我国两市融资融券历史数据

今天,是每一个中国人都不应该忘记的日子,今天与每一个中国人有关,勿忘国耻,守望和平,1213!
有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~
ps:(1)爬虫俱乐部将于2018年1月20日至28日在武汉举行两期Stata编程技术定制培训。详情请戳《爬虫俱乐部Stata编程技术定制培训班——2018年1月武汉专场》
(2)爬虫俱乐部的github主站正式上线了!我们的网站地址是:https://stata-club.github.io,粉丝们可以通过该网站访问过去的推文哟~
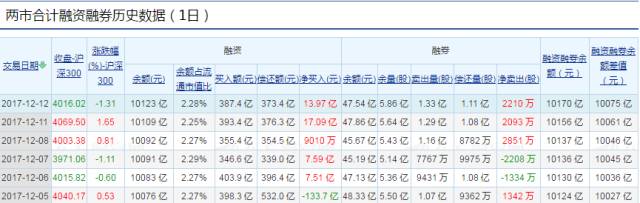
今天小编要为大家介绍一下如何获得我国两市融资融券的历史数据,我们首先在网页上找到我们需要的数据,可以在东方财富网上找到该数据,网页链接为:http://data.eastmoney.com/rzrq/total.html,数据如下图所示:
但是,在这里我们发现点击下一页按钮时,网页链接是不变的,因此我们需要找到真实的网页链接。打开网页右击检查,点击最上方的Network,再按F5键刷新网页,这时工具列表中会出现许多与网页相关的链接,如下图所示:
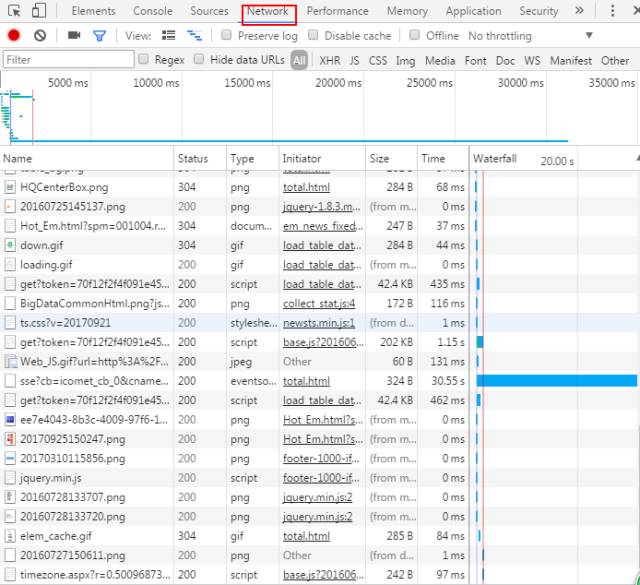
一般而言,工具列表中有一栏Status,其中显示的值为200的是正常的网页链接;同时,gif、jpeg、png等格式一般没有我们需要的信息,按照这样的筛选方式可以找到真实的网页链接。点击下一页我们可以在链接的底端找到网页对应的真实链接。如下图所示:(具体详见往期推文《一起来揪出网页真实链接!》)
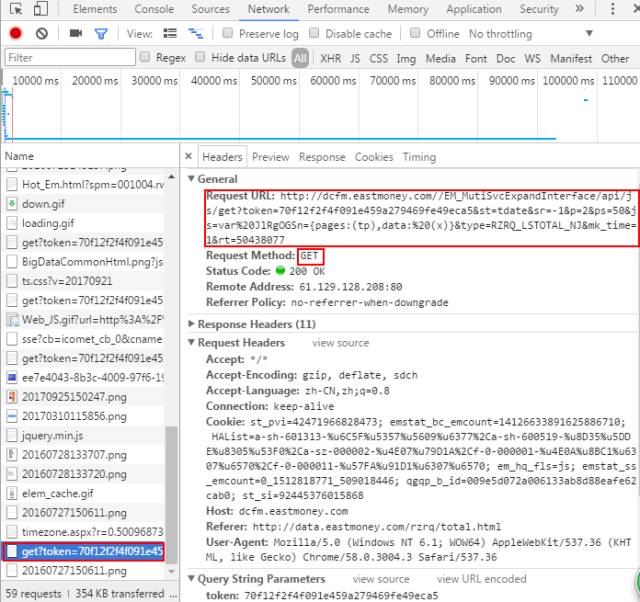
在此,我们得到其真实网页链接为:http://dcfm.eastmoney.com//EM_MutiSvcExpandInterface/api/js/get?token=70f12f2f4f091e459a279469fe49eca5&st=tdate&sr=-1&p=2&ps=50&js=var%20pfcLzjXE={pages:(tp),data:%20(x)}&type=RZRQ_LSTOTAL_NJ&mk_time=1&rt=50437988
注意到链接中p=2,代表第二页。我们为了更加快速的找到网页的真实链接,在前边操作时点击了下一页,所以在链接底部新生成的那个链接就是第二页的真实链接(如上图所示)
因此,我们可以通过更改p来获得所有页面的信息。另外网页的请求方式为GET,由于该网页的数据量比较小,抓取时间相对较短,在抓取过程服务器封IP的可能性很小,因此这里网页请求方式为GET时,我们可以不进行模拟浏览器,直接用copy进行抓取数据。
输入以下命令抓取数据:
clear
cap mkdir "E:\爬虫\东方财富-融资融券"
cd "E:\爬虫\东方财富-融资融券"
copy "http://dcfm.eastmoney.com//EM_MutiSvcExpandInterface/api/js/get?token=70f12f2f4f091e459a279469fe49eca5&st=tdate&sr=-1&p=2&ps=50&js=var%20pfcLzjXE={pages:(tp),data:%20(x)}&type=RZRQ_LSTOTAL_NJ&mk_time=1&rt=50437988" temp.txt , replace
这样我们就将网页数据放入到一个txt文件中,现在我们对数据进行处理,
输入以下命令:
clear
set obs 1
gen v = fileread("temp.txt") //使用fileread将temp.txt文件中的数据读入到v中
split v, p(`"{""')
drop v v1
sxpose, clear //将数据转置,得到数据如下:

