多对多合并
有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~
爬 虫俱乐部是一个超级优秀的团队,今年爬虫俱乐部获得重大奖励的学生有:李子健(国奖:20000),徐苾雯(国奖:20000),贝贝(鸿儒 奖:40000)以及Usman(留学基金委留学生奖学金30000)。另外还有鑫童鞋发表了金融研究的论文,由于所属学院临时改变游戏规则而遗憾未能得 到国奖,在此我们强烈谴责该学院!原童鞋的高水平论文已经被国内权威期刊接收,虽然还没有刊出,但是我们认为他更值得荣获国奖。评奖的标准应该看学术的水 平,而不是看文章是否发表!!!
ps:喜大普奔,爬虫俱乐部的github主站正式上线了!我们的网站地址是:https://stata-club.github.io,粉丝们可以通过该网站访问过去的推文哟~

我们在数据处理时,经常需要对文件进行横向合并,我们知道merge 1:1 varlist using filename [, options]可以进行一对一合并;merge 1:m varlist using filename [, options]可以进行一对多合并;merge m:1 varlist using filename [, options]可以进行多对一合并,然而在使用merge m:m varlist using filename [, options]进行多对多合并是有问题的,那么问题在哪?如何解决?这篇推文将会给大家解释清楚。
一
小试牛刀
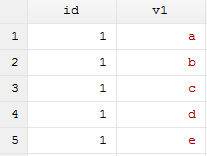
1.生成两个dta文件:
clear
input id str3 v1
1 "a"
1 "b"
1 "c"
1 "d"
1 "e"
end
save 1.dta, replace
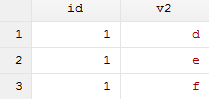
clear
input id str3 v2
1 "d"
1 "e"
1 "f"
end
save 2.dta, replace
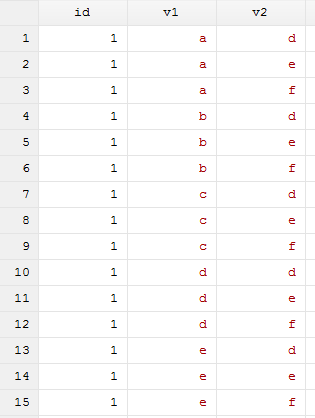
接着,我们将两个文件进行横向合并,可以看到,由于两个文件中id不是唯一识别的,属于多对多合并。我们想要得到的结果如下图所示:
2.直接用merge m:m横向合并数据
use 1.dta, clear
merge m:m id using 2.dta
drop _m
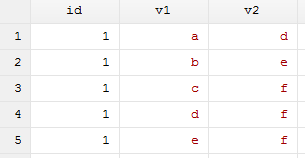
可以看到,直接使用merge m:m进行多对多合并时,第一,并不是1.dta的观测值分别对应2.dta的每一条观测值;第二,当某个文件的观测值少时,将会以该文件中的最后一条观测值对另一个文件中的观测值进行合并,如上图第4、5行。那么怎么得到我们想要的结果呢?
