rmsg-爬虫到底要花多少时间
有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~
ps:(1)喜大普奔,爬虫俱乐部的github主站正式上线了!我们的网站地址是:https://stata-club.github.io,粉丝们可以通过该网站访问过去的推文哟~
(2)爬虫俱乐部将于2018年1月20日至28日在武汉举行两期Stata编程技术定制培训。详情请戳《stata编程技术定制培训班》
对于一个码农来说,计算机的运行速度尤其重要,处理速度越快,我们工作的效率也就越高。想用自己的计算机和其他人的计算机PK一下速度吗?想知道抓取海量数据到底需要多长时间吗?今天,在这里你不需要用到秒表,rmsg命令来帮忙!
rmsg是“return message”的缩写,表示返回该命令运行时所花的时间(精确到0.01秒),同时显示命令运行完的当时时间,格式为:小时:分钟:毫秒。
rmsg的命令格式相当简单:
set rmsg {on|off} [,permanently]
在默认情况下,stata设置的是set rmsg off,即默认情况下不会显示某条命令的运行时间和运行完的当时时间。如果要设置开启,可以输入set rmsg on。
接下来我们开始进行一个小测试,以auto数据为例,画一个国产车与进口车的行驶里程与车重之间的关系。程序如下:
set rmsg on //开启设置
sysuse auto, clear
twoway (scatter mpg weight if foreign==0) ///
(scatter mpg weight if foreign==1 , msymbol(Sh)), ///
title(行驶里程与车重关系) ///
subtitle(11574年美国的国产和进口汽车) ///
ytitle(里程) xtitle(重量) ///
note(数据来自于美国汽车协会) ///
text(35 3400 "散点图") ///
legend(title(图例) label(1 国产车) label(2 进口车)) ///
scheme(s1rcolor)
我们可以在stata的结果输出窗口看到:
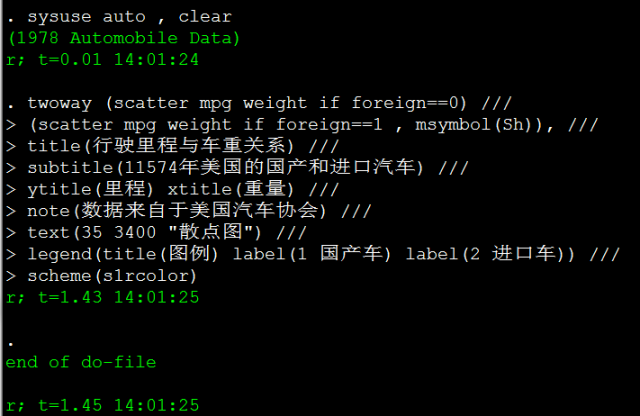
由上图我们可以看到,第一条读入auto数据的命令花了约0.01秒,而画图这条长长的命令花了约1.43秒,运行这段完整的程序一共花了1.45秒。看到这里,童鞋们是不是也蠢蠢欲动,想要测试一下自己的电脑运行这段程序到底需要几秒呢?
值得注意的是,如果仅仅输入set rmsg on,当你下次重新打开stata时,默认设置仍为off状态,只有当你输入set rmsg on, permanently时,才将默认设置的off状态真正改为on状态,即下次打开另一个stata并运行某段程序时,输出窗口仍会显示每一条程序运行时长和运行完的当时时间。
rmsg这 个命令最大的好处在于可以估算一个需要很久才能执行完的程序所需的时间,比如在爬虫的时候,有些数据有着几十万、几百万甚至几千万的数据量,抓取过程需要 很长时间,这个时候你可以通过抓取一部分的数据来估算抓取所有数据所需时间,比如说分年份抓取时,可以先抓取一年的数据,来估算抓取所有年份所需的时间。
这里有人就会问啦,计算出总的运行时间有什么用途呢?首先,你可以知道大概多长时间能完成抓取工作,方便进行下一步的研究;其次,有时反爬的设置需要我们购买代理去抓取数据,那么购买多长时间的代理就取决你程序运行的时间啦,买多了不是浪费嘛?
接下来我们就以抓取港股股票2000-2016年历史交易数据为例,来演示一下计算过程(详见推文《爬虫神器curl继续带你抓网页》)。
我们首先计算抓取股票代码为00001的历年交易数据总时间:
set rmsg on
clear
cap mkdir e:/港股数据/
cd e:/港股数据/
forvalue year = 2000(1)2016 {
forvalue season = 1(1)4 {
!curl --data "year=`year'&season=`season'" -o `year'_`season'.txt http://stock.finance.sina.com.cn/hkstock/history/00001.html
clear
set obs 1
gen v=fileread("`year'_`season'.txt")
split v,parse("</form>""</table>")
keep v3
rename v3 v
replace v= ustrregexra(v,"\s+","")
split v,parse("</tr>")
drop v v1
sxpose,clear
rename _var1 v
replace v= ustrregexra(v,"\s+|^<tr><td>|</td>$","")
split v,p("</td><td>")
drop v
rename (v1-v10)(日期 收盘价 涨跌额 涨跌幅 成交量 成交额 开盘价 最高价 最低价 振幅)
drop in -1
save `year'_`season',replace
erase `year'_`season'.txt
}
}
openall
save 00001.dta,replace
最终我们得到下图:
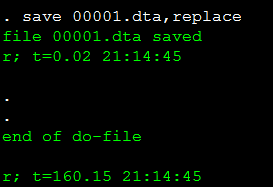
由上图我们可以知道,抓取股票代码为00001的历年交易数据所花的时间约为3分钟,那么所有的约9000个股票代码大约花费9000*3/(60*24)=18.75天。
是不是很方便呢?下一次进行海量抓取数据的时候不妨试试rmsg这个小巧的命令吧!
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!

以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑/闫续文
技术总编/刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
7.Stata 15之Markdown——没有做不到,只有想不到!
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号