如何从pdf中提取表格数据
有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~
ps:喜大普奔,爬虫俱乐部的github主站正式上线了!我们的网站地址是:https://stata-club.github.io,粉丝们可以通过该网站访问过去的推文哟~
号外号外,wordconvert命令推出新功能啦!
老版本的wordconvert命令通过调用PowerShell和MS Word实现了rtf、doc、docx、dot、pdf、xps等文件的相互转换,但是pdf文件和xps文件只能由其他类型的文件转换而来,不能转换成其他类型的文件。于是,我们爬虫俱乐部更新了wordconvert命令!新版本的wordconvert命令实现了将pdf文件转换为docx、htm等其他类型的文件。 如果我们要使用这个新功能,首先需要保证电脑里面安装有Microsoft Word 2016,并且电脑里没有安装WPS。这是因为,经过测试,如果电脑里安装了WPS,常常会占用MS Word的端口,从而导致wordconvert命令无法正常使用,而且有些时候,如果电脑中安装有低版本的office或曾经安装过WPS,也可能导致 这个问题。
安装新版本的wordconvert命令只需要键入:
ssc install wordconvert, replace
要使用这个命令,需要配置PowerShell。有两个步骤:
1
将PowerShell的ExecutionPolicy设置为RemoteSigned。具体的步骤在往期推文《朝花夕拾 | 如何解决PowerShell禁止脚本运行的问题?》有详细的说明。
2
将PowerShell所在的路径添加到环境变量中。具体操作步骤在往期推文《爬虫俱乐部又出新命令了——wordconvert转换你的word文件》有详细的说明。

完成以上的步骤后就可以使用wordconvert命令将pdf文件转为其他类型的文件了。例如,我们可以使用wordconvert命令将pdf文件转换为docx文件。在这里我们将“青岛啤酒2017年第三季度报告.pdf”存放在指定路径下,然后使用wordconvert命令将其转为docx文件:
clear all
cap mkdir E:/爬虫/测试wordconvert
cd E:/爬虫/测试wordconvert
wordconvert "青岛啤酒2017年第三季度报告.pdf" "青岛啤酒2017年第三季度报告.docx", encoding(gb2312) replace

当然,这个命令更强大的地方在于能够帮我们提取pdf中的文本和表格中的数据。在这里我们以auto数据为例,说明如何从pdf文件中提取表格数据,并进行整理。主要步骤如下:我们先用putpdf命令将auto数据输出到pdf文件中,然后用wordconvert命令对这个pdf文件进行转换,最后提取出auto数据。

一、 putpdf:将auto数据输出到pdf文件中
clear all
cap mkdir E:/爬虫/测试wordconvert
cd E:/爬虫/测试wordconvert
putpdf begin
putpdf paragraph, halign(left)
sysuse auto
putpdf table table = data("_all")
putpdf save mytable.pdf, replace
这样在指定的路径下就会生成一个名为mytable的pdf文件(数据链接:https://github.com/Stata-Club/Sharing-Center-of-Stata-Club/blob/master/article/mytable.pdf),如果小伙伴们想了解更多关于putpdf命令的用法,可以参考往期推文《Putpdf--神奇的转换工具》。

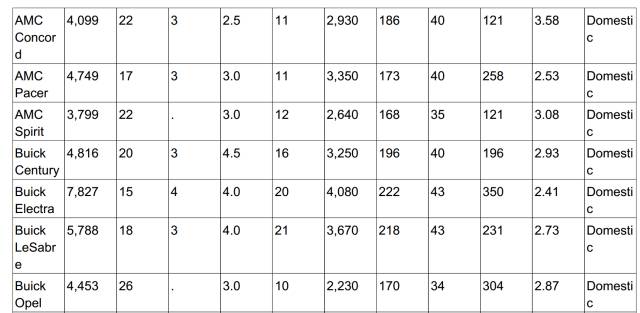
二、wordconvert:将pdf文件进行转换
最 为重要的一步来了,由于pdf、docx这一类文件无法直接被读入Stata中,因此我们需要将pdf文件转换为Stata能够读取的文本文件。但是由于 txt文件中无法输入表格,因此我们还需要将pdf、docx文件转换成一种Stata能够读取,而且可以输入表格的文件类型,即htm或者html文件。我们使用wordconvert命令将pdf文件转换成htm文件(数据链接:https://raw.githubusercontent.com/Stata-Club/Sharing-Center-of-Stata-Club/master/article/mytable.htm):
wordconvert "mytable.pdf" "mytable.htm", encoding(gb2312) replace
选项的具体用法参见往期推文《爬虫俱乐部又出新命令了——wordconvert转换你的word文件》。