3.先扩展,再合并
整体思路是,把多对多合并变为一对多或多对一合并。首先,我们在1.dta中生成变量n,等于所在行行号,然后求出n的最大值,放在局部宏中,并保存为3.dta文件,程序如下:
use 1.dta, clear
bysort id: gen n = _n
sum n
local max = r(max)
save 3.dta, replace
结果如图所示:
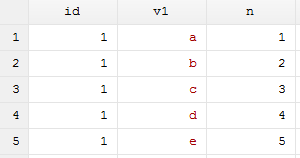
这样,把id和n两个变量作为合并依据就变成唯一的了,可以看到,n最大值为5。接着在2.dta中,对数据进行扩充相应的倍数,即1.dta中变量n的最大值:
use 2.dta,clear
expand `max'
bysort id v2 : gen n = _n
sort n v2
结果如图所示:
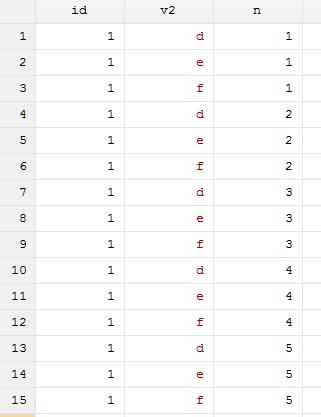
扩充后的数据,id和n作为合并依据的话,每个都为3个,所以可以与3.dta进行多对一合并,程序和结果如下:
merge m:1 id n using 3.dta
order id v1
sort id v1 v2
drop n _m
结果如图所示:
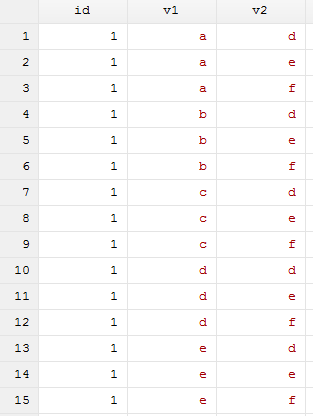
二
实例演练
我们在做事件研究时,如果某个事件发生在上市公司停牌期间,我们往往需要把其剔除掉,那么首先,我们需要按照股票代码把事件列表和停复牌时间进行横向合并,由于同一个公司可能对应多个时间,也可能多次停牌,因此应该进行多对多合并,为了方便大家操作,我们手动生成一个事件列表:
clear
set more off
input Stkcd str15 date
000001 "2006-03-01"
000001 "2007-06-05"
000001 "2007-05-05"
000001 "2010-03-01"
000001 "2013-05-06"
000002 "2003-07-25"
000002 "2009-08-16"
000002 "2010-05-09"
end
save 事件列表,replace
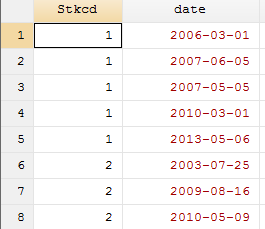
我们截取Stkcd为000001和000002公司的停复牌日期,如下图所示:
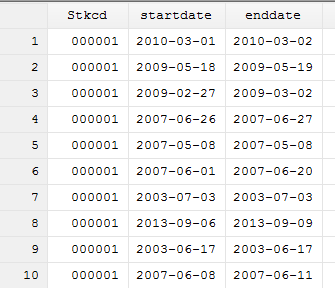
其中,startdate为停牌日期,enddate为复牌日期,合并之后,如果date,即时间发生日在停复牌时间之间,就剔除掉。
接下来,横向合并两个文件,程序如下:
use 事件列表, clear
bysort Stkcd : gen n = _n
sum n
local max = r(max)
save 事件列表1,replace
use停复牌,clear
expand `max'
bysort Stkcd startdate enddate : gen n = _n
merge m:1 Stkcd n using 事件列表1
keep if _m == 3
drop _m n
结果如图所示:
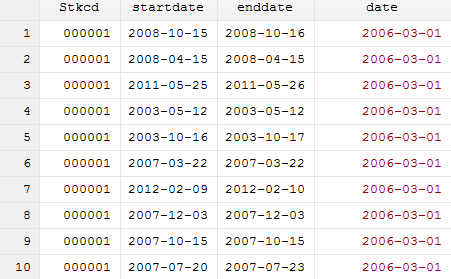
这样,每一个事件都对应所有的停复牌日期,接着将发生在停复牌的事件删除即可,程序如下:
gen date1 = date(date,"YMD")
gen num = 1 if date1 >= startdate & date1 <= enddate
keep Stkcd date num
duplicates drop
sort Stkcd date num
bysort Stkcd date :carryforward num,replace
drop if num == 1
drop num
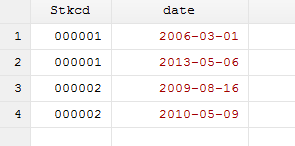
这样原来事件列表中的8个事件,在删除处于停复牌阶段的观测值后,还有4个事件,如上图所示。多对多合并,大家学会了吗?你还有其他办法实现多对多合并吗?如果有,欢迎向我们投稿呀!感谢大家对爬虫俱乐部的支持!
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑/王 悦
技术总编/刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
7.Stata 15之Markdown——没有做不到,只有想不到!
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号