傻傻分不清:substr,usubstr,udsubstr
有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~

在推文《字符编码什么的最头疼了》中,小编已经给大家详细介绍了字节,字符,基础ASCII编码,扩展ASCII编码,unicode,utf-8,如果记不清了,可以戳进去再回顾一下。接下来小编就给大家介绍它们在字符串函数(substr,usubstr,udsubstr)中提取子字符串时的区别。

1. substr(s,n1,n2)
substr(s,n1,n2)是建立在字节的基础上,s表示某一变量或一个字符串,n1表示从s的第n1个字节开始截取,n2表示需要截取子字符串所占字节的长度。如果n1<0,表示的是从离字符串尾部的第|n1|个字节开始截取,如果n2=.,则截取的是从s的第n1个字节开始到s的最后一个字节。
举个简单的例子,键入以下程序 :
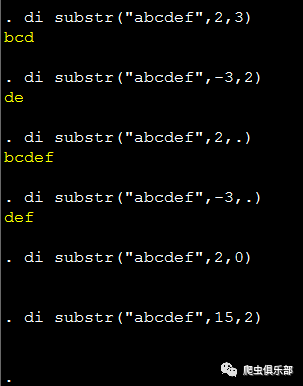
di substr("abcdef",2,3)
di substr("abcdef",-3,2)
di substr("abcdef",2,.)
di substr("abcdef",-3,.)
di substr("abcdef",2,0)
di substr("abcdef",15,2)
在stata结果输出窗口得到:
同时,在utf-8编码中,基本ASCII编码中的字符只占一个字节,扩展ASCII编码中的字符占两个字节,大部分常用汉字占三个字节,对于比较复杂的汉字(如“𠓕”)占四个字节。所以当使用substr()来截取字符串时,就得事先计算好自己需要的子字符串所占的字节个数。
举个例子,如果我们想要只截取“Aµ爬虫俱乐部”前面的 “Aµ爬”,就得计算出它们分别占了1、2、3个字节,所以该子字符串的总字节长度应为6。
di substr("A`=uchar(181)'爬虫俱乐部",1,6)

但是如果我们不小心少数了一个字节,
di substr("A`=uchar(181)'爬虫俱乐部",1,5)
就会出现如下情况:

当然,我们在使用substr(s,n1,n2)函数截取字符串时,不可能去一一手工算出某一字符串字节的长度,我们一般结合index()或者strpos()这两个函数使用,我们将会在之后的推文中介绍这些函数。
2.usubstr(s,n1,n2)
usubstr(s,n1,n2)是建立在unicode字符的基础上(因为,stata14之前版本采用的是ASCII编码,stata14及其以上版本采用的是unicode编码,因此usubstr只能在stata14 及以上版本才能使用。),s表示一个unicode字符串或者是某一变量,n1,n2表示从第n1个unicode字符开始,截取长度为n2的unicode字符,这里的长度事实上就是unicode字符的个数。
我们再使用介绍第一个命令时用的例子,截取“Aµ爬”。那么我们就可以使用usubstr()函数,从第一个unicode字符“A”开始截取3个unicode字符,即(“Aµ爬”)。
di usubstr("A`=uchar(181)'爬虫俱乐部",1,3)

3.udsubstr(s,n1,n2)
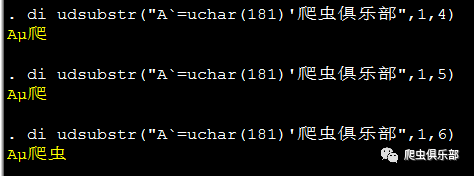
同样,udsubstr(s,n1,n2)也是建立在unicode的基础上(同样,udsubstr()也只能在stata14及以上版本中才能使用。),s表示unicode字符串或者是某一变量,n2表示的是字符串在stata结果窗口所占的空间列数,n1,n2 表示从第n1个unicode字符开始,截取占用列数为n2的字符串。基础ASCII编码与扩展ASCII码只占一列的显示空间,汉字等复杂字符占两列的 显示空间。如果n2正好位于某个复杂字符所占两列的中间时,截取的子字符串将停止在前一个完整的字符处,我们键入如下程序:
di udsubstr("A`=uchar(181)'爬虫俱乐部",1,4)
di udsubstr("A`=uchar(181)'爬虫俱乐部",1,5)
di udsubstr("A`=uchar(181)'爬虫俱乐部",1,6)
得到:
看不懂的记得戳下方视频哦~

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做 事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑:闫续文
技术总编:刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
7.Stata 15之Markdown——没有做不到,只有想不到!
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号