三、 通过解析源代码方式提取数据
接下来的操作和我们之前做爬虫解析源代码的方法类似。首先,我们对mytable.htm文件进行转码:
clear
unicode encoding set gb2312
unicode translate mytable.htm, transutf8
unicode erasebackups, badidea
转码后,我们用import delimited读入htm文件:
import delimited using mytable.htm, encoding("utf-8") ///
clear varname(nonames) delimiter("asdfghjkl;'1234567890;lkjhgfdda", asstring)
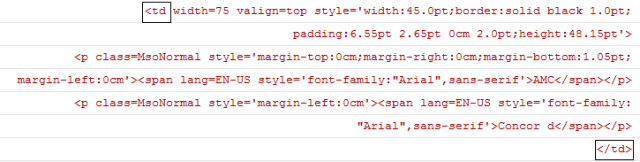
由于我们要提取的信息在一个表格中,而表格在htm文件里面是有特定标签的,<td>标签代表htm文件中表格的标准单元格。观察源代码后,我们可以发现,每一个单元格的内容实际上是出现在<td>和</td>这一对标签之间的,如下:
虽然一个单元格的内容是在这两个标签之间,但是这两个标签之间的内容却分布在多行中。所以,我们需要使用下面的循环将多行变成一行,把一个单元格的信息放在一起:
forvalues i = `=_N'(-1)2 { //从最后一行开始往前做循环
if ustrregexm(v1[`i'], "</td>$") & ! ustrregexm(v1[`i'], "^\s*?<td ") { //如果当前行结尾处出现了</td>,但是开头没有<td
replace v1 = v1 + v1[`i'] in `=`i'-1' //将当前行加到上一行
drop in `i' //删除当前行
}
}
结果如下:
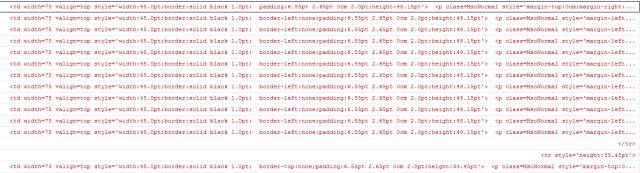
现在,含有</td>标签的行就是数据所在的行,我们将这些行保留下来就可以了:
keep if index(v1, "</td>") //保留含有标签</td>的行
接下来我们要对数据进行清洗,在htm文件中, 代表空格占位符,所以在这里我们将它删除掉,然后我们使用正则表达式将标签全部删除:
replace v1 = ustrregexra(v, " ", "") //将 替换为空
replace v1 = ustrregexra(v, "<.*?>", "") //删除<>里面的内容
处理后的数据如下所示:
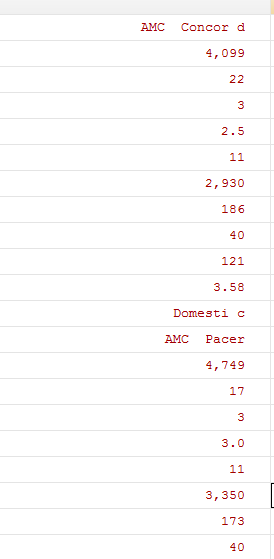
在删除了标签后,字符串开头和结尾的位置出现了很多空白字符,并且字符串中间也有多个空白字符,我们需要对这些空白字符进行替换:
replace v1 = ustrregexra(v, "^\s+|\s+$", "") //将字符串开头或结尾的空白字符替换为空
replace v1 = ustrregexra(v, "\s+", " ") //将字符串中多个空格替换为一个空格
处理后如下所示:

处理到这里,我们发现同一个单词中两个小写字母中间有空格,所以需要使用正则表达式将这些空格替换为空,程序如下:
replace v1 = ustrregexra(v, "(?<=[a-z]) (?=[a-z])","")
compress
在这里我们使用往期推文《有问必答:一列变多列》中介绍过的方法,将一列数据转换为多列数据:
forvalues i = 1/11 {
gen v`=`i'+1' = v1[_n + `i']
}
keep if mod(_n, 12) == 1
结果如下:
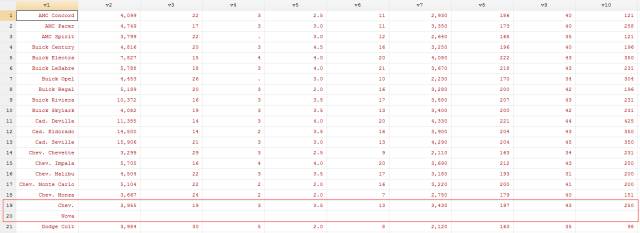

现在这个数据看起来就很整齐了。但是观察之后发现第19行和第20行的数据出现了错误,这是由于在pdf文件转为htm文件后,本该在一行的数据被分成两页:
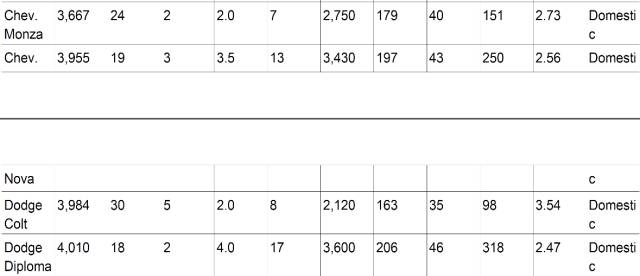
转换成htm文件之后,就会出现如下所示的情况:

因此在处理后会多一行,所以需要用以下程序进行调整:
foreach var of varlist _all {
replace `var' = `var' + " " + `var'[_n + 1] if v2[_n + 1] == "" //如果v2的某一行数据为空,就把当前行的所有数据加到上一行,并且中间加上空格
}
drop if v2 == "" //删除v2为空的那行数据
replace v12 = subinstr(v12, " ", "", .)
到这里数据的处理基本完成,接下来只需要将所有的变量由字符型转为数值型,并对最后一个变量加标签,对变量重命名,最后再调整数据格式,修改成auto数据原始的样子就大功告成了!
destring _all, replace ignore(",")
gen foreign = cond(v12 == "Foreign", 1, 0)
label define origin 1 "Foreign" 0 "Domestic"
label values foreign origin
drop v12
rename v* (make price mpg rep78 headroom trunk weight length turn displayment gear_rato)
format make %-17s //使品牌名左对齐
format price weight %8.0gc //每三位数间用逗号分开,c为comma 的意思
结果如下:
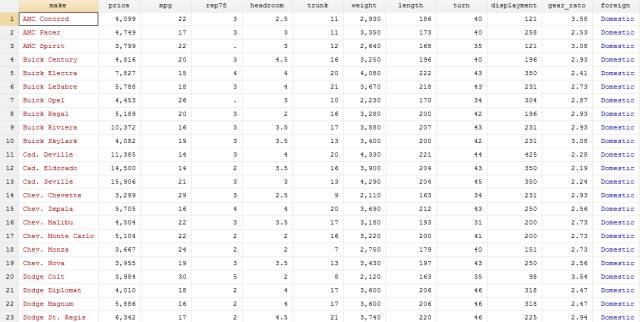
这样我们就完成了从pdf文件中提取auto数据的过程,是不是很方便快捷呢,各位小伙伴可以自己操作试一下哦!
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑/闫续文
技术总编/刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
7.Stata 15之Markdown——没有做不到,只有想不到!
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号