组内交叉合并——joinby
有问题,不要怕!点击推文底部“阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~喜大普奔~爬虫俱乐部的github主站正式上线了!我们的网站地址是:https://stata-club.github.io,粉丝们可以通过该网站访问过去的推文哟~
在之前的推文《多对多合并》中,爬虫君详细介绍了在使用merge命令进行多对多合并时,遇到问题应该如何处理。整体思路是,把多对多合并变为一对多或多对一合并。今天爬虫君再介绍一种方法,即使用joinby命令,可以实现两个数据集之间的成对合并。
语法结构介绍
老规矩,先在stata中键入help joinby 查看一下它的语法:
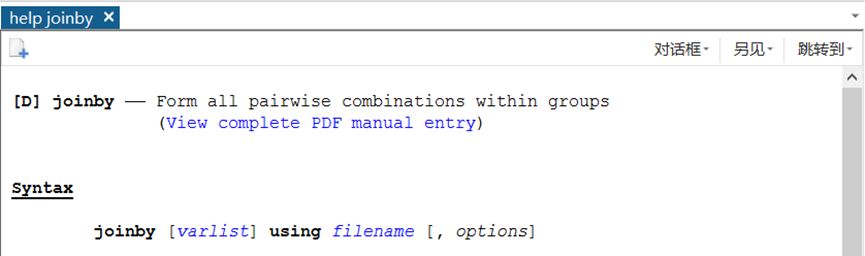
当数据集中的观测值相互匹配时,有两个选项:update和replace
(1)update:当两个数据集的观测值相匹配时,连接方式会有所不同。在默认情况下,当两个数据集中存在相同的变量时,master数据集的值将被保留。如果指定了此选项,当master数据集中的数据中含有缺失值时,合并后using数据集中的非缺失值将对其进行覆盖更新。
(2)replace:这个选项只能与update一起使用,指定master数据集中的非缺失值将被using数据集的相应值替换。但是这里需要注意的是,一个非缺失的观测值不会被一个缺失的观测值替换。
当数据集中的观测值不能相互匹配时,有三个选项:unmatched()、_merge(varname)和nolabel
(1)unmatched():指定是否要保留其中一个数据集的唯一观测值,并将其他数据集的变量设置为缺失值。其中unmatched(none)表示忽略所有不匹配的观测值(默认设置);unmatched(both)表示保留来自master数据集和using数据集的不匹配的观测值;unmatched(master)表示保留来自master数据集中不匹配的观测值;unmatched(using)表示保留来自using数据集中不匹配的观测值。
(2)_merge(varname):该选项用来显示合并结果中,观测值得来源。varname为指定的变量名称。
(3)nolabel:使用这个选项可以防止Stata从using数据集(磁盘中的数据)复制值标签到master数据集(内存中的数据)。
下面小编就用例子来具体讲解如何使用joinby来实现两个数据集之间的成对合并
1、例子一
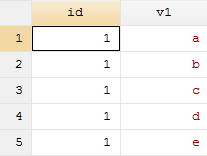
(1)首先生成两个dta文件
clear
input id str3 v1
1 "a"
1 "b"
1 "c"
1 "d"
1 "e"
end
save 1.dta, replace
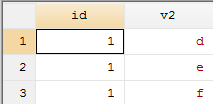
clear
input id str3 v2
1 "d"
1 "e"
1 "f"
end
save 2.dta, replace
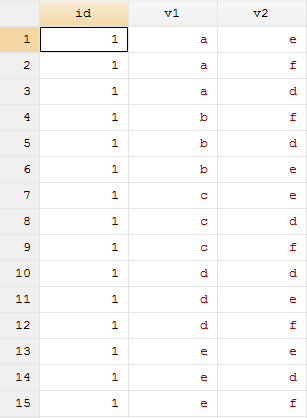
(2)合并
use 1.dta, clear
joinby id using 2.dta
合并结果如下:
看到这里小伙伴们是不是觉得很简单,只需要一个简单的小命令就可以实现很强大的功能,感兴趣的小伙伴可以赶紧试起来哦。接着小编会用另外一个例子介绍joinby的几个选项的具体用法,话不多说这就上例子啦!!
2、例子二
(1)首先生成三个dta文件
clear
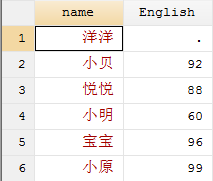
input str6 name English
"洋洋" .
"小贝" 92
"悦悦" 88
"小明" 60
"宝宝" 96
"小原" 99
end
save joinby1.dta, replace
clear
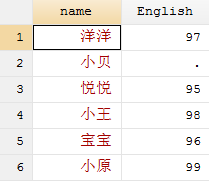
input str6 name English
"洋洋" 97
"小贝" .
"悦悦" 95
"小王" 98
"宝宝" 96
"小原" 99
end
save joinby2.dta, replace
clear
input str6 name Chinese
"静静" 96
"文文" 90
"小华" 89
end
save joinby3.dta, replace

(2)
use joinby1.dta, clear
joinby name using joinby2.dta
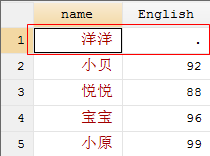
从运行结果可以看到,当master数据集与using数据集有相同的变量时(在这里是name),即数据集中的观测值可以相互匹配时,只保留匹配成功的数据,并且在默认情况下保留master数据集中的值。
(3)
use joinby1.dta, clear
joinby name using joinby2.dta, update
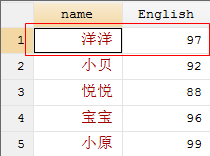
从运行结果可以看到,当使用update这个选项时,master数据集中的缺失值被using数据集中的非缺失值覆盖更新。
(4)
use joinby1.dta, clear
joinby name using joinby2.dta, update replace
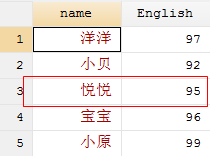
当使用update replace 这个选项时,当master数据集中含有与using数据集有冲突的非缺失值时,合并后using数据集中的数据会对其进行覆盖。
(5)
use joinby2.dta, clear
joinby name using joinby3.dta, unmatched(both) _merge(_merge) // _merge()只能与unmatched()一起使用
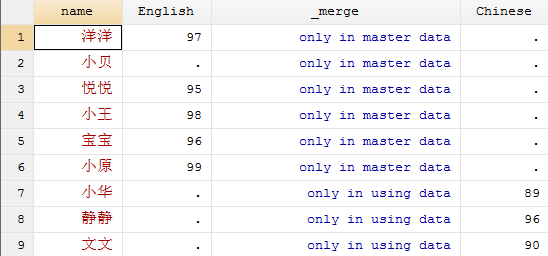
使用unmatched(both)这个选项,保留了来自master数据集和using数据集的所有匹配失败的观测值,并且制定_merge选项可以显示合并后观测值的来源。
到这里,所有关于joinby命令的选项小编已经介绍完毕,想要灵活使用,还需要私下多多练习哦。
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
文字编辑/赵宇亮
技术总编/刘贝贝
往期推文推荐:
5.爬虫俱乐部又出新命令了——wordconvert转换你的word文件
6.putdocx+wordconvert—将实证结果输出到Word(.docx)文档
7.Stata 15之Markdown——没有做不到,只有想不到!
关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿”+“推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

欢迎关注爬虫俱乐部

微信扫一扫
关注该公众号