有问必答——如何将.dat格式的文件读入stata

有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~
喜大普奔~爬虫俱乐部的github主站正式上线了!我们的网站地址是:https://stata-club.github.io,粉丝们可以通过该网站访问过去的推文哟~
近日,爬虫俱乐部的小编收到了这样一封邮件,有位老师给我们发来了整理过的世界价值观调查数据,并且附带了字典以及对数据的说明,但是这些数据都是.dat格式的,那么我们要如何把.dat格式的文件读入stata,并给这些数据加上标签呢?
一
.dat文件其实是很常见的,但是对于怎样打开这个文件大家可能还不是很了解。.dat文件并不是一种标准文件,一般的数据库软件都有将自己默认格式的数据文件转换成文本格式文件的功能,其中一种文本格式的扩展名就是.dat。这是一种纯文本文件,类似于.txt文件,没有数据属性结构方面的信息,可以用记事本、写字板、Sublime Text、UltraEdit、winhex等文本工具打开。
以1990年的世界价值观调查数据为例,让我们来瞄一瞄这些.dat文件的第一行数据(数据链接:https://raw.githubusercontent.com/Stata-Club/Sharing-Center-of-Stata-Club/master/article/WV2_Data_China_1990_stata_v_2015_04_18.dat):
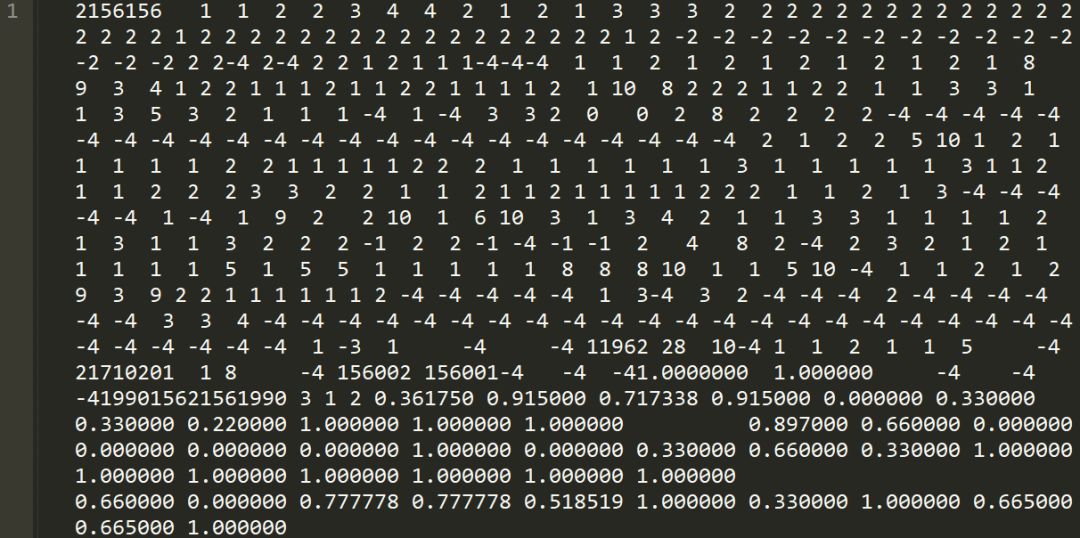
这第一行数据便是每一个变量的第一个观测值,我们打开相应的字典看一下(数据链接:https://raw.githubusercontent.com/Stata-Club/Sharing-Center-of-Stata-Club/master/article/WV2_Data_China_1990_stata_v_2015_04_18.dct):
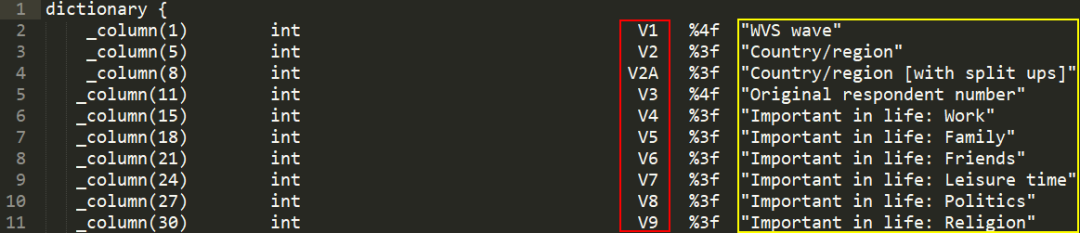
这个数据字典规 定了开始的列数、存储的类型、变量名、读取格式以及变量的标签,我们来教大家看懂这个字典。这里,用红色框起来的是变量名,用黄色框起来的是相应变量的标 签,变量名和标签中间的一列是相应的数值显示格式。现在我们来看第2行,最左边的一列显示“_column(1)”,格式一列显示“%4f”,变量名为 “v1”,标签为“WVS wave”,数值型变量存储的类型为“int”,所以第2行指的就是指定标签为“WVS wave”的变量“v1”是.dat文件中从第1列开始长度为4的数值,即下图中的“2”为v1的第一个观测值:
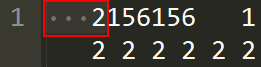
接着我们看字典的第3行,指定标签为“Country/region”的变量“v2”是.dat文件中从第5列开始长度为3的数值,即下图中的“156”为v2的第一个观测值:
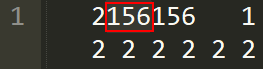
剩下的以此类推。
二
现在,我们明白了.dat文件中数据以及相应字典的含义,就可以开始读入.dat文件到stata中啦。我们在推文《infile,你这是要搞事情啊!》中介绍过可以使用infile命令读入带有字典的格式固定的文本文件,语法如下:
infile using dfilename [if] [in] [, options]
dfilename指的是我们读入文本文件要使用的字典名,如果不指定扩展名,默认即为.dct格式,但是注意这里字典的内容必须以dictionary或者infile dictionary开头,否则stata就会报错:

infile命令主要的选项有以下2个:
using(filename):括号中为要读入的文本文件名
clear:清除内存中的数据和标签名
我们发现infile命令中要使用到2个using,第一个using后接使用的字典名,而选项中的using()括号中即为要读入的文本文件名,我们首先只导入字典看一下读入的情况:
clear
cd E:\世界价值观调查\1990
infile using "WV2_Data_China_1990_stata_v_2015_04_18.dct", clear
此时,依据字典的设置,stata生成了相应的变量和标签,但是文本文件的数据并没有读进去:

接下来我们把字典和数据同时导入:
clear
cd E:\世界价值观调查\1990
infile using "WV2_Data_China_1990_stata_v_2015_04_18.dct", ///
using("WV2_Data_China_1990_stata_v_2015_04_18.dat") clear
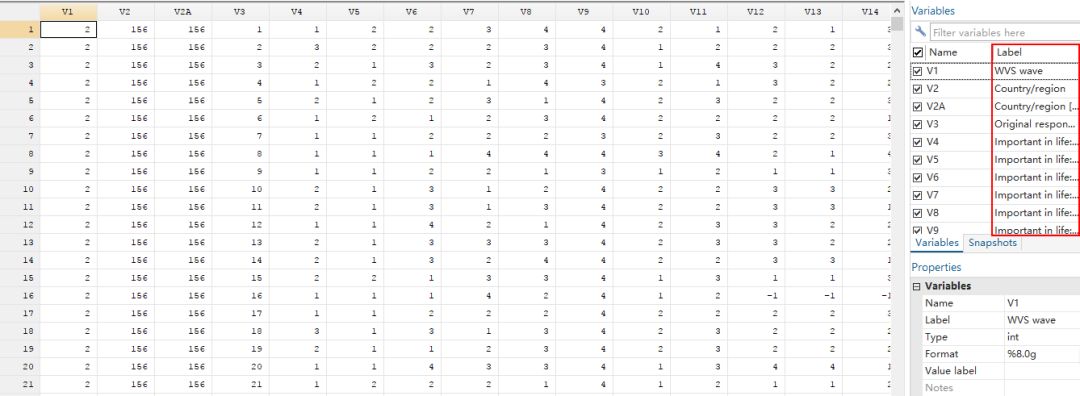
这一次我们就把这个.dat文件导入stata并根据字典为所有变量都加上了标签。

注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑/王 悦
技术总编/刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部

微信扫一扫
关注该公众号