split _var, p(",") //以,分隔开_var
drop _var1
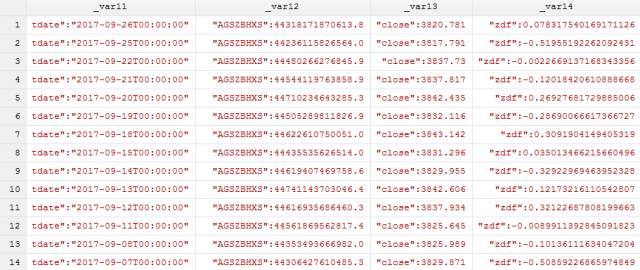
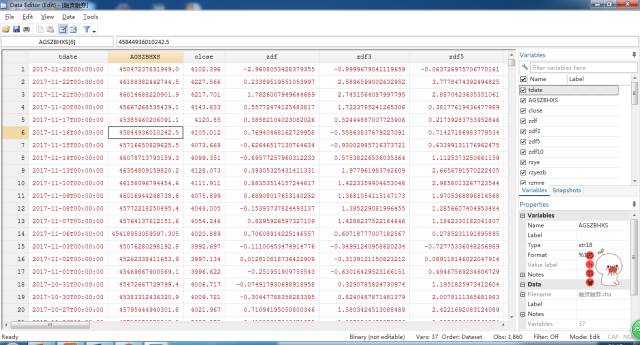
得到数据如下图所示:
注
意分割后的变量有很多个,如果分别对每一个变量进行重命名的话是十分繁琐的,这里我们可以看到,以_var11-_var14为例,对于_var11它的
变量名对应的是tdate、_var12的变量名对应为AGSZBHXS…可以发现,每一个变量的名称都是观测值中左边一个双引号(")和右边一个双引号
加冒号":之间的内容,但是同时我们发现,_var11这一列的tdate前是没有双引号的,因为我们可以通过正则表达式"*(.+?)":去匹配,其中
子表达式(.+?)即为变量的名称,然后我们可以通过ustrregexs(1)将其提取出来,并放到一个局部宏中,最后进行重命名,具体程序如下:
foreach c of varlist * {
if ustrregexm(`c',`""*(.+?)":"') local newname = ustrregexs(1)
rename `c' `newname'
replace `newname' = ustrregexra(`newname',`".+?":"*|"|\}"',"")
}
compress
save 1,replace
以上是对单个网页进行处理,下面我们介绍如何获得所有网页上的数据,我们只需对页码循环即可。
命令如下:
clear
cap mkdir "E:\爬虫\东方财富-融资融券"
cd "E:\爬虫\东方财富-融资融券\"
forvalue i = 1(1)38{
copy "http://dcfm.eastmoney.com//EM_MutiSvcExpandInterface/api/js/get?token=70f12f2f4f091e459a279469fe49eca5&st=tdate&sr=-1&p=`i'&ps=50&js=var%20pfcLzjXE={pages:(tp),data:%20(x)}&type=RZRQ_LSTOTAL_NJ&mk_time=1&rt=50437988" temp.txt , replace
clear
set obs 1
gen v = fileread("temp.txt")
split v ,p(`"{""')
drop v v1
sxpose,clear
split _var1,p(,)
drop _var1
foreach c of varlist * {
if ustrregexm(`c',`""*(.+?)":"') local newname = ustrregexs(1)
rename `c' `newname'
replace `newname' = ustrregexra(`newname',`".+?":"*|"|\}"',"")
}
compress
save `i',replace
}
通过对p=`i’进行循环,我们能够得到所有页面的数据信息,这样初步的数据处理就结束了,但是我们得到数据是38个dta文件,我们需要将数据整合在一个dta文件中,以便做进一步的数据处理,我们可以输入以下命令:
clear
fs *.dta
foreach c in `r(files)' {
append using `c'
}
duplicates drop
save 融资融券,replace
最后的数据结果如下:
注:此推文中的图片及封面(除操作部分的)均转自人民日报官方新浪微博。
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~

文字编辑/王 悦
技术总编/刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部
微信扫一扫
关注该公众号