high)。下面运用eregress命令,进行拓展的线性回归:
eregress gpa income, endogenous(hsgpa = income i.hscomp)
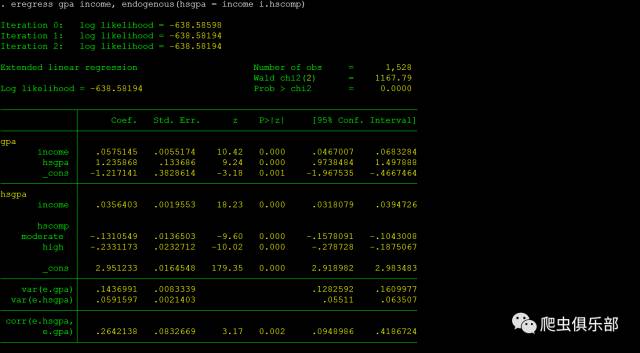
回 归结果表格的上部分,报告了主回归方程的估计结果,被解释变量为gpa;回归结果表格的下部分报告了辅助回归方程的估计结果,被解释变量为hsgpa。在 辅助回归方程中,我们通过引入外生变量hscomp作为hsgpa的工具变量,同时控制income,来控制内生性带来的影响。主回归方程的估计类似于 regress命令,根据回归结果发现高中gpa的不同会导致大学gpa存在1.24的差异。
需要注意的是,虽然eregress回归中,hsgpa的系数相较于OLS回归有所降低,但是其标准误却上升了。如果选择的IV外生性比较差,或者与内生变量之间的相关性较低(弱工具变量),eregress估计的误差也会更大。
三、eregress vs ivreg2
部分童鞋可能会好奇这里的eregress和ivreg2有什么区别呢?这里我们做一个简单的对比。首先,对比eregress,我们生成两个虚拟变量作为hsgpa的工具变量:
tab hscomp, gen(hscomp)
然后使用ivreg2进行估计:
ivreg2 gpa income (hsgpa = hscomp2 hscomp3), liml savefirst
考虑到eregress命 令使用的估计方法为最大似然估计,在使用ivreg2时我们也通过加入liml选项将估计方法设置为最大似然估计。一些文献研究发现:(1) 在大样本的情况下,liml估计量和两阶段最小二乘是渐进等价的,而在非大样本的情况下,liml估计量比两阶段最小二乘法具有更好的小样本估计性质,因 为在有限样本之中两者对工具变量赋予的权重不同;(2)在工具变量并不十分有效的情况下,尤其是在有限样本中,相对于两阶段最小二乘和广义矩估 计,liml的偏误较小。估计结果如下图:
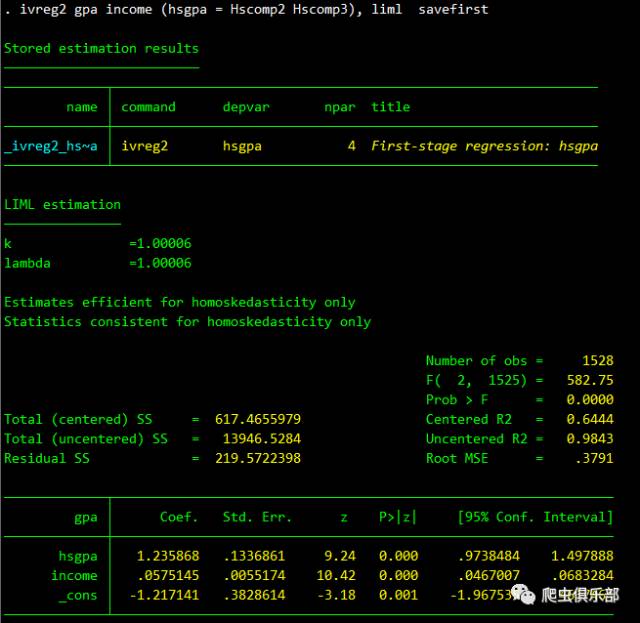
通过对比可以发现,使用ivreg2命令和eregress命令得到的估计结果是相同的。因此,eregress命令包的主要亮点可能在于将处理内生性问题的命令进行了整合,使得code写起来更加简洁。
本文旨在介绍eregress命令的相关用法,对于所选工具变量的有效性并未进行评估;关于计量上的表述错误或者技术上的错误,还请读者不吝指出。

什么?!没看懂!!不要紧!!戳下面,听爬虫小将的详细讲解,也欢迎大家的批评指正哟!

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:王 悦
技术总编:刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
7.Stata 15之Markdown——没有做不到,只有想不到!
